Adobe distributed media-processing job scheduling
Asked of: Software Engineer
Last updated
What's being tested
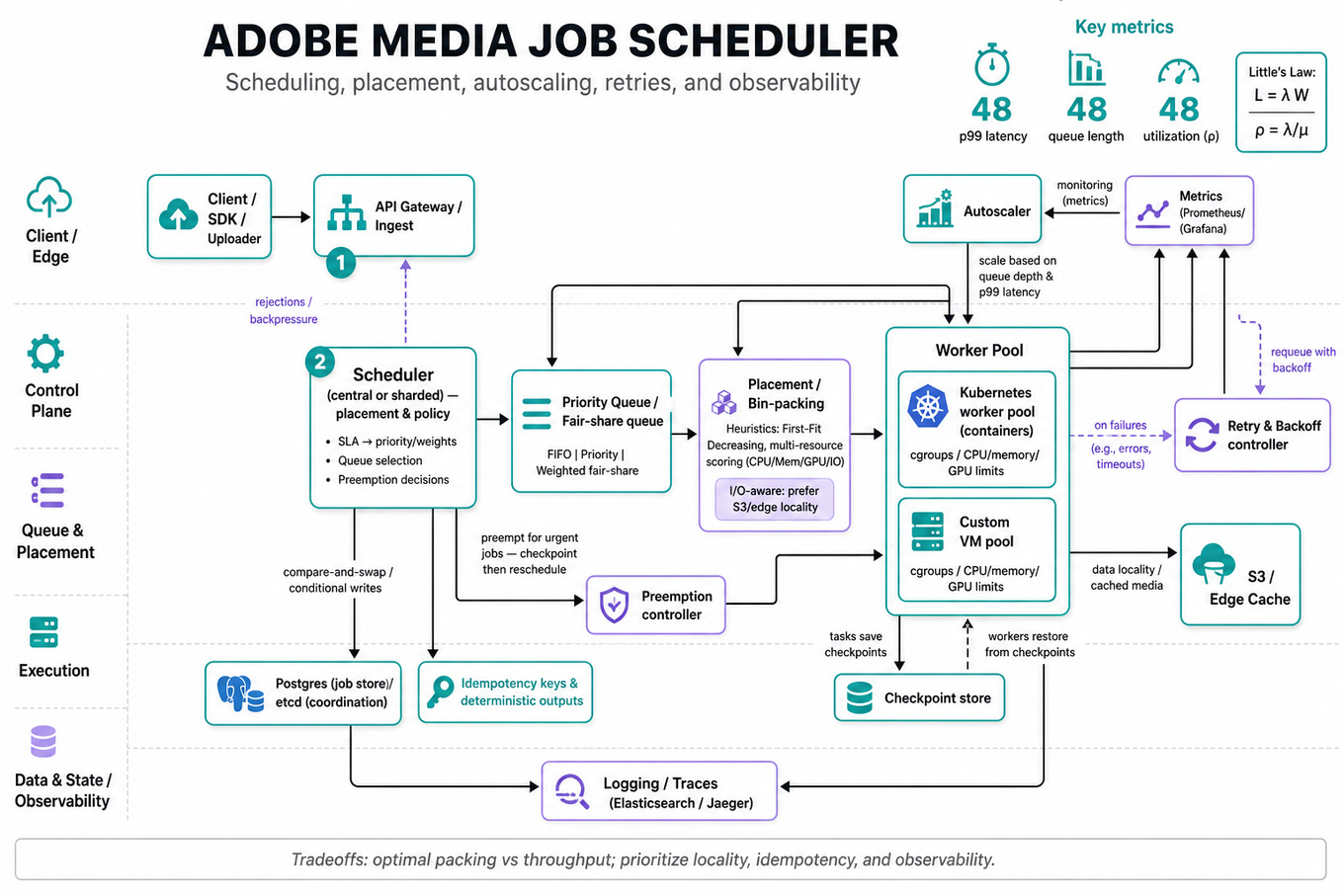
Interviewers expect you to design a robust, scalable scheduler for distributed media-processing workloads (video transcoding, image batches). They're probing your ability to (1) translate SLAs into scheduling policies and resource models, (2) choose data structures, algorithms and tradeoffs for placement/queuing, and (3) reason about failure modes, retries, and operational observability at scale. Adobe cares because media jobs are large, long-running, and multi-tenant — poor choices blow up cost, latency, and customer experience.
Core knowledge
-
Scheduler architectures: centralized (single decision-maker), federated (sharded decision layer), or fully distributed; tradeoff: centralizes optimal packing vs becomes a throughput/availability bottleneck.
-
Executor model: workers as containers/VMs managed by
`Kubernetes`or a custom pool; use cgroups/`Kubernetes`resource limits and quotas to enforce CPU/memory/GPU isolation. -
Job model & DAGs: represent multi-step media workflows as DAGs where each node is a task; store per-task metadata and allow checkpointing for long-running tasks.
