
What to expect
This guide is for software engineers preparing for an OpenAI interview loop in 2026 — across early-career, mid, senior, and applied/product-facing roles. It walks through each stage you may encounter, what each one actually tests, concrete examples of how to answer well, and the mistakes that quietly sink candidates. The goal is to replace vague "study harder" advice with a clear map of the process and what good looks like at each step.
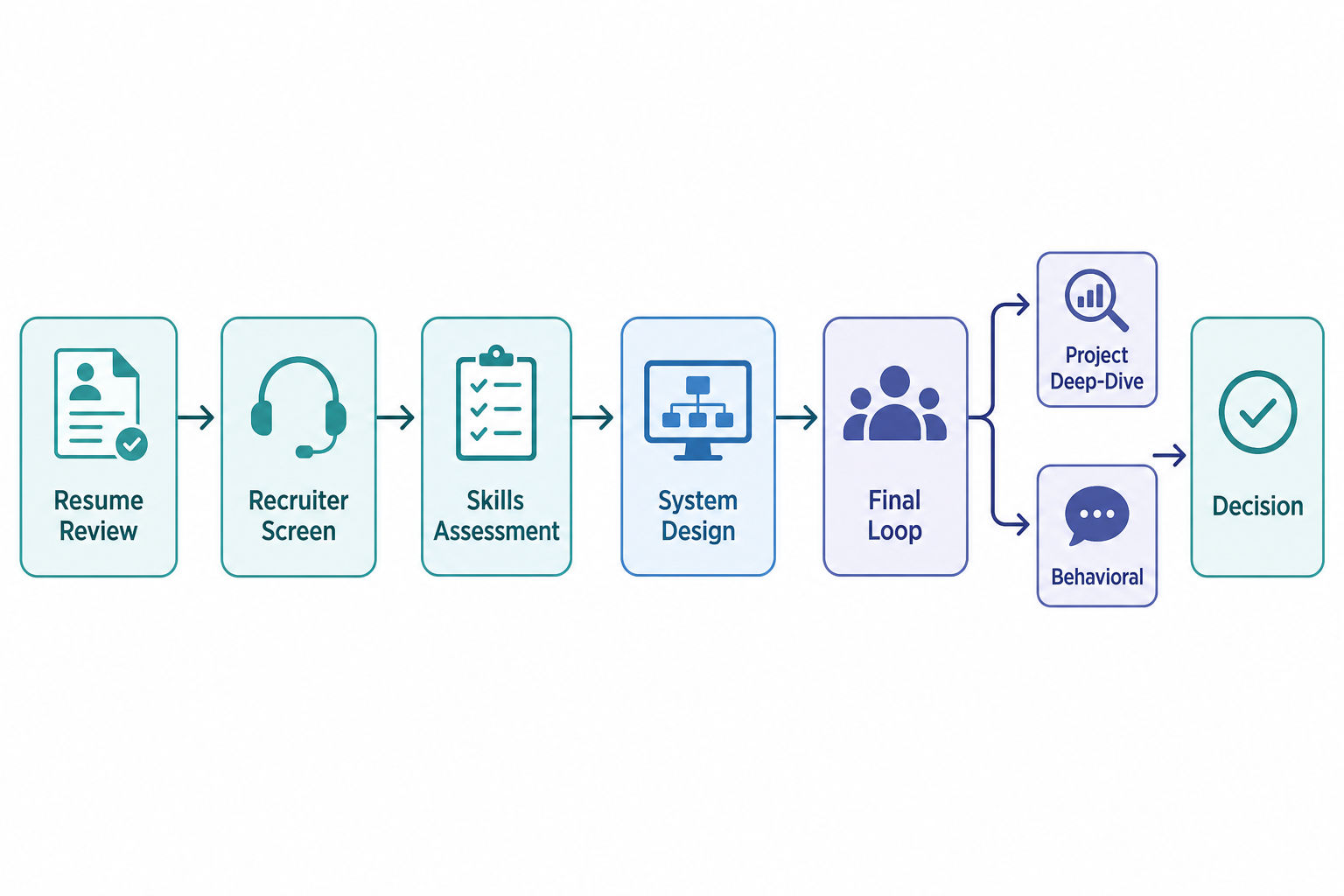
OpenAI's process is structured but team-dependent. A typical path runs from application review to an introductory call, one or more skills-based assessments, a final interview loop, and then a decision. The defining theme is practical engineering over puzzle-heavy interviewing: expect coding that resembles real work, system design grounded in production constraints, and repeated evaluation of how you handle ambiguity, safety, reliability, and user impact.
The final loop can cover a lot in a short span. OpenAI has described finals as roughly 4-6 hours with 4-6 interviewers over one or two days, virtual by default with an onsite option in San Francisco. Treat any specific number of rounds or duration as typical rather than guaranteed; the exact format, length, and timeline vary by team and scheduling.
