LLMs 21. RAG (Retrieval-Augmented Generation) — Evaluation
Quick Overview
This practical guide covers evaluation of Retrieval-Augmented Generation (RAG) systems, detailing why RAG evaluation differs from standard NLP evaluation, how to construct test sets that include questions, ground-truth answers, generated answers, and retrieved contexts, and methods for measuring retrieval correctness and generation faithfulness.
RAG (Retrieval-Augmented Generation) Evaluation
A Practical Learning Guide for Building Trustworthy RAG Systems
RAG systems rarely fail loudly. Most of the time, they sound correct while being subtly wrong, incomplete, or unsupported by evidence. That is exactly why evaluation matters. This post is written as a learning-oriented resource: it explains why RAG evaluation is fundamentally different from standard NLP evaluation, how to construct meaningful test sets, and how modern frameworks turn subjective judgment into measurable signals that generalize to real systems.
::contentReference[oaicite:0]{index=0}
I. Why Do We Need to Evaluate RAG?
RAG systems sit at the intersection of two imperfect components: retrieval and generation. A strong generator with weak retrieval hallucinates confidently. A strong retriever with weak generation produces fragmented or shallow answers. Worse, these failures often compensate for each other, making surface-level evaluation misleading.
Unlike traditional QA systems, RAG answers are conditioned on retrieved context. This means correctness alone is not enough. A correct answer supported by the wrong context is still dangerous. An answer that is faithful to context but misses the user’s intent is also a failure. RAG evaluation exists to disentangle these failure modes and make them observable.
At a higher level, evaluation is what turns RAG from a demo into an engineering system. Without it, iteration becomes guesswork and regressions go unnoticed.
II. How to Construct a RAG Test Set
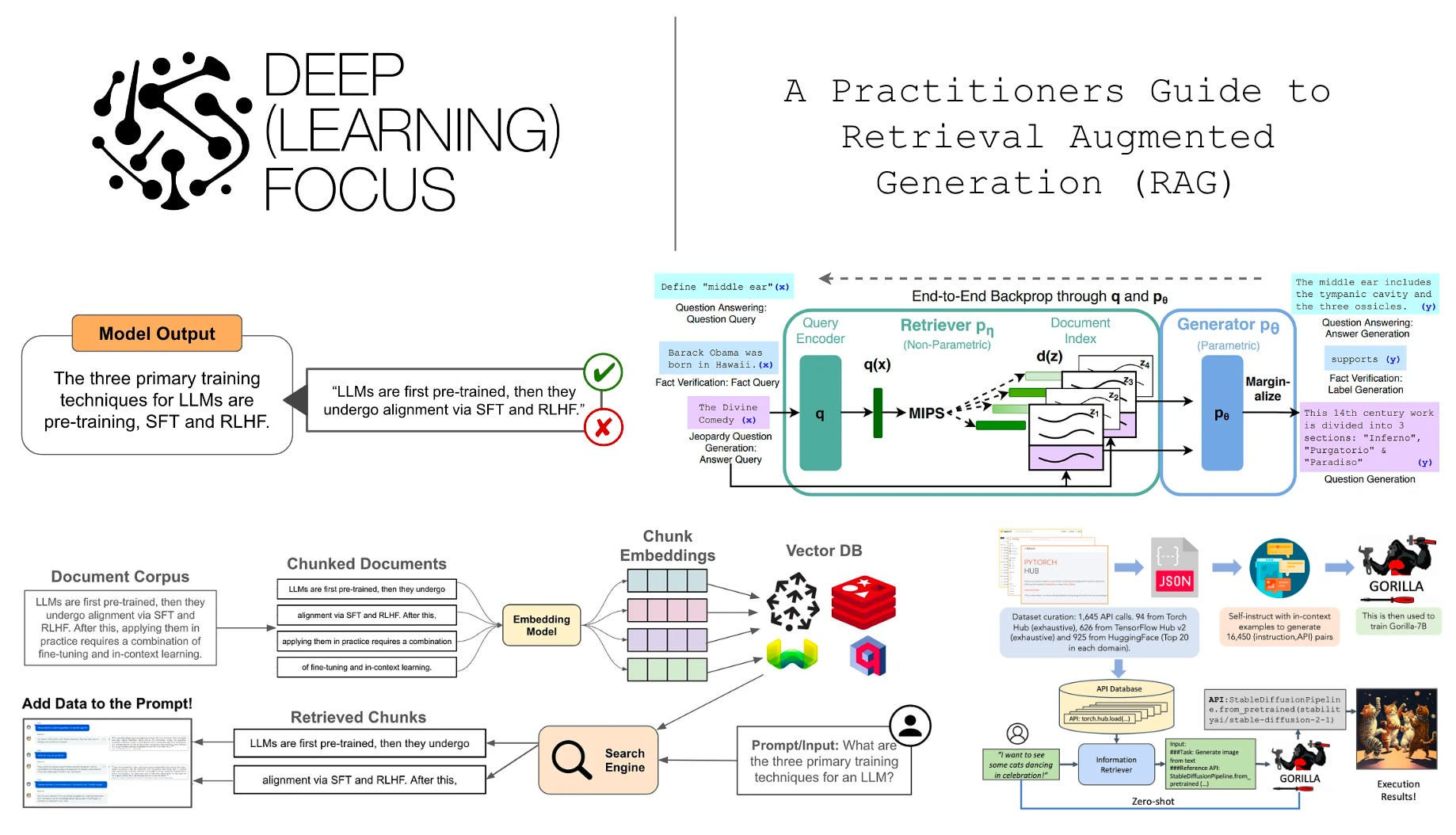
A RAG test set is not just a list of questions and answers. It must capture the entire causal chain of the system. At minimum, each test sample contains four elements: a question, a ground-truth answer, the answer generated by RAG, and the contexts retrieved during generation.
