Techniques for Enabling Long-Term Memory in Multi-Turn Conversations with AI (12)
Quick Overview
This technical guide covers techniques for enabling long-term memory in multi-turn conversational agents, including eight memory strategies, retrieval mechanisms, trade-offs between completeness, relevance, latency and cost, and LangChain-based examples for implementation and scaling.
Optimizing Long-Term Memory for AI Agents in Multi-Turn Conversations
A learning-focused resource on how agents remember, forget, and retrieve context at scale
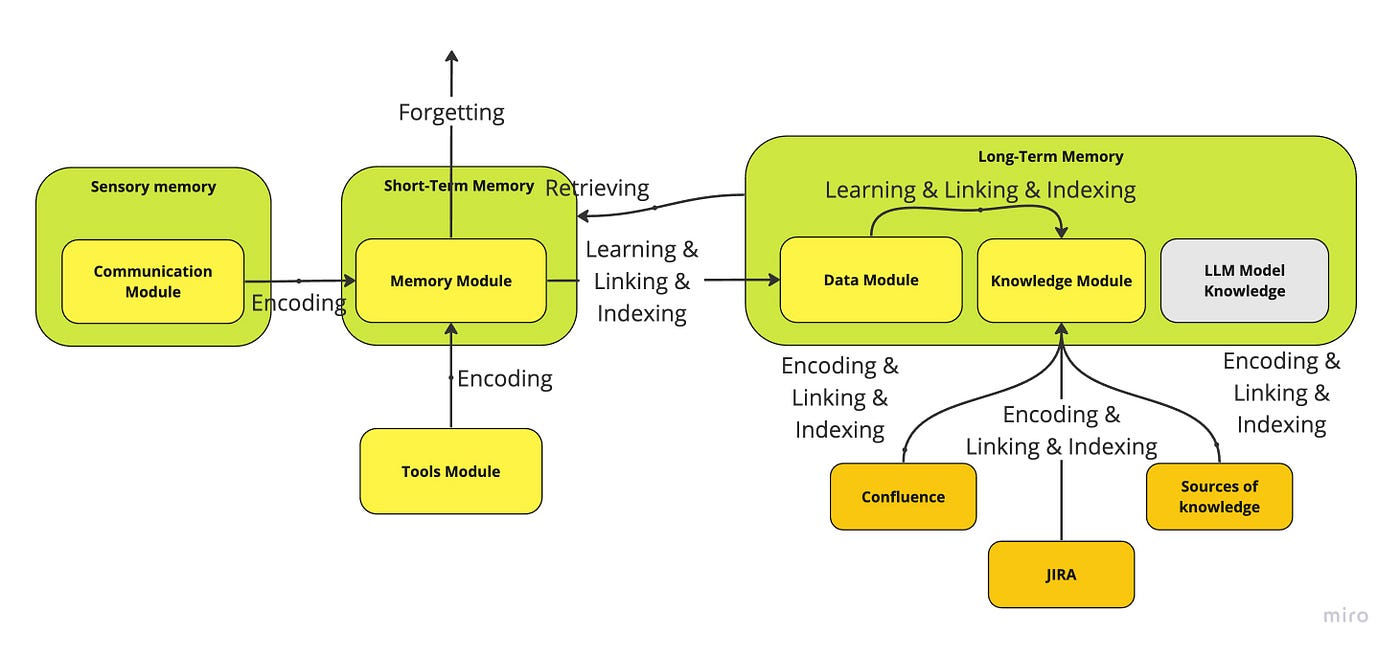
Introduction: why “memory” is the real bottleneck
In multi-turn conversations, intelligence is not limited by how well a model predicts the next token, but by what context it can still see. Large language models do not truly “remember” past interactions; they reconstruct context from whatever information is retrieved and injected into the prompt.
This is why memory is treated as a first-class component in modern agent systems. As emphasized in Lilian Weng’s work on agent design, memory determines whether an agent feels coherent over time, adapts to user intent, and avoids repeatedly asking the same questions.
This resource walks through eight practical memory strategies, using LangChain examples to show how different retrieval mechanisms solve different real-world problems.
1. How does an agent obtain context from previous conversations?
At a high level, every memory strategy answers the same question:
Which parts of the past are worth paying attention to right now?
Different strategies make different trade-offs between completeness, relevance, latency, and cost.
2. Retrieve the full conversation history
The most direct approach is to store everything and replay it every time.