The interview process
The stages below are common, but not every candidate sees all of them, and some are combined. Use this as a map of what can appear, not a fixed sequence.
Application and resume review
An asynchronous screen of your resume for technical impact, evidence of ownership, fast learning in unfamiliar domains, and relevance to OpenAI's product, infrastructure, or research-adjacent engineering needs. There's no live questioning here, so your projects and the scope you owned need to read clearly on paper. Lead each bullet with the outcome and your specific contribution, not the team's, and quantify where you honestly can.
Recruiter or introductory screen
A conversation (commonly 30-45 minutes, sometimes up to an hour) with a recruiter or hiring manager covering your background, why OpenAI, why this role or team, and logistics like location, hybrid expectations, and compensation. They're gauging communication, motivation, and whether your reasons for joining are specific and thoughtful. A generic "I love AI" answer is a missed opportunity here.
Skills-based assessment / technical screen
A practical technical round that varies by team, often totaling around two hours. It may be pair coding, a live exercise, an online assessment, or some combination, and some teams front-load both coding and a lighter system-design discussion. OpenAI evaluates implementation skill, code quality, correctness, testing habits, performance reasoning, and how well you turn vague requirements into something usable.
System design
For many mid-level and senior SWE roles, a dedicated system design interview appears (commonly 45-60 minutes), sometimes before finals and sometimes within the loop. It's usually a collaborative architecture discussion where you define scope, APIs, data models, scaling plans, and trade-offs. Interviewers care about scale, reliability, maintainability, latency, cost, abuse prevention, and whether the design fits the product's actual use case.
Past-project or systems presentation
A walkthrough of a system or project you genuinely owned, often a 45-60 minute session. It often works like reverse system design: the interviewer probes architecture, incidents, trade-offs, metrics, and what you'd redesign today. The aim is to distinguish real ownership from surface familiarity and to see how you reason in high-impact, ambiguous environments.
Final coding rounds
One or more coding interviews (each commonly around 60 minutes) that can go beyond standard algorithms into debugging, refactoring, code review, or implementing infrastructure-adjacent components under realistic constraints. The bar is whether you can write clean, maintainable, production-quality code while collaborating and reasoning aloud.
Behavioral, values, and mission alignment
At least one conversational round (commonly 30-60 minutes) on how you work and why OpenAI specifically. Expect questions about ownership, incident handling, cross-functional collaboration, prioritizing safety or reliability, and your views on responsible AI deployment. Mission alignment isn't confined to one round, but this is where it's probed most directly.
Team fit / hiring manager conversations
Some loops include extra discussions with a potential manager, teammates, or adjacent stakeholders to assess team-specific fit, how you work with researchers or product partners, and whether you can operate at the boundary of research and production. For applied roles, product sense and user-facing judgment can matter as much as backend depth.
Stage-by-stage summary
| Stage | Typical length | Primary signal | How to prepare |
