GenAI & LLM System Design Interview Guide (2026)
Quick Overview
This guide covers GenAI and LLM system design topics including architecting Retrieval-Augmented Generation (RAG) pipelines, trade-offs among embedding latency, retrieval accuracy, and LLM token cost, mitigation of hallucinations, scaling semantic retrieval, and cost and latency optimization techniques.
To pass a GenAI System Design interview in 2026, you need to confidently architect a Retrieval-Augmented Generation (RAG) pipeline and reason out loud about the trade-offs between embedding latency, retrieval accuracy, and LLM token cost. This guide is for software and ML engineers preparing for AI-infrastructure rounds at companies like OpenAI, Anthropic, Google DeepMind, and Meta AI. It walks through how a GenAI design round differs from a classic backend round, a stage-by-stage framework for designing an enterprise RAG system, the cost and latency trade-offs that separate senior candidates, and a scoring rubric so you know what "good" sounds like out loud.
Standard system design rounds test load balancers, caching, and relational database sharding. GenAI rounds add a new dimension: designing around non-deterministic outputs. The same input can produce a different answer twice, so interviewers want to see whether you can build infrastructure that mitigates hallucinations, scales semantic retrieval, and keeps inference costs under control.
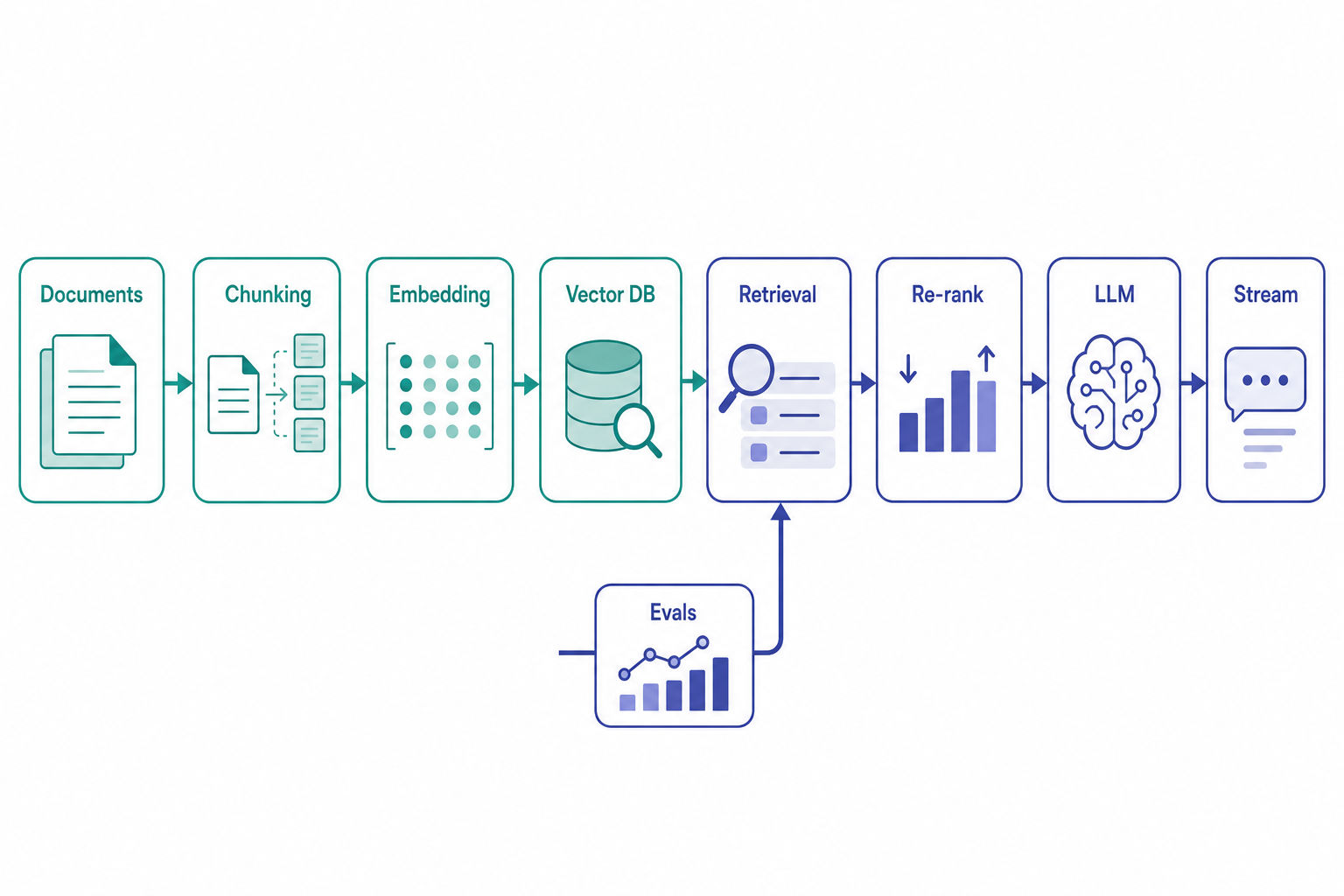
Table of Contents
- Traditional vs. GenAI System Design
- How to Architect a RAG Pipeline
- Key Trade-Offs: Cost vs. Latency
- Observability and Hallucination Mitigation
- What Interviewers Score You On
- Frequently Asked Questions
Traditional vs. GenAI System Design
Before you draw a single box on the whiteboard, anchor yourself in the paradigm shift. You are no longer designing a highly consistent CRUD application; you are designing a probabilistic data flow where the same input can produce different outputs.
