Large Language Models (LLMs) – Advanced Topics (8)
Quick Overview
This technical guide covers advanced LLM topics including generative modeling principles, decoding and sampling strategies, sources and types of repetition, mitigation techniques such as fine-tuning and loss design, and long-context system design and architecture considerations.

Advanced LLMs: Generation, Repetition, and Long-Context Design
A learning-focused resource for understanding how large language models generate text, why they fail, and how modern systems mitigate those failures
1. What are Generative Large Models?
Generative Large Models—most commonly large language models (LLMs)—are neural networks trained to model the probability distribution of sequences and generate new content conditioned on context. Unlike traditional task-specific models, they do not just classify or extract; they continue.
What distinguishes them is not only scale, but conditional generation. Given a prompt, the model samples from a learned distribution over possible continuations. Prompt engineering exists precisely because the model’s behavior is controlled through conditioning rather than fixed rules.
At scale, this turns language modeling into a general interface: reasoning, translation, coding, dialogue, summarization, and beyond.
2. How do large models generate diverse, non-monotonous text?
Diversity emerges from both training and inference.
From the training side, Transformer architectures with billions of parameters learn a vast space of linguistic patterns. Fine-tuning techniques such as LoRA or prompt-based tuning adapt these patterns to new domains without collapsing diversity. Loss design also matters: poorly designed objectives can cause models to favor safe, repetitive continuations.
From the inference side, decoding strategies determine how probability mass is explored. Greedy decoding collapses diversity. Sampling-based methods deliberately trade certainty for variation, allowing the model to explore alternative continuations that are still plausible.
Generation quality is therefore not a property of the model alone, but of the model–decoder system.
3. The LLM repetition problem
3.1 What is repetition?
Repetition in LLMs appears at multiple levels:
- Token-level repetition, where words or short phrases loop endlessly.
- Sentence-level repetition, where the same structure or idea is restated.
- Prompt-level repetition, where different prompts yield nearly identical outputs.
- Cross-prompt semantic repetition, where surface form changes but information content does not.
The deeper the repetition, the harder it is to fix.
3.2 Why does repetition occur?
Repetition is not a bug—it is a side effect of how autoregressive models work.
LLMs are trained to maximize next-token likelihood. Once a token sequence becomes highly probable, Softmax amplifies it. Attention mechanisms—especially induction heads—encourage copying patterns from earlier context. As repetition starts, probability mass concentrates further, creating a self-reinforcing loop.
Data bias compounds this. Frequent patterns in training data become attractors. Even massive corpora are not as diverse as they appear.
In short: high confidence + autoregression + Softmax = repetition risk.
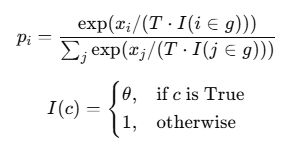
4. Mitigating repetition: training-time vs inference-time
Repetition mitigation strategies fall into two categories.
Training-time interventions
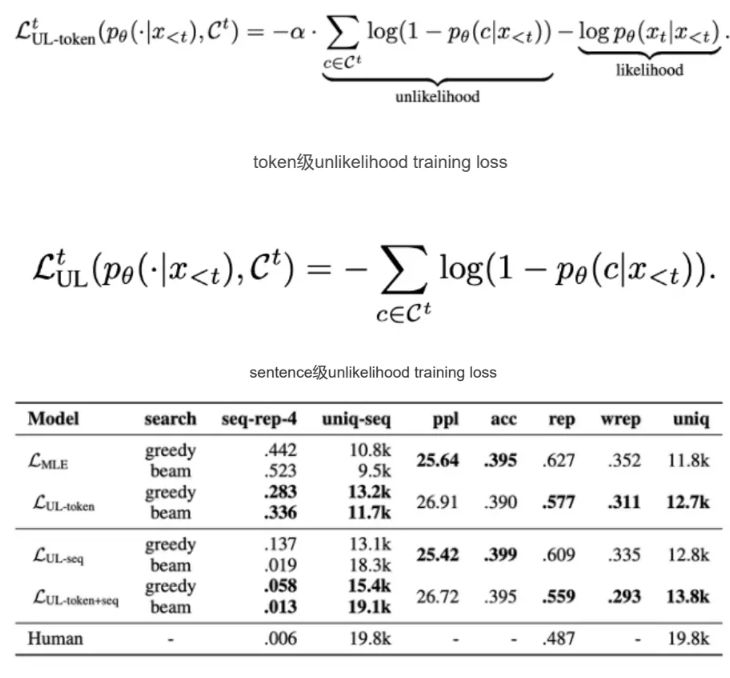
Unlikelihood Training explicitly penalizes generating tokens that have already appeared. It is effective for local repetition but difficult to scale, since defining the “negative set” is task-dependent and can hurt fluency if overused.