|---|---|---|---|
| Resume review | Async | Impact, ownership, fast learning | Outcome-first bullets; clear scope |
| Recruiter screen | 30-45 min | Communication, specific motivation | A concrete "Why OpenAI / why this team" |
| Skills assessment | ~2 hrs | Code quality, correctness, testing | Pair-code in a plain editor; write tests |
| System design | 45-60 min | Trade-offs, scale, reliability | Practice API + data-model + failure modes |
| Project deep-dive | 45-60 min | Real ownership, judgment | One project you can defend end-to-end |
| Final coding | ~60 min each | Production-quality code, collaboration | Debug/refactor practice, think aloud |
| Behavioral / values | 30-60 min | Ownership, mission alignment | STAR stories; a real safety trade-off |
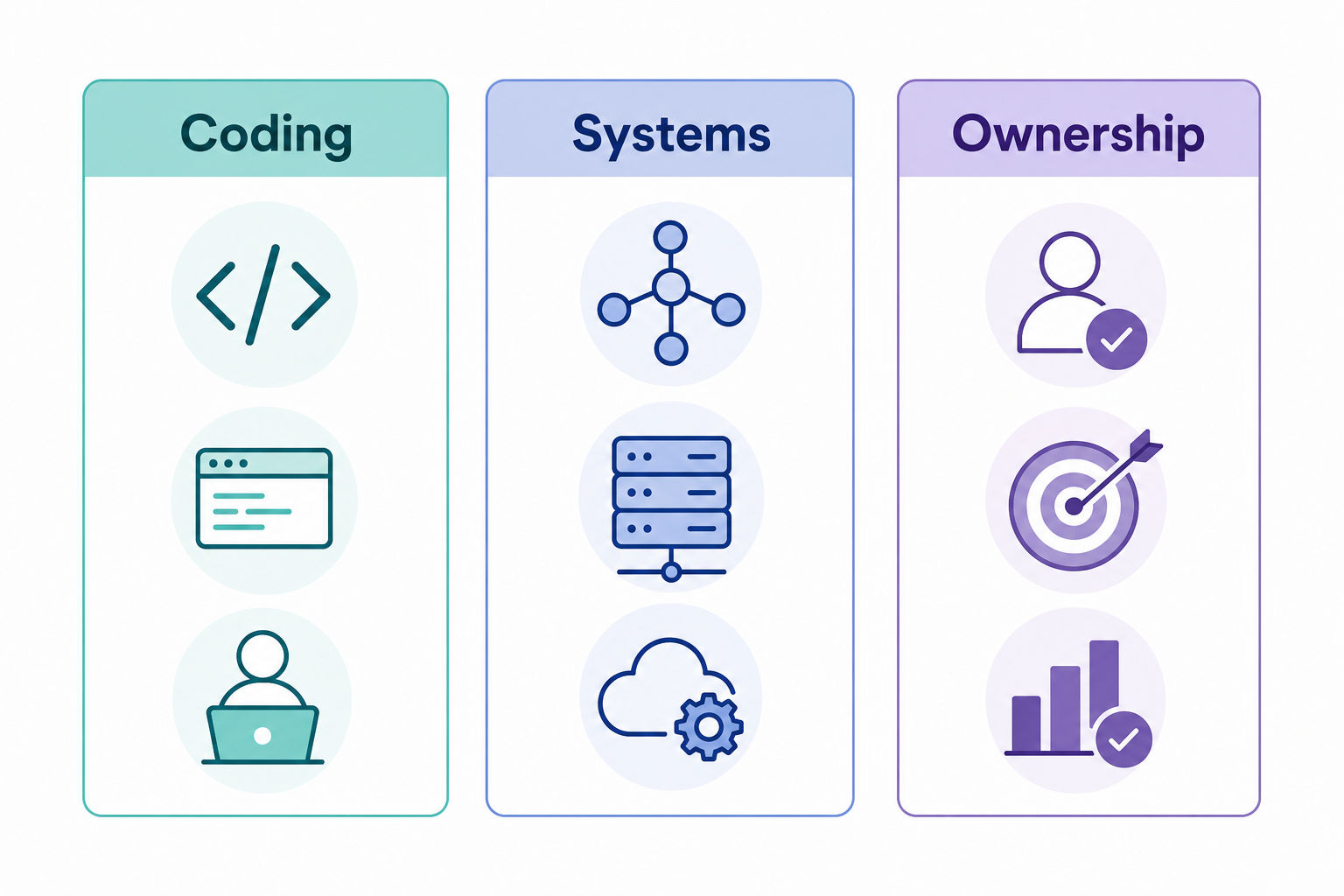
What they test
Coding. Be ready for implementation-heavy tasks using common data structures, object-oriented design, string and stateful-component logic, debugging, refactoring, testing, and complexity analysis. The key difference from a purely algorithmic process is that interviewers tend to value readable code and sensible trade-offs over the cleverest possible solution. You may be asked to improve existing code, handle edge cases, add retries and timeouts, or reason about concurrency rather than solve abstract puzzles.
Systems. Get comfortable with distributed-systems fundamentals, API and data-model design, caching, rate limiting, authentication, usage tracking, idempotency, fault tolerance, observability, and scalability under high traffic. For OpenAI specifically, system design can extend into model-serving and API-platform concerns: streaming responses, variable-latency inference, quota enforcement, batching, GPU-aware constraints, and cost-versus-latency trade-offs. Interviewers also test reasoning under ambiguity — whether you can clarify requirements, choose sensible service boundaries, define metrics, plan rollback paths, and design for abuse prevention and safe deployment rather than raw throughput alone.
Ownership and mission fit. Beyond technical skill, expect repeated evaluation of ownership, communication, and motivation. You'll need to show that you can move quickly in unfamiliar domains, work cross-functionally, and make principled decisions in small, high-talent teams. In project and behavioral rounds, expect probing on incidents, trade-offs, monitoring, reliability improvements, and moments when you prioritized safety, user trust, or long-term maintainability over short-term speed.
What good looks like in each round
It helps to know not just the topics but the behaviors interviewers reward versus penalize. The patterns below show up across coding, system design, and behavioral rounds.
| Dimension | What strong candidates do | Common pitfall |
|---|---|---|
| Requirements | Clarify scope and constraints before coding | Jump straight into a solution |
| Code quality | Readable names, small functions, error handling | Clever one-liners, no edge cases |
| Testing | Name test cases, handle empty/invalid input | "I'd add tests later" with no specifics |
| System design | State assumptions, discuss trade-offs and failure | List components with no reasoning |
| Reliability | Talk retries, timeouts, idempotency, rollback | Optimize only for the happy path |
| Communication | Think aloud, take hints gracefully | Go silent, get defensive about feedback |
| Mission fit | Specific, honest reasons tied to your work | Generic enthusiasm for AI |
Worked examples
These are illustrative examples of how to approach common moments, not real interview questions or transcripts.
