LLMs 20. Large Models (LLMs) External Knowledge Base Optimization — Hard Negative Sampling
Quick Overview
This technical learning hub covers hard negative sampling for dense retrieval and external knowledge base optimization with large language models, explaining why hard negatives matter, the mathematical behavior of different construction strategies (random, top-K, etc.), training dynamics, and risks such as false negatives in RAG settings.
Large Models × External Knowledge Base Optimization
Hard Negative Sampling for High-Quality Retrieval
Hard negative sampling is one of the least glamorous but most decisive components in training retrieval models. When retrieval quality plateaus, the root cause is often not the encoder architecture, not the loss function, but how negatives are constructed. This learning hub focuses on why hard negatives matter, how different construction strategies behave mathematically, and where large models change the game.
::contentReference[oaicite:0]{index=0}
I. Why Do We Need Hard Negative Samples?
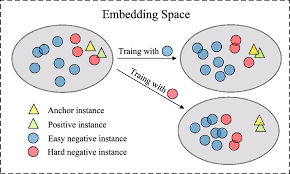
Dense retrieval models learn by contrast. For each query, the model is trained to pull positive documents closer while pushing negatives away. If the negatives are trivial—documents that are obviously unrelated—the model receives almost no learning signal.
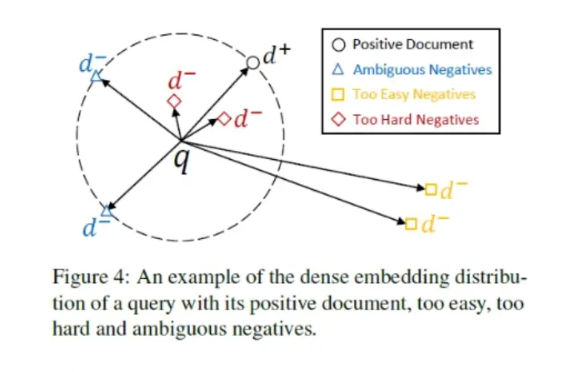
From an optimization perspective, easy negatives collapse the loss. When similarity scores for negatives approach zero, gradients vanish, and training stagnates. The model learns to separate “clearly irrelevant” content but fails to refine decision boundaries near true positives. Hard negatives exist precisely in that boundary region. They are semantically close enough to matter, but still incorrect.
In modern retrieval systems—especially those supporting RAG—this boundary is where real errors occur. Users rarely ask questions with a single obvious answer. They ask questions that overlap with many plausible but wrong passages. Hard negatives train the model to survive in that ambiguity.
II. Methods for Constructing Hard Negative Samples
2.1 Random Negative Sampling
Random sampling selects negatives uniformly from the corpus. It is computationally cheap and easy to implement, which explains its historical popularity.
However, random negatives are almost always too easy. Their similarity to the query is low, resulting in near-zero loss and negligible gradients. From a training dynamics standpoint, this is equivalent to teaching the model something it already knows. Random negatives are useful only as a baseline or during very early warm-up stages.
2.2 Top-K Hard Negative Sampling
Top-K sampling uses a retrieval model to rank documents and selects the highest-scoring non-positive documents as negatives. These negatives are genuinely challenging because the model already confuses them with positives.
The drawback is semantic risk. Top-ranked negatives may include false negatives—documents that are actually relevant but unlabeled. Training the model to push these away damages semantic alignment and can destabilize training. Gradient variance becomes large because positives and negatives exert competing forces of similar magnitude.
This strategy is powerful but unsafe unless labels are extremely reliable.
2.3 SimANS: Similarity-Aware Negative Sampling
SimANS addresses the instability of Top-K sampling by shaping which hard negatives are emphasized.
Instead of blindly selecting the most similar documents, SimANS samples negatives based on their similarity distance to a positive example. Negatives that are moderately close—close enough to be informative, but not so close that they are likely positives—receive the highest sampling probability.
This produces two benefits simultaneously: strong gradients and reduced variance. From an optimization lens, SimANS targets the region where the loss surface is steepest and most stable. It is one of the most principled approaches to hard negative sampling in dense retrieval.

2.4 Hard Negatives via Contrastive Learning Fine-Tuning
Contrastive learning reframes retrieval training as a representation alignment problem. Queries and documents are embedded jointly, and similarity is optimized through contrastive objectives.
A key insight here is that batch composition defines negatives. In-batch negatives—other documents in the same batch—serve as implicit hard negatives if batches are constructed carefully. Larger batch sizes increase negative diversity, but they also increase memory cost.
Manually injected hard negatives can coexist with in-batch negatives, but task mixing within a batch often hurts performance. In practice, high-performing systems train each retrieval task in isolation to preserve gradient clarity.