| Concept | Traditional System Design | GenAI System Design |
|---|---|---|
| Data Storage | Relational databases (e.g., PostgreSQL) | Vector databases (e.g., Pinecone, Weaviate, pgvector) |
| Search Paradigm | Exact match / keyword indexing | Semantic search / cosine similarity |
| Primary Bottleneck | Database I/O and network latency | GPU availability and token generation speed |
| Unit of Cost | Storage + request volume | Tokens in + tokens out, per call |
| Testing & Quality | Unit tests (deterministic) | Evals, LLM-as-a-judge, groundedness checks |
The most important row is the last one. In a traditional system, "correct" is a fixed value you can assert against. In a GenAI system, "correct" is a quality judgment, so your design has to include a way to measure output quality, not just return it. Candidates who skip this and treat the LLM as a deterministic function tend to lose the room early.
How to Architect a RAG Pipeline
A recurring prompt in GenAI interview loops is some version of: "Design a conversational AI agent for our enterprise knowledge base." A strong answer walks through a RAG pipeline stage by stage, from raw documents to a streamed response, naming the trade-off at each stage rather than just listing components.
Step 1: Document Ingestion & Chunking
You cannot feed a 500-page PDF directly into an LLM, so the pipeline starts with how you break documents down.
- Parsing strategy: Explain how you extract clean text from messy sources - PDFs, slide decks, HTML, tables - and how you handle layout-heavy documents where naive extraction scrambles the content (multi-column PDFs and tables are the classic failure cases).
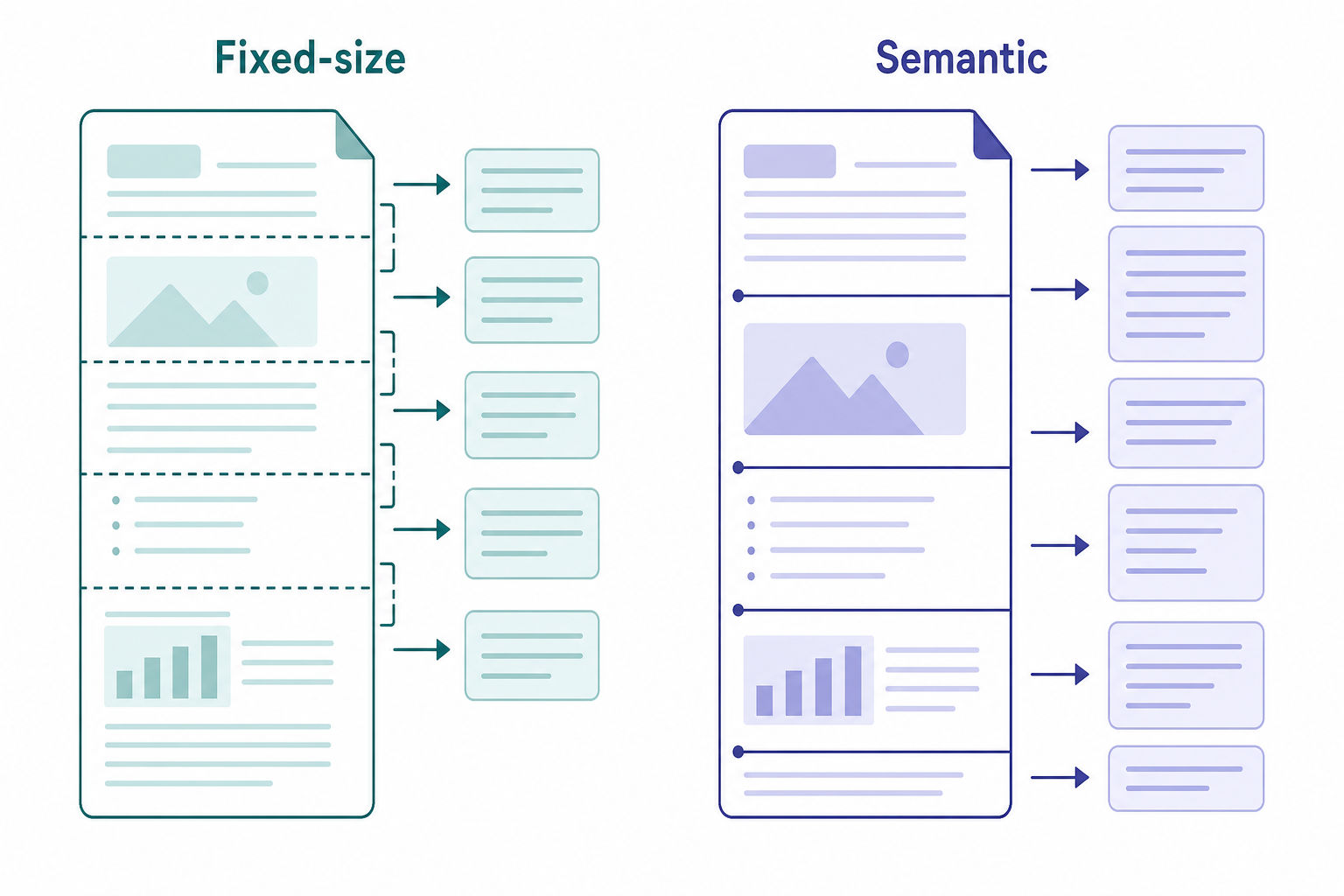