Example coding moment. Suppose you're asked to implement a rate limiter for an API endpoint. A strong approach: first clarify the requirements out loud — "Is this per-user or per-IP? What's the limit and window? Should it be a fixed window or sliding? Is this single-process or distributed?" Then start with a clear, correct version (for instance, a token-bucket or sliding-window counter), name the edge cases (clock skew, concurrent requests, the first request, exceeding the limit), and only then discuss how you'd make it distributed with a shared store. Narrating those trade-offs is often worth more than a perfectly optimized solution delivered in silence.
Example system-design moment. If asked to design an API that streams model responses, a strong opening is to scope it: expected request volume, latency targets, and what "streaming" means for the client. From there you'd cover the request lifecycle (auth, quota check, queueing, inference, streamed tokens), then reliability (what happens on a dropped connection, partial response, or an overloaded backend), then cost-versus-latency knobs like batching and timeouts. Stating assumptions and failure modes explicitly signals production maturity.
Example behavioral answer (STAR). For "Tell me about a time you prioritized reliability over shipping speed":
Situation: Our team was about to launch a feature on a tight deadline. Task: I owned the rollout. Action: During canary testing I noticed an elevated error rate under load that we couldn't fully explain, so I pushed to hold the launch a few days, added monitoring and a rollback path, and root-caused a retry storm. Result: We shipped slightly late but with no incident, and the monitoring caught two later regressions before users did.
Keep it specific, honest, and centered on your own decisions and trade-offs.
How to stand out
- Prepare a specific, credible answer to "Why OpenAI?" that connects your background to safe and useful AI deployment, not just enthusiasm for the field.
- Practice coding in a plain editor and focus on production-quality implementation: clear structure, test cases, edge handling, and maintainability.
- Clarify ambiguous requirements early in every technical round instead of jumping straight to a solution. This is a strong signal here.
- In system design, explicitly discuss latency, cost, rate limits, abuse prevention, observability, rollback plans, and failure modes, not just high-level boxes and arrows.
- Pick one past project you understand end-to-end and rehearse a walkthrough covering architecture, incidents, metrics, trade-offs, and what you'd redesign now.
- Surface examples where you protected reliability or safety even when it slowed shipping, because responsible deployment reads as a positive signal.
- If you're targeting a senior or applied team, be ready to explain how you bridge research and production and collaborate with researchers, PMs, and other partners under ambiguous goals.
Practice next
The fastest way to close gaps is to practice on questions that mirror the real loop:
- Browse real OpenAI interview questions reported by candidates, across coding, system design, and behavioral rounds.
- Work through the broader software engineer interview track for role-level fundamentals.
- Drill implementation and system-design problems in the full question bank.
- Explore more company-specific walkthroughs in the interview guide library and other resources.
FAQ
How long is the OpenAI software engineer interview process?
It varies by team and scheduling, but a typical end-to-end timeline runs a few weeks from application to decision. The final loop itself is commonly described as roughly 4-6 hours, sometimes split across one or two days. Treat these as typical, not guaranteed.
Does OpenAI ask LeetCode-style algorithm questions?
Coding rounds use common data structures and complexity reasoning, but the emphasis leans toward practical, production-style tasks — implementation, debugging, refactoring, and edge cases — rather than obscure puzzles. Clean, readable, well-tested code is valued over the cleverest possible trick.
Is the interview remote or onsite?
OpenAI's interviews are virtual by default, with an onsite option in San Francisco for some candidates and teams. Logistics are usually confirmed during the recruiter screen.
How important is mission and safety alignment?
It matters and is probed directly, usually in a behavioral or values round. You don't need a manifesto, but you should be able to give specific, honest reasons OpenAI fits your goals and point to moments where you prioritized reliability, user trust, or safety over speed.
What's different about system design at OpenAI versus other companies?
The fundamentals are the same, but questions can extend into AI-platform concerns: streaming responses, variable-latency inference, quota enforcement, batching, GPU-aware constraints, and cost-versus-latency trade-offs. Reasoning about reliability and abuse prevention tends to count for a lot.
How should I prepare if I'm targeting an applied or product-facing team?
In addition to coding and systems, expect more weight on product sense, user-facing judgment, and how you collaborate with researchers and PMs under ambiguous goals. Be ready to discuss how you'd bridge research and production and make principled trade-offs when requirements aren't fully defined.