In customer support scenarios, this works surprisingly well at small scale. If a user first discusses billing issues and later reports connectivity problems, having the entire dialogue allows the agent to maintain continuity and avoid asking redundant questions.
This approach maximizes coherence but scales poorly. Token usage grows linearly with conversation length, which quickly becomes impractical in long-running interactions.
Best suited for:
Short conversations, debugging sessions, early prototypes, or scenarios where continuity is more important than efficiency.
3. Sliding window over recent conversation turns
A sliding window keeps only the most recent interactions. Instead of replaying everything, the agent focuses on what just happened.
In e-commerce consultations, users often shift topics quickly: product specs → shipping → returns. Older details become less relevant, and retaining only the last one or two turns improves both speed and clarity.
This strategy trades long-term memory for responsiveness. The agent feels sharp in the moment but may forget earlier preferences unless they are restated.
Best suited for:
Task-oriented flows, transactional conversations, or situations where recency dominates relevance.
4. Entity-based memory extraction
Some conversations are not about turns, but about facts: names, roles, relationships, identifiers.
In legal or consulting scenarios, users mention entities that must persist across sessions—clients, cases, laws, aliases. Entity-based memory extracts and stores these structured facts, allowing the agent to reason consistently even if the surrounding dialogue is forgotten.
This shifts memory from “conversation replay” to knowledge accumulation.
Best suited for:
Professional services, personalized assistants, CRM-like agents, or any domain where named entities matter more than phrasing.
5. Knowledge-graph memory for relationships
Entity memory becomes far more powerful when relationships are tracked explicitly.
In medical consultations, symptoms, conditions, and patient history form a graph rather than a linear story. A knowledge-graph memory allows the agent to reason across multiple facts: conditions, aliases, temporal relationships, and inferred connections.
This enables deeper contextual reasoning, but comes with higher complexity and maintenance cost.
Best suited for:
Healthcare, technical diagnostics, research assistants, and domains with rich relational structure.
6. Stage-based summarization of conversation history
When conversations grow long, raw replay becomes impossible. Summarization compresses history into progressively higher-level representations.
In tutoring systems, this is especially effective. Rather than remembering every question, the agent remembers what the student struggles with. Each stage of the conversation updates a running summary that captures intent, gaps, and progress.
This creates a memory that is lossy but purposeful.
Best suited for:
Education, coaching, mentorship, and any setting where high-level understanding matters more than exact wording.
7. Combining recent detail with summarized history
Many real systems need both precision and context.
In technical support or incident investigation, recent error logs matter, but historical resolutions also provide valuable clues. A hybrid strategy keeps recent interactions verbatim while retaining older context as summaries.
This balances freshness and continuity, reducing token usage without discarding institutional knowledge.
Best suited for:
Long-running troubleshooting, enterprise support, and operational assistants.
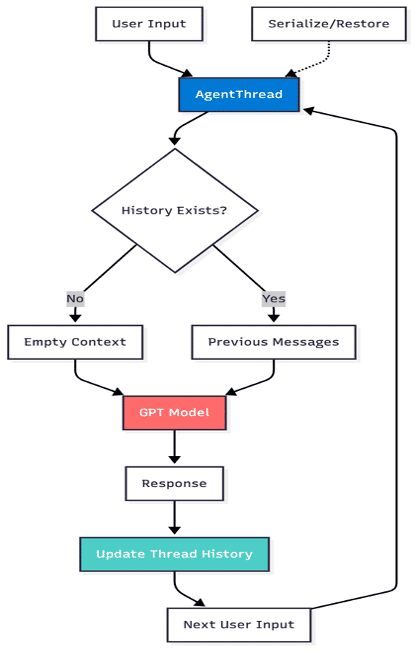
8. Prioritizing the most recent and most critical information
Not all recent information is important, and not all important information is recent.
Token-based memory strategies focus on retaining the most impactful content within a fixed budget. In financial advisory scenarios, this helps the agent prioritize key investment constraints and objectives while discarding less relevant chatter.
This reframes memory as a budget allocation problem rather than a chronological one.
Best suited for:
High-stakes decision support, finance, planning, and advisory systems.
9. Vector-based memory retrieval
Vector memory decouples recall from time entirely.
Instead of asking “what happened recently?”, the agent asks “what is most similar to the current question?”. This allows retrieval of relevant background information even if it occurred long ago.
In news analysis or research assistants, vector search enables semantic recall across large histories or document collections, far beyond what fits in a prompt.
This is the foundation of retrieval-augmented generation (RAG) applied to conversational memory.