-
Queuing & prioritization: implement FIFO, priority queue, or weighted fair-share; for fairness across tenants use token-bucket or weighted round-robin; track queue lengths and
`throughput`. -
Capacity & queuing theory: apply Little’s Law and utilization when sizing workers and forecasting backlog behavior.
-
Resource packing / placement: scheduling reduces to a bin packing variant (NP-hard); use heuristics like First-Fit Decreasing or greedy multi-resource scoring (CPU, memory, GPU, disk bandwidth).
-
Data locality & I/O: media jobs are often I/O-bound; minimize egress by scheduling near
`S3`/edge caches or co-locating with cached content; account for transfer time in task duration estimates. -
Faults & retries: design for at-least-once execution but enforce idempotency (idempotency keys, deterministic outputs) — avoid promising exactly-once without transactional backing.
-
State transitions & consistency: store job state in a transactional store (
`Postgres`,`etcd`) and update via compare-and-swap/conditional writes to prevent double-scheduling. -
Autoscaling & preemption: scale worker pools based on queue depth and
`p99`latency; use preemption for urgent jobs but handle rollback/checkpointing for interrupted media tasks. -
Retries and backoff: use exponential backoff with jitter, plus a
`dead-letter`queue for persistent failures; cap retry count and surface failure reasons to users. -
Observability & SLA metrics: emit
`p50`/`p95`/`p99`latencies, queue depth, worker utilization, and job success-rate; alert on stuck tasks and long-tail stragglers. -
Cost optimizations: use spot/preemptible nodes for non-urgent batches; prioritize spot usage where restart cost is small and checkpointing exists.
Worked example — "Design a scalable scheduler for distributed video transcoding"
Begin by clarifying scope: average and worst-case job duration, arrival rate, tenant isolation requirements, acceptable latency (`p99`), resource heterogeneity (GPUs), and data locations (`S3`, CDN). Organize the solution into ingestion (API + authenticated submit + idempotency key), a global queue with sharded priority tiers, and a placement layer that scores worker candidates by available CPU/GPU, cached input proximity, and current load. Include a lightweight metadata store (`Postgres` or `etcd`) holding the job state machine and use conditional updates to avoid duplicate dispatches. For long-running tasks add checkpointing so preemption or worker crash doesn't require a full restart. One explicit tradeoff: a centralized scheduler gives near-optimal packing but requires partitioning or leader-election for scale; a distributed scheduler scales better but makes global fairness harder. Close by proposing simulation-driven capacity planning and adding per-tenant quotas, admission control, and chaos-testing if time permits.
A second angle — "Guaranteeing correctness and deduplication across failures"
With the same primitives, the focus shifts to correctness: require submitters to provide idempotency keys and persist job metadata transactionally. Implement acknowledgement semantics where executors write a “started” and “finished” state using CAS; if a worker dies, the orchestrator detects stale "started" timestamps and requeues after a timeout. Use a `dead-letter` flow for persistent failure and return deterministic, signed artifacts to consumers so retries never corrupt downstream state. The tradeoff: stricter transactional guarantees increase latency and complexity; often the pragmatic approach is idempotent outputs plus at-least-once execution and strong observability.
Common pitfalls
Pitfall: Ignoring data transfer time. Treat input/output transfer as part of task duration; scheduling purely by CPU capacity will create hotspots and unexpected latency spikes.
Pitfall: Promising exactly-once without mechanisms. Saying “exactly-once” without transactional end-to-end guarantees or idempotent outputs is a product-risk answer; prefer idempotency and observability.
Pitfall: Only discussing algorithms, not SLAs. Failing to define metrics (
`p99`, throughput, SLOs) and acceptance criteria makes your design untestable — always tie choices back to measurable SLAs.
Connections
This topic commonly leads to adjacent pivots: orchestration systems like `Argo`/`Airflow` (workflow orchestration), storage/caching strategies around `S3`/CDNs for large media objects, and autoscaling/resource managers (`Kubernetes`, cluster-autoscaler, or batch engines like `YARN`). Interviewers may also pivot to cost modeling (spot instances) or security/isolation for multi-tenant workloads.
Further reading
-
Google Borg: The Predecessor to Kubernetes (paper) — how large-scale cluster managers handle scheduling and resource isolation.
-
[Designing Data-Intensive Applications by Martin Kleppmann] — in-depth on distributed consistency, fault tolerance, and storage tradeoffs, helpful for scheduler-state design.
Related concepts
- Distributed Job Scheduler SystemsSystem Design
- High-Throughput Streams, Jobs, And ObservabilitySystem Design
- Distributed Job Scheduling And Reconciliation
- Distributed Data Processing PipelinesSystem Design
- Cluster Job Scheduling And Resource Isolation
- Adobe Document Cloud real-time collaboration and offline sync