The construction process typically starts with your own knowledge base. Documents are chunked, embedded, and indexed as they would be in production. From these chunks, an LLM is prompted to generate question–answer pairs that are fully answerable from the given context. This step is crucial: it ensures that failures later can be attributed to retrieval or generation, not missing data.
Once questions are generated, they are run through the RAG system. The predicted answers and the retrieved contexts are recorded. The result is a dataset that allows you to ask not only “Is the answer correct?” but also “Was it retrieved correctly?” and “Was it generated faithfully?”
This workflow generalizes beyond RAG. The same idea applies to search systems, agent memory evaluation, and tool-augmented reasoning: evaluation data must reflect the system’s actual execution path.
III. What Evaluation Methods Exist for RAG?
Intrinsic Evaluation: Looking Inside the System
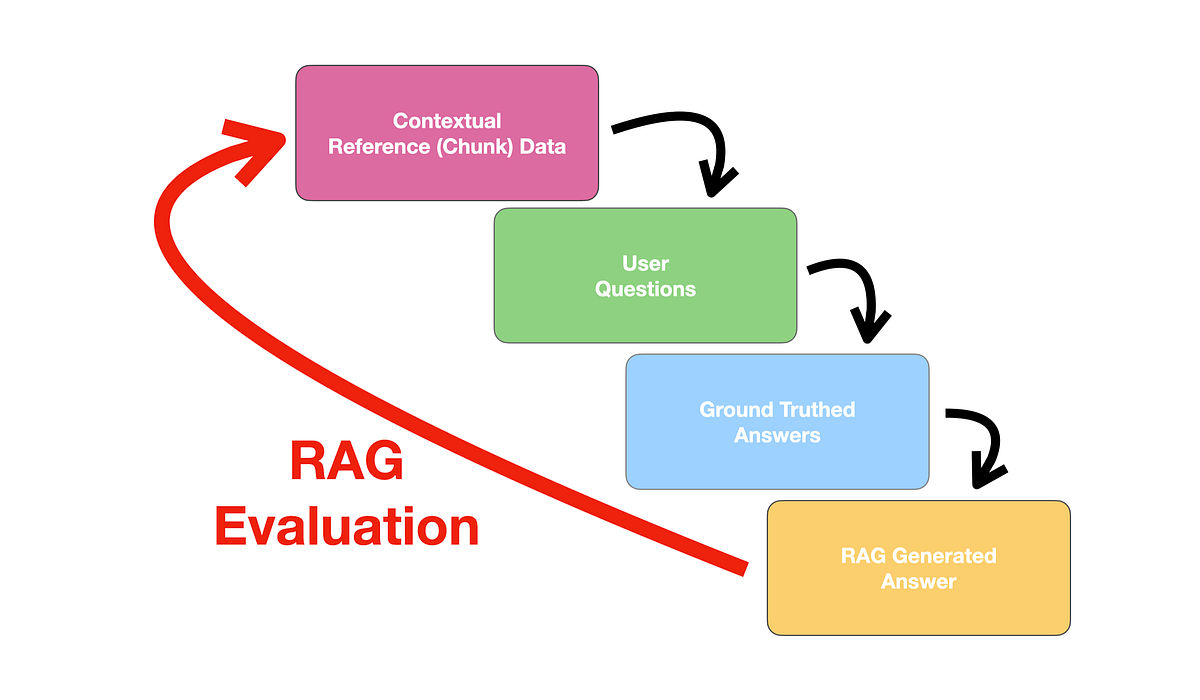
Intrinsic evaluation focuses on the internal alignment between question, retrieved context, and generated answer. It treats retrieval and generation as inspectable components rather than a black box.
Answer relevancy measures whether the answer actually addresses the question, penalizing verbosity and omission. Faithfulness measures whether the answer is supported by the retrieved context rather than external or hallucinated knowledge. Context precision and recall measure whether retrieval surfaced the right information and ranked it appropriately.
These metrics are invaluable during system optimization. They tell you where the system is failing: query rewriting, embedding quality, chunking strategy, or generation control.
End-to-End Evaluation: Judging the Outcome
End-to-end evaluation ignores internal structure and judges the final answer directly. When labeled answers exist, this resembles traditional QA evaluation with accuracy or exact match. When labels do not exist, LLM-based judges or human reviewers score answer quality, relevance, and consistency.
This approach is closer to user perception. It answers the question, “Would a human consider this response acceptable?” The trade-off is diagnosability: you learn that something is wrong, but not necessarily why.