Contrastive training reduces similarity between token representations, making it less likely that the model collapses onto a small set of expressions. This addresses degeneration more structurally, but still cannot solve cross-prompt monotony.
Inference-time interventions
Most practical systems rely on decoding controls.
- Repetition penalty dynamically lowers the probability of previously generated tokens. It is simple, cheap, and widely used.
- Contrastive search balances model confidence against representation similarity, producing more diverse yet coherent outputs.
- Beam search explores multiple hypotheses but does not inherently prevent repetition.
- Top-K sampling restricts choices to the K most probable tokens, improving diversity at the cost of occasional awkward phrasing.
- Nucleus (Top-p) sampling adapts the candidate set based on uncertainty, generally outperforming Top-K.
- Temperature reshapes the distribution. Low temperature increases determinism (and repetition); high temperature increases diversity (and risk).
- No-repeat n-gram constraints forcibly block repeated phrases. Effective, but often unnatural.
No single method is sufficient. Robust systems combine several.
5. Monitoring, filtering, and human control
Beyond decoding, repetition can be managed through monitoring and post-processing. Metrics such as n-gram repetition rates and uniqueness scores can trigger regeneration or filtering. Rule-based or similarity-based post-processing removes redundant content.
For high-stakes domains, human-in-the-loop control remains essential. Automation reduces cost; humans preserve correctness and safety.
6. LLaMA-series issues and context length
Can input length grow arbitrarily?
In theory, RoPE-based models can extrapolate to longer contexts. In practice, they face hard limits:
- Attention cost grows quadratically.
- Long sequences strain memory and latency.
- Modeling long-range dependencies remains difficult.
Chunking, architectural optimization, and inference tricks help—but do not eliminate the trade-off.
7. When to use BERT vs LLaMA / ChatGLM
This is not about “old vs new,” but fit for purpose.
BERT-style encoders are efficient, cheap, and excellent for NLU tasks such as classification, extraction, and matching. They dominate when generation is unnecessary.
LLaMA- or ChatGLM-style models are generative, flexible, and powerful—but expensive. They shine in open-ended generation, reasoning, and dialogue.
Using a large generative model where a small encoder suffices is usually wasteful.
8. Do industries need dedicated LLMs?
In most cases, yes.
Different domains encode knowledge, terminology, style, and constraints differently. Medicine, law, finance, and engineering all demand precision that general models struggle to guarantee.
A common pattern is general foundation + domain adaptation. Shared language understanding is reused; domain expertise is injected through fine-tuning, adapters, or retrieval.
This balances performance with cost.
9. Extending LLM context length
The core bottleneck is attention complexity.
Practical approaches include position scaling (as in LongChat), fine-tuning on long conversations, and architectural tricks such as sparse attention, Mixture of Experts, and Multi-Query Attention.
The long-term direction is clearer: linear or near-linear attention. Models like RWKV suggest a return to recurrent-style information propagation, modernized with Transformer insights.
Transformers replaced RNNs—but efficiency pressures may bring recurrence back in a new form.
Summary
Large language models are not just bigger models—they are probabilistic generators with fragile dynamics.
Repetition, context limits, and cost are not accidental problems; they arise naturally from autoregressive generation and quadratic attention. Effective systems accept this and layer solutions across training, decoding, monitoring, and architecture.
The real skill is not knowing every technique, but understanding where each lever acts—and when pulling it helps or hurts.
Comments (0)