LLMs 22. Retrieval-Augmented Generation (RAG) Optimization Strategies
Quick Overview
This guide covers systems-level optimization strategies for retrieval-augmented generation (RAG), including pipeline components such as document ingestion, chunking, embedding, retrieval strategies, prompt construction, generation logic, intent alignment, and techniques like knowledge-graph–augmented retrieval, plus practical skills in pipeline debugging, embedding evaluation, and retrieval tuning. It is aimed at machine learning engineers seeking to build mental models of where RAG systems fail and how upstream data-processing and retrieval choices interact with generation, presented as a learning guide rather than a checklist.
Retrieval-Augmented Generation (RAG) Optimization Strategies
A Systems-Level Learning Guide
RAG is often introduced as a simple idea—retrieve relevant context, then generate an answer—but in practice it behaves like a complex information system. Performance bottlenecks rarely come from a single module. They emerge from interactions between document processing, retrieval, reasoning, and generation. This post is written as a learning resource rather than a checklist. The goal is to help you build a mental model of where RAG fails, why optimizations work, and how these ideas generalize to other LLM-based systems.
::contentReference[oaicite:0]{index=0}
I. RAG Architecture: Thinking in Pipelines, Not Models
At a high level, a RAG system consists of document ingestion, chunking, embedding, retrieval, prompt construction, and generation. The key insight is that each stage compresses information. Once information is lost early—through poor chunking, weak embeddings, or misaligned queries—it cannot be recovered later by a stronger LLM.
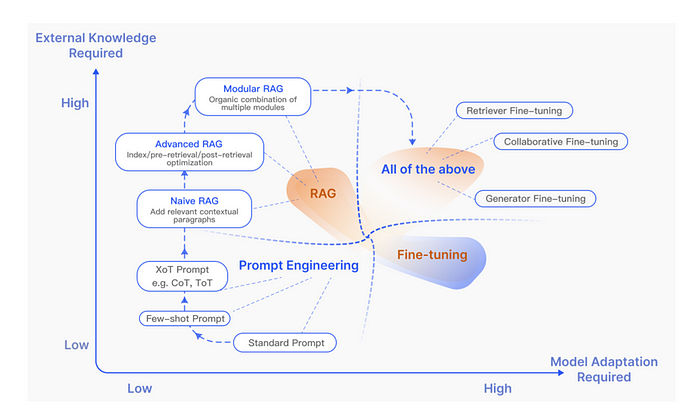
This is why RAG optimization is fundamentally different from prompt tuning. Prompting operates at the final stage, while most RAG failures originate upstream. Effective optimization therefore starts with the data and retrieval pipeline, not the generator.
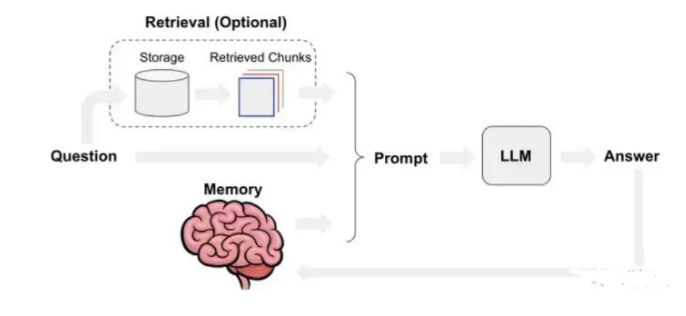
II. Common Optimization Directions for RAG
Most RAG improvements fall into four broad directions.
Document processing determines what information is even eligible for retrieval. Text embedding controls how meaning is represented. Retrieval strategies decide which candidates survive. Generation logic determines how evidence is used. These are not independent choices; changing one shifts the failure surface of the others.
A recurring theme across high-performing systems is intent alignment. RAG works best when document structure, embedding space, retrieval logic, and generation behavior all reflect the same notion of relevance.
III. Core RAG Optimization Methods
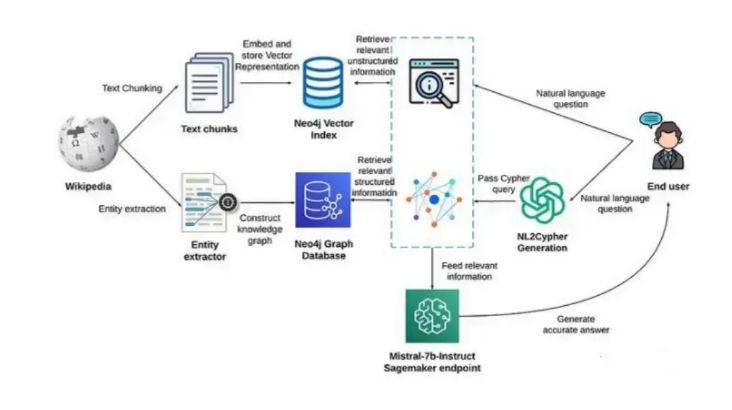
1. Improving Context Retrieval with Knowledge Graphs
Direct chunk-based retrieval often misses critical context because documents are not flat text. Important information may be spread across sections or encoded as relationships rather than sentences. Knowledge Graphs help by making relationships explicit.