- Chunking strategy: Decide between fixed-size chunking (e.g., ~500 tokens with overlap) and semantic chunking (splitting at logical paragraph or section boundaries). Note the trade-off out loud: semantic chunking preserves context better but costs more to compute, while fixed-size chunking is cheap and predictable but can sever ideas mid-thought.
- Metadata at ingest: Capture source, document date, author, and access level now, while you have the original document. You will need it later for filtering and access control, and backfilling it is painful.
Step 2: The Embedding Layer
Each chunk is then converted into a numerical vector that captures its meaning.
- Name a concrete embedding model - for example, a hosted option like OpenAI's
text-embedding-3-large, or an open-source model such asBGEto cut cost and keep data in-house. Mention the trade-off: hosted models are convenient but send your data out and bill per token; self-hosted models are cheaper at volume but you own the GPUs and the ops. - Store the resulting vectors in a vector database alongside the metadata you captured at ingest. That metadata is what lets you do hybrid search - combining semantic similarity with keyword and attribute filtering - and enforce per-user access control at retrieval time so a user never gets a chunk they aren't allowed to see.
Step 3: Retrieval & Re-ranking
When a user asks a question, you embed the query the same way and search for the closest chunks.
- Vector search: Use cosine similarity (or another distance metric) to pull the top N candidate chunks - say, the top 50. This stage is fast but noisy: it optimizes for vector closeness, not actual answer relevance.
- The senior maneuver - re-ranking: Add a cross-encoder re-ranker (such as Cohere Rerank) as a second stage to narrow those 50 candidates down to the ~5 most relevant chunks before they reach the expensive generation step. This two-stage retrieve-then-rerank pattern dramatically improves precision and keeps your prompt small, which also cuts token cost.