Best suited for:
Knowledge assistants, research tools, long-term personalization, and large historical corpora.
Final synthesis: memory is an architectural choice
There is no single “best” memory strategy. Each method encodes a different belief about what matters:
- full history → coherence
- sliding window → recency
- entities → facts
- graphs → relationships
- summaries → intent
- hybrid buffers → balance
- token budgets → importance
- vectors → semantic relevance
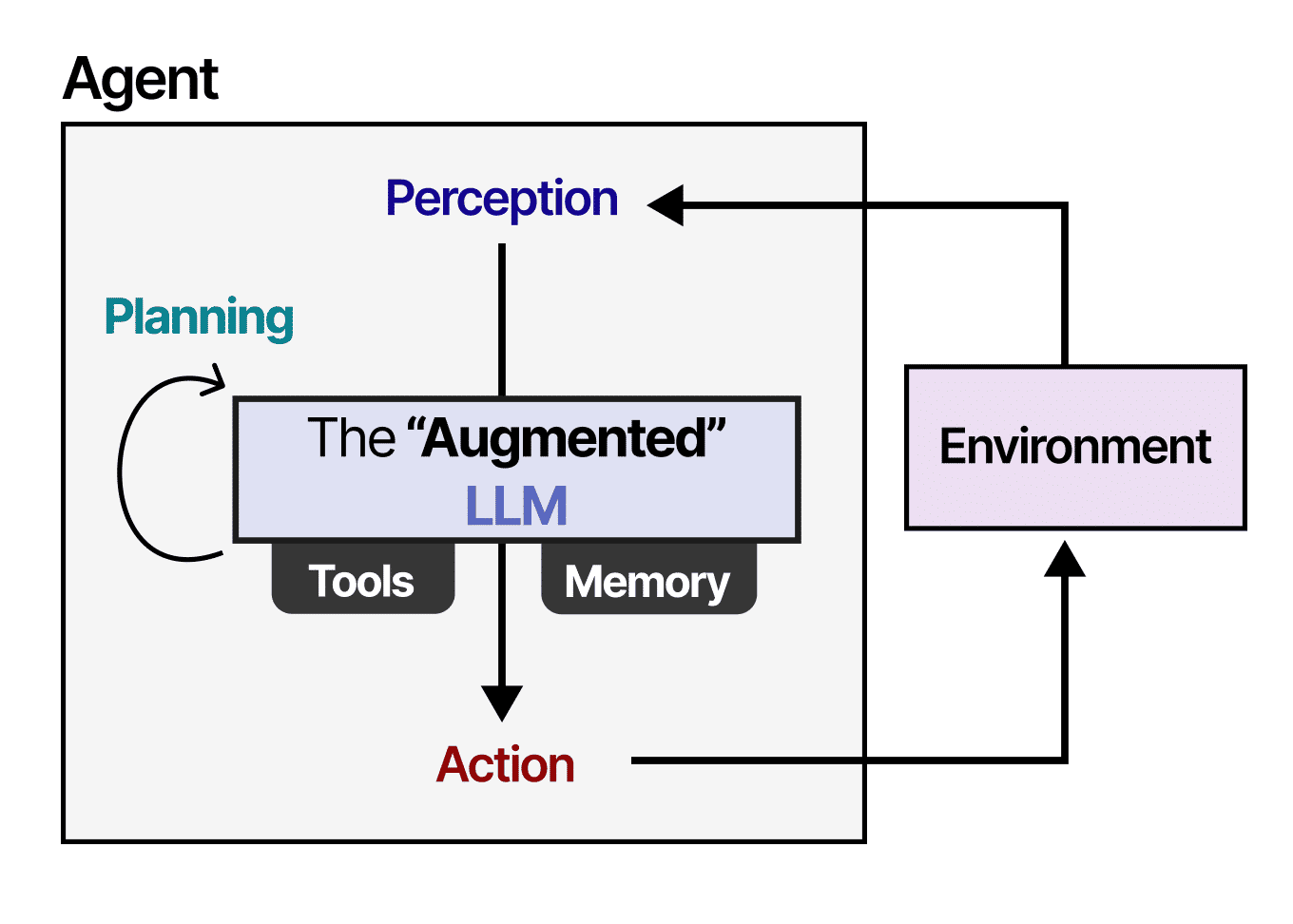
Strong agent systems combine multiple strategies, choosing retrieval methods based on task, latency constraints, and cost.
The key insight is simple but powerful:
An agent’s intelligence is bounded not by its model, but by what it chooses to remember.
Comments (0)