By converting a query into a structured graph query (for example, via Cypher), the system retrieves entities and relations that dense retrieval alone might miss. These structured results can then be merged with dense retrieval outputs, producing context that is both semantically rich and relationally complete. This idea generalizes to any system where relations matter more than surface text, including recommendation and decision-support systems.
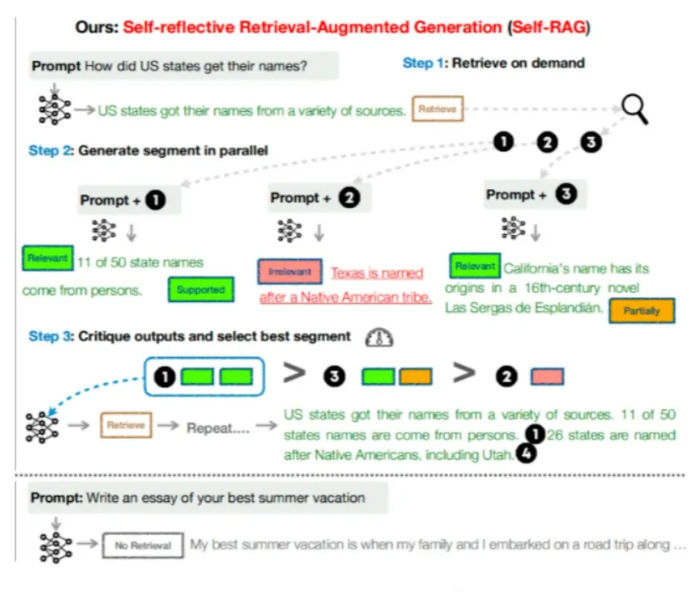
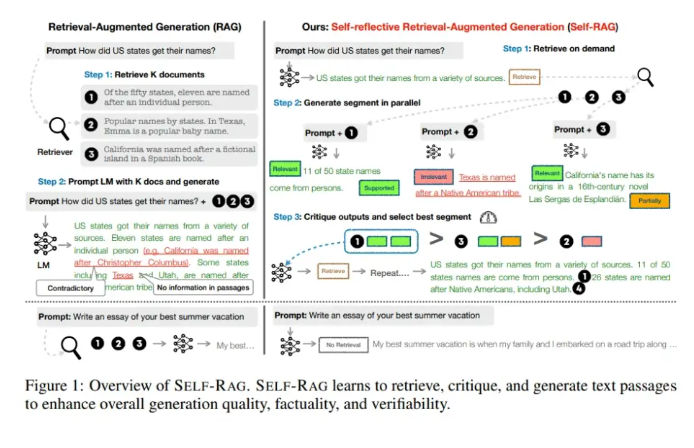
2. Self-RAG: Letting the Model Decide When to Retrieve
One of the most important RAG insights is that not every question needs retrieval. Self-RAG introduces a mechanism for the model to decide whether external knowledge is required before answering.
The innovation lies in reflection tokens. These special tokens allow the model to critique its own output: whether retrieval is needed, whether a passage is relevant, whether an answer is supported, and whether it is useful. Instead of blindly retrieving context, the model retrieves on demand, evaluates the quality of retrieved content, and iterates only when necessary.
This approach reframes RAG as adaptive reasoning rather than a fixed pipeline. The same idea applies beyond RAG, for example in tool-use agents that must decide when to call APIs versus reason internally.
3. Multi-Round Retrieval and Generation
Single-pass retrieval assumes that all necessary information can be identified upfront. This breaks down for complex or compositional questions. Multi-round RAG allows the system to retrieve, generate partial answers, identify gaps, and retrieve again.
In text-only settings, this looks like iterative query refinement. In multimodal settings, it becomes more powerful: text, tables, images, and knowledge graphs can be retrieved at different stages. The system effectively walks the knowledge space, guided by intermediate reasoning steps.
This mirrors how humans research: we search, read, refine the question, and search again.
4. Fusion and Query Expansion
RAG Fusion improves recall by generating multiple query variants from the original user input. Each variant retrieves its own candidate set, and the results are fused and re-ranked.
This strategy works because user queries are rarely optimal retrieval queries. Query expansion decomposes intent and surfaces different semantic facets. While fusion cannot fully solve intent ambiguity, it significantly reduces blind spots in retrieval-heavy domains such as technical documentation and legal text.
5. Modular RAG: Breaking the Monolith
Modern RAG systems increasingly abandon the idea of a single retriever and generator. Instead, they adopt modular architectures with dedicated search, memory, verification, and alignment modules.
For example, a verification module can filter unreliable passages before generation, while a memory module can reuse the model’s own prior outputs. This modular view makes RAG extensible and task-adaptive, a pattern that also appears in agent frameworks and decision-support pipelines.