Step 4: Generation & Prompt Orchestration
Finally, the retrieved chunks are assembled into an augmented prompt and sent to the LLM.
- Describe your orchestration layer - a framework like LangChain or LlamaIndex, or a thin custom layer - and what it actually does: assembling context, managing the system prompt, and routing multi-step or agentic flows. Be ready to explain the mechanics, not just name the framework.
- Explain how you stream the output back via Server-Sent Events (SSE) or WebSockets so the user sees the first tokens almost immediately instead of staring at a spinner for several seconds.
To see how these stages show up in real loops, browse the GenAI and infrastructure questions in the PracHub question bank and the company-specific sets for OpenAI and the Machine Learning Engineer track.
Key Trade-Offs: Cost vs. Latency
A senior candidate stands out in the final stretch of the interview by leading the trade-off discussion instead of waiting to be prompted. Two trade-offs come up almost every time.
1. Inference Cost
LLMs bill per token, so a good architecture treats tokens as a budget. The lever to mention is semantic caching: when a new query is close enough to a recent one (measured by embedding similarity, with a tunable threshold), a cache layer returns the prior answer and skips the LLM call entirely. Be precise here - semantic caching matches questions that mean the same thing, not just byte-for-byte identical strings, which is what makes it more powerful (and riskier) than a plain key-value cache. Set the threshold too loose and you serve a stale answer to a subtly different question. Pair caching with model routing: send cheap, simple queries to a small model and reserve the large model for hard ones.
2. Time-To-First-Token (TTFT)
Users tolerate a slow total response far better than a slow start. Explain how your design exploits the gap between retrieval latency (fast) and generation latency (slow): once retrieval finishes, you start streaming tokens as they are produced, so perceived latency tracks TTFT rather than total completion time. Mention prefetching or parallelizing retrieval to shave the time before generation can even begin.
The summary you should be able to recite under pressure: shrink the prompt to cut cost, stream the output to cut perceived latency, and cache aggressively to do both.
Observability and Hallucination Mitigation
The single biggest blocker for enterprise AI is hallucination. If you do not proactively address how your architecture keeps the LLM grounded in retrieved facts, a strong interviewer will keep pushing until you do.
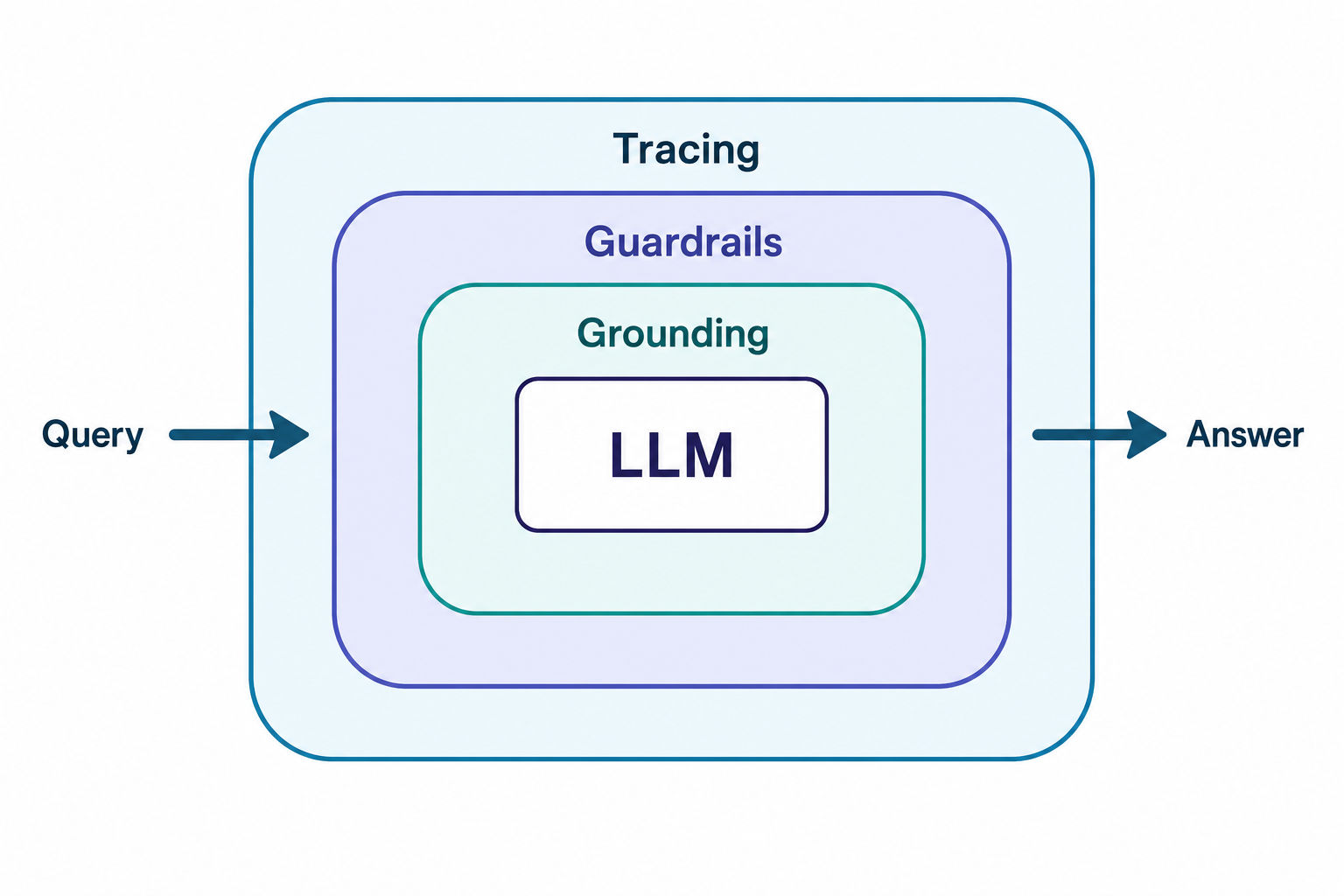
Frame your answer as a multi-layered LLMOps pipeline:
- Grounding and evaluation: Use evals and groundedness checks (including LLM-as-a-judge) to verify that responses are supported by the retrieved chunks rather than invented. A citation step that links each claim back to a source chunk is a strong signal - it makes the answer auditable and gives users a reason to trust it.
- Guardrails: Add input/output guarding that scans prompts and responses for PII leakage, prompt injection, and toxic content before anything reaches the user. Prompt injection in particular is worth a sentence: untrusted documents in your knowledge base can carry instructions, so treat retrieved text as data, not commands.
- Traceability: Log every stage of the flow - prompt → retrieval → re-rank → generation - with a tracing tool like LangSmith. When a user thumbs-down an answer, the trace tells you exactly which retrieved chunk corrupted the output, so you can fix the retrieval layer instead of guessing.
What Interviewers Score You On
Most candidates lose points not by getting an answer wrong but by staying at the wrong altitude - either reciting component names with no trade-offs, or diving into one stage and never zooming back out. Use this rubric to self-check before your loop.
| Signal | Weak answer | Strong (senior) answer |
|---|---|---|
| Framing | Jumps straight to boxes | States it's a probabilistic system and clarifies requirements (latency budget, data sensitivity, scale) first |
| Retrieval depth | "Embed and search the vector DB" | Two-stage retrieve-then-rerank, names hybrid search and the chunking trade-off |
| Cost awareness | Never mentions tokens | Treats tokens as a budget; raises caching, model routing, prompt shrinking unprompted |
| Quality / safety | Treats LLM output as final | Adds evals, citations, guardrails, and a feedback loop to improve retrieval |
| Trade-off leadership | Answers only what's asked | Proactively surfaces tensions (precision vs. latency, cost vs. quality) and defends a choice |
A practical drill: pick one prompt - "design a support chatbot over our docs" - and answer it three times, once optimizing for cost, once for latency, once for accuracy. The structure stays the same; the levers you pull change. Being able to switch framings on demand is exactly the trade-off leadership the last row rewards.
Practicing this architecture out loud is what separates people who know RAG from people who can defend a RAG design under questioning. Work through real, recently-asked questions with detailed written solutions in the PracHub question bank, and skim the other interview guides for adjacent rounds like classic distributed-system design and the software engineer track.
Frequently Asked Questions
What is a GenAI System Design interview?