2.5 Batch-wise Hard Negative Mining
Batch-wise mining extends contrastive learning by actively selecting harder negatives as training progresses. As embeddings improve, previously easy negatives become irrelevant, and harder ones are surfaced through approximate nearest neighbor search.
This creates a feedback loop: the model improves, the negatives become harder, and the decision boundary sharpens. The main challenge is engineering complexity—mining, indexing, and refreshing negatives at scale is nontrivial.
2.6 Similar-Article or Same-Topic Negatives
Another pragmatic strategy is to sample negatives from the same article, section, or topic cluster as the positive document. These negatives share vocabulary and context but differ in intent or answerability.
This approach works well when document structure is rich (e.g., encyclopedias, academic papers). Its limitation is data dependency: small or loosely organized corpora provide few usable candidates.
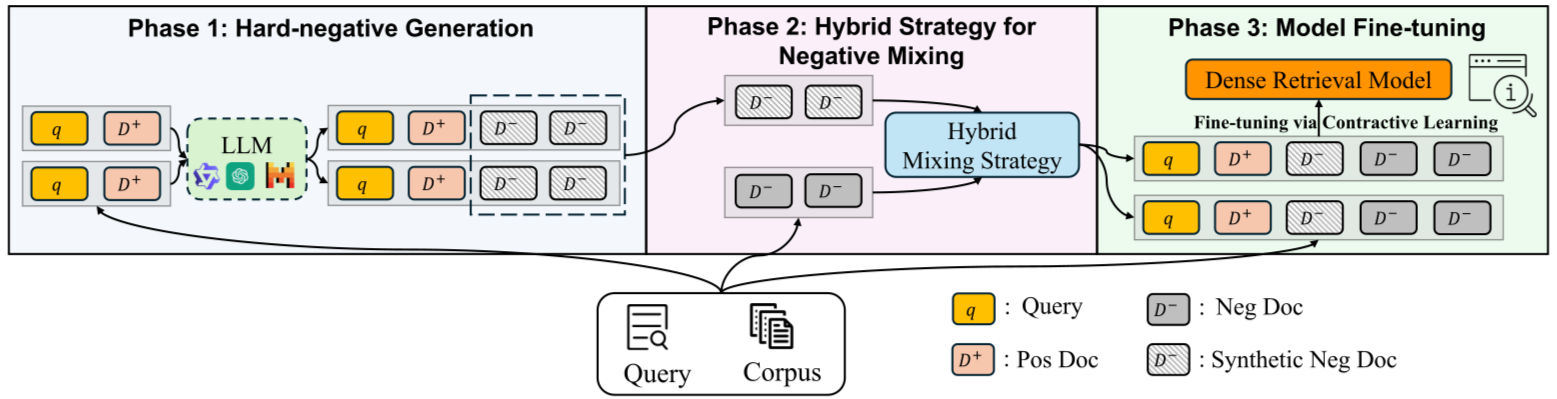
2.7 LLM-Assisted Pseudo Labels and Distillation
Large language models introduce a fundamentally new mechanism for hard negative construction: semantic judgment at scale.
An LLM can generate an answer based on retrieved passages and implicitly signal which passages matter. Documents that contribute strongly to the generated answer receive higher relevance weights, while others are treated as weaker or negative evidence. These soft signals can be distilled into a dense retriever.
This approach turns generation into supervision. It is powerful, but expensive. It also assumes the LLM’s reasoning is more reliable than the retriever’s—which is often true, but not guaranteed. In practice, LLM-assisted hard negatives are best used sparingly, for high-value domains or periodic retraining.
Supplementary Knowledge: Why Gradients Matter
Hard negative sampling is ultimately about gradient quality. Easy negatives produce gradients near zero. Extremely hard negatives produce unstable gradients. The optimal region lies in between.
Well-designed sampling strategies shape the loss landscape so that training consistently receives informative, stable updates. This is why hard negative design often matters more than architectural tweaks once a retrieval model reaches maturity.
Closing Perspective
Hard negative sampling is not a trick—it is a core system design decision. As retrieval models become stronger and corpora become larger, naïve negatives stop working. The frontier shifts toward adaptive, similarity-aware, and model-assisted strategies.
Large models do not replace hard negatives; they change how we construct them. Understanding this shift is essential for anyone building high-performance retrieval or RAG systems.
Acknowledgements
This learning hub synthesizes ideas from dense retrieval research, contrastive learning, and large-model-assisted supervision. Its goal is to help practitioners reason about negatives as first-class training signals, not implementation details.
Comments (0)