In practice, mature RAG systems use both intrinsic and end-to-end evaluation. One guides engineering decisions; the other validates user-level quality.
IV. What Core Capabilities Should RAG Evaluation Measure?
Good RAG evaluation goes beyond raw accuracy. It measures whether the system resists hallucination under uncertainty, whether answers integrate information across multiple passages, and whether factual claims are consistently grounded in retrieved evidence.
These capabilities generalize to other LLM systems. Agent reasoning, long-context QA, and tool-calling workflows all benefit from the same evaluation lens: relevance, faithfulness, and robustness.
V. RAG Evaluation Frameworks in Practice
:contentReference[oaicite:1]{index=1}
RAGAS is a lightweight framework that uses LLMs as judges to score faithfulness, answer relevancy, and context relevancy. Its key insight is that LLMs, when constrained properly, are often better at judging semantic alignment than rule-based metrics. RAGAS is especially useful for rapid iteration and regression testing when human labels are unavailable.
:contentReference[oaicite:2]{index=2}
ARES takes a more systematic approach. It generates synthetic QA datasets from documents, fine-tunes an evaluation model on labeled examples, and then applies that judge at scale. This reduces prompt brittleness and increases consistency across evaluations. ARES is particularly well-suited for production environments where repeatability matters.
Closing Perspective
Evaluating RAG is not about finding a single “score.” It is about making failure modes visible. Once you can see where a system fails—retrieval, grounding, or generation—you can fix it. The same mindset extends beyond RAG to any system where LLMs interact with external knowledge.
In that sense, RAG evaluation is less about metrics and more about discipline. It forces us to treat language models not as oracles, but as components in a system that must earn trust through evidence.
Acknowledgements
This learning resource synthesizes ideas from RAG system design, information retrieval evaluation, and recent LLM-based judging frameworks. Its goal is to help practitioners reason about evaluation as a first-class system concern, not an afterthought.
Comments (0)