6. RAG vs. Supervised Fine-Tuning (SFT)
RAG and SFT are not competitors; they are complementary. SFT teaches a model how to respond, while RAG supplies what to respond with.
Hybrid approaches update the generator to better use retrieved context while training the retriever to avoid spurious correlations. This reduces sensitivity to retrieval noise and improves robustness—an idea that applies broadly to systems combining learned policies with external memory.
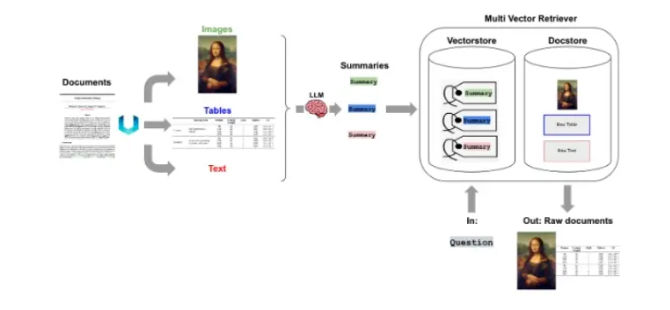
7. Query Transformation and Alignment
Many retrieval failures come from poorly aligned queries. By transforming or decomposing queries into sub-questions or hypothetical answers, similarity scores improve dramatically. This technique is especially effective when documents are long and multifaceted.
The broader lesson is that queries are also data. Treating them as fixed inputs is a design mistake.
IV. Systematic RAG Optimization
Effective RAG optimization is iterative and measurement-driven. Coarse-grained changes (chunk size, embedding model) establish a baseline. Joint optimization (for example, chunking plus fusion) refines interactions. System-level optimization then tunes behavior across modules using evaluation feedback.
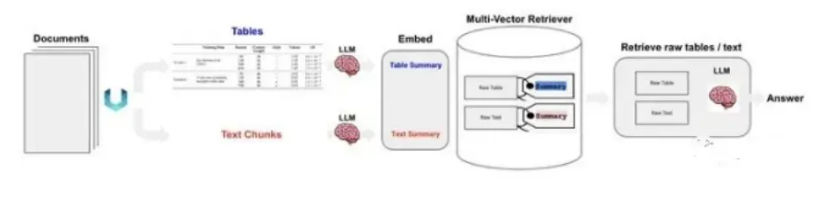
The key is to change one variable at a time and measure impact. Without evaluation, optimization degenerates into anecdotal tuning.
V. Evaluating Whether Optimization Works
RAG evaluation must cover retrieval quality, generation quality, and their interaction. Retrieval metrics alone do not predict answer correctness. Generation metrics alone do not detect hallucination.
The most reliable signal comes from joint evaluation: is the answer correct, relevant, and supported by retrieved evidence? Systems that optimize toward this goal tend to generalize better across domains.
Future Directions of RAG
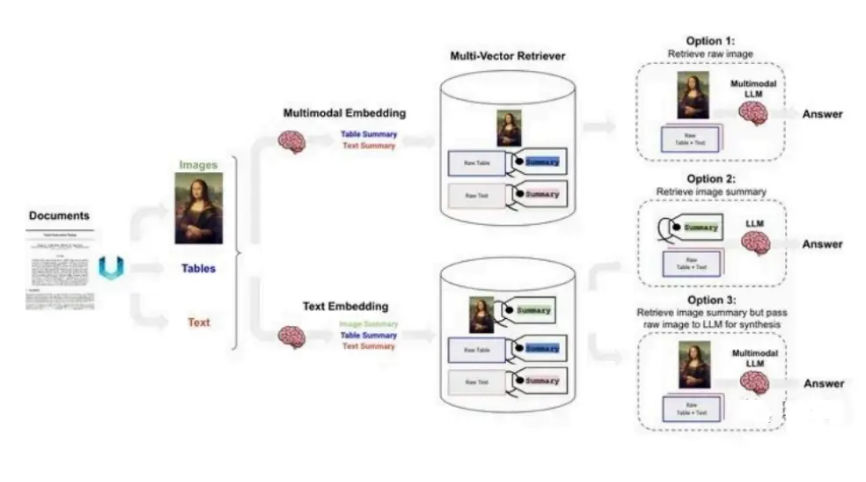
RAG is evolving along three axes.
Vertical optimization focuses on robustness, long-context handling, and tighter integration with fine-tuning. Horizontal expansion extends RAG beyond text to images, code, audio, and video. The ecosystem dimension concerns tooling, evaluation frameworks, and interpretability.
Across all directions, one theme dominates: RAG is becoming a reasoning system, not just a retrieval trick. As that happens, optimization principles from search, databases, and systems engineering become as important as advances in language modeling.
Acknowledgements
This learning guide synthesizes ideas from recent RAG research, production system design, and multimodal retrieval pipelines. Its purpose is to help readers reason about RAG optimization as a systems problem—one that rewards structure, measurement, and iteration over ad-hoc tuning.
Comments (0)