It is a specialized technical round focused on architecting generative-AI workflows. Instead of designing traditional backend APIs or scaling relational databases, you design Retrieval-Augmented Generation (RAG) pipelines, LLM orchestration layers, and vector search strategies - while explicitly bounding for latency, token cost, and output quality.
Should I use LangChain in my interview answer?
You can mention orchestration frameworks like LangChain or LlamaIndex, but don't lean on them as a black box. Interviewers want to see that you understand the underlying mechanics - prompt construction, retrieval chains, and routing. If you say "I'll just use LangChain," expect a follow-up asking exactly how it executes a retrieval chain under the hood.
What is the most important component of a RAG pipeline?
The retrieval mechanism - chunking, embedding, and re-ranking. If you retrieve the wrong chunks, the LLM produces an irrelevant or hallucinated answer no matter how capable the underlying model is (the classic "garbage in, garbage out" problem). Advanced candidates spend most of their design time on chunking strategy and re-ranking rather than on the generation step.
How do I keep an LLM from hallucinating in my design?
You can't eliminate it, so design to contain it: ground answers in retrieved context, add a citation step so every claim maps to a source chunk, run groundedness evals (including LLM-as-a-judge) on responses, and log full traces so you can trace a bad answer back to the chunk that caused it. Saying "I'd fine-tune so it won't hallucinate" is a common misstep - grounding and evaluation matter more than the model choice.
Do I need to be a Machine Learning researcher to pass?
No. Software engineering and ML research are distinct skill sets. You don't need to train a foundation model from scratch in PyTorch. You do need solid MLOps fundamentals: querying foundation models securely via APIs, deploying agentic workflows, and building scalable, observable infrastructure around the model.
How should I prepare for one of these rounds?
Build the RAG pipeline once end to end so it isn't abstract, then practice narrating it under a clock with the trade-off levers (cost, latency, accuracy) at your fingertips. Pull real prompts from the PracHub question bank and rehearse answering the same one three different ways depending on which constraint is tightest.
How to Use This Page as a Prep Plan
Do not treat this as passive reading. Convert the ideas in this page into a short weekly loop: learn one idea, practice it under interview conditions, then write down what changed. That is the fastest way to turn advice into visible interview behavior.
| Prep area | What you need to prove | Practice artifact |
|---|---|---|
| Requirements | Clarify the problem before drawing boxes. | Functional and non-functional checklist. |
| Architecture | Map data flow before naming technologies. | One end-to-end diagram. |
| Tradeoffs | Explain why the design fits the constraints. | Latency, consistency, cost, and operability notes. |
| Failure handling | Show how the system behaves under stress. | Backpressure, retries, monitoring, and rollback plan. |
For GenAI & LLM System Design Interview Guide (2026), the strongest candidates usually do three things well: they make their assumptions explicit, they use concrete examples instead of vague claims, and they review mistakes quickly enough that the next practice rep is better than the last one.
Video Walkthrough
This verified YouTube video gives a second pass on the same preparation area. Use it after reading the guide, then come back and turn the advice into a practice artifact.
FAQ
What should I draw first in a system design interview?
Start with users, requests, core data, and the main read or write path. Add scale mechanisms only after the simple design is clear.
How detailed should the design be?
Deep enough to defend the main bottleneck. A focused design with good tradeoffs beats a crowded diagram with no reasoning.
How do I avoid sounding memorized?
Tie each component to a requirement and explain the tradeoff it creates.
Related Articles
From Non-CS Major to Software Engineer: A Practical Guide to Cracking the Technical Interview
Prepare for technical interviews with a practical guide to DSA practice, live coding, mock interviews, communication, and interview mindset.
From Non-CS Major to Software Engineer: A Practical Guide to Cracking the Technical Interview
Prepare for technical interviews with a practical guide to DSA practice, live coding, mock interviews, communication, and interview mindset.
Design WhatsApp: the presence and receipt problems most candidates ignore
Design WhatsApp-style chat with WebSockets, offline inboxes, Kafka partitions, presence TTLs, receipts, and reliable delivery.
I Pinned Our Autoscaler for a Month to See What Would Break. Nothing Did.
Learn when Kubernetes autoscaling helps, when CPU-based HPA wastes money, and how capacity planning can cut cloud costs safely.
Comments (0)