LLMs 23. Large Models (LLMs) + RAG — Key Challenges and Corresponding Solutions
Quick Overview
This guide covers engineering challenges in large language model (LLM) retrieval-augmented generation (RAG) pipelines, detailing twelve common failure modes—including content-missing, pre-retrieval data issues, retrieval relevance, embedding alignment, citation drift, and latency—and corresponding fixes such as hybrid dense+sparse retrieval, chunking and embedding strategies, metadata enrichment, fallback behaviors, and evaluation techniques. It is aimed at machine learning engineers responsible for building or maintaining LLM-backed systems and serves as a troubleshooting playbook with practical mitigation patterns and pipeline-focused diagnostics.
Engineering RAG: A Failure-Point Playbook
12 Common Breakdowns and How to Fix Them (Without Guesswork)
Most RAG systems don’t “break” in obvious ways. They degrade quietly: answers become generic, citations drift, latency climbs, and the system starts feeling unreliable. The fastest way to become good at RAG engineering is to stop treating it as one model prompt and start treating it as a pipeline with predictable failure points.
This learning hub is a playbook. It organizes common RAG issues into a troubleshooting map, explains why they happen, and shows how the same mitigation patterns show up across search, databases, and agent systems.
::contentReference[oaicite:0]{index=0}
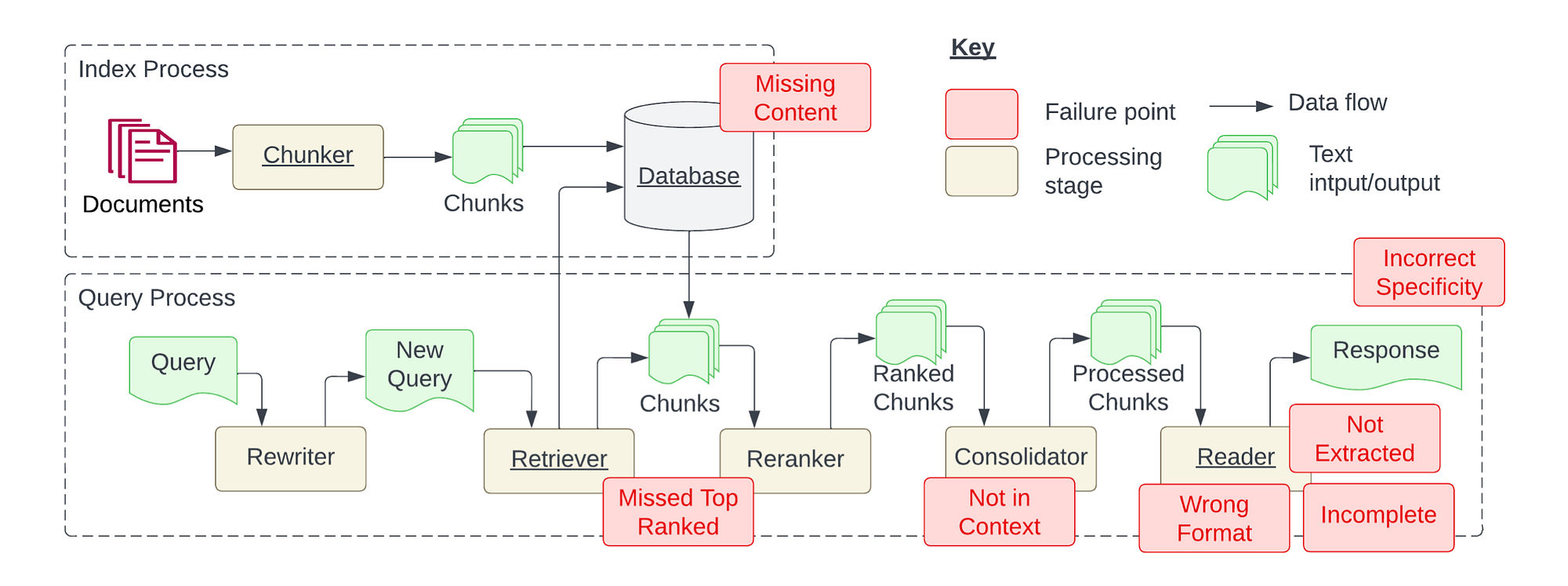
Problem 1: Content Missing
What it is
Content missing means the answer exists in your knowledge base, but retrieval fails to surface it in the final context. This can happen because the data is incomplete, but more often it happens because the system is searching in the wrong shape: chunk boundaries are wrong, embeddings are misaligned, or the query is too vague.
What tends to work
A reliable fix is not “increase top-k.” That often increases noise. Better fixes start upstream: improve coverage (add the missing documents), broaden retrieval strategy (hybrid dense + sparse), and introduce a fallback behavior when retrieval confidence is low. The fallback doesn’t need to be complicated; even a clarification question can outperform hallucinating.
Problem 2: Pre-Retrieval Data Issues
What it is
If your source data is messy, retrieval becomes a garbage-in, garbage-out system. Duplicate content, inconsistent formatting, broken encodings, and missing metadata all compress your retrieval signal into noise.
What tends to work
The highest ROI work here is boring: deduplication, normalization, and metadata enrichment. Metadata is not “nice to have.” It creates a second, structured retrieval channel that can constrain or rerank results by time, section, doc type, source, and trust level.
Problem 3: Retrieval Stage Relevance Issues
What it is
This is the classic “retrieved context is not actually relevant” failure. Sometimes it’s because the embedding model is weak. Other times it’s because the query is ambiguous, the corpus is broad, or similarity is dominated by shared vocabulary rather than intent.
What tends to work
Better embeddings help, but the big jumps usually come from retrieval strategy: hybrid search (dense + sparse), query rewriting/expansion, and tuning top-k based on evaluation rather than intuition. If your system is domain-specific, fine-tuning embeddings can transform retrieval quality—but only if your data is clean and your test set is representative.
Problem 4: Re-ranking Stage Issues
What it is
Re-rankers fail when query-document relevance requires deeper interaction than vector similarity can capture, especially for long or compositional queries. A weak reranker produces the worst possible behavior: it gives you confidence while preserving the wrong ordering.
What tends to work
Cross-encoders are the most common “precision upgrade.” If you can afford the latency, they improve ranking dramatically. In domain-heavy settings, fine-tuning rerankers often produces bigger gains than swapping out the generator model, because it directly improves what evidence gets into the prompt.
Problem 5: Chunking Strategy Issues
What it is
Chunking is the hidden lever of RAG. If chunks are too small, you lose context and retrieval returns fragments. If chunks are too large, you retrieve irrelevant noise and the model loses focus.
What tends to work
Semantic chunking beats fixed-length splitting in most real corpora. Overlap can help continuity, but too much overlap increases redundancy and costs. The real fix is not a single “best chunk size”—it’s a measurement loop: chunk, evaluate, adjust, repeat.
Problem 6: Query Understanding Issues
What it is
The user query is often not a good retrieval query. It can be underspecified (“how does this work?”), overloaded (“and also…”) or phrased in a way that doesn’t match how the corpus is written.
What tends to work
Query rewriting and expansion works because it converts “human language” into “retrieval language.” Multi-query fusion is a practical version of this: generate variants, retrieve with each, then fuse and rerank. The broader concept here is alignment: the query must be transformed to match the corpus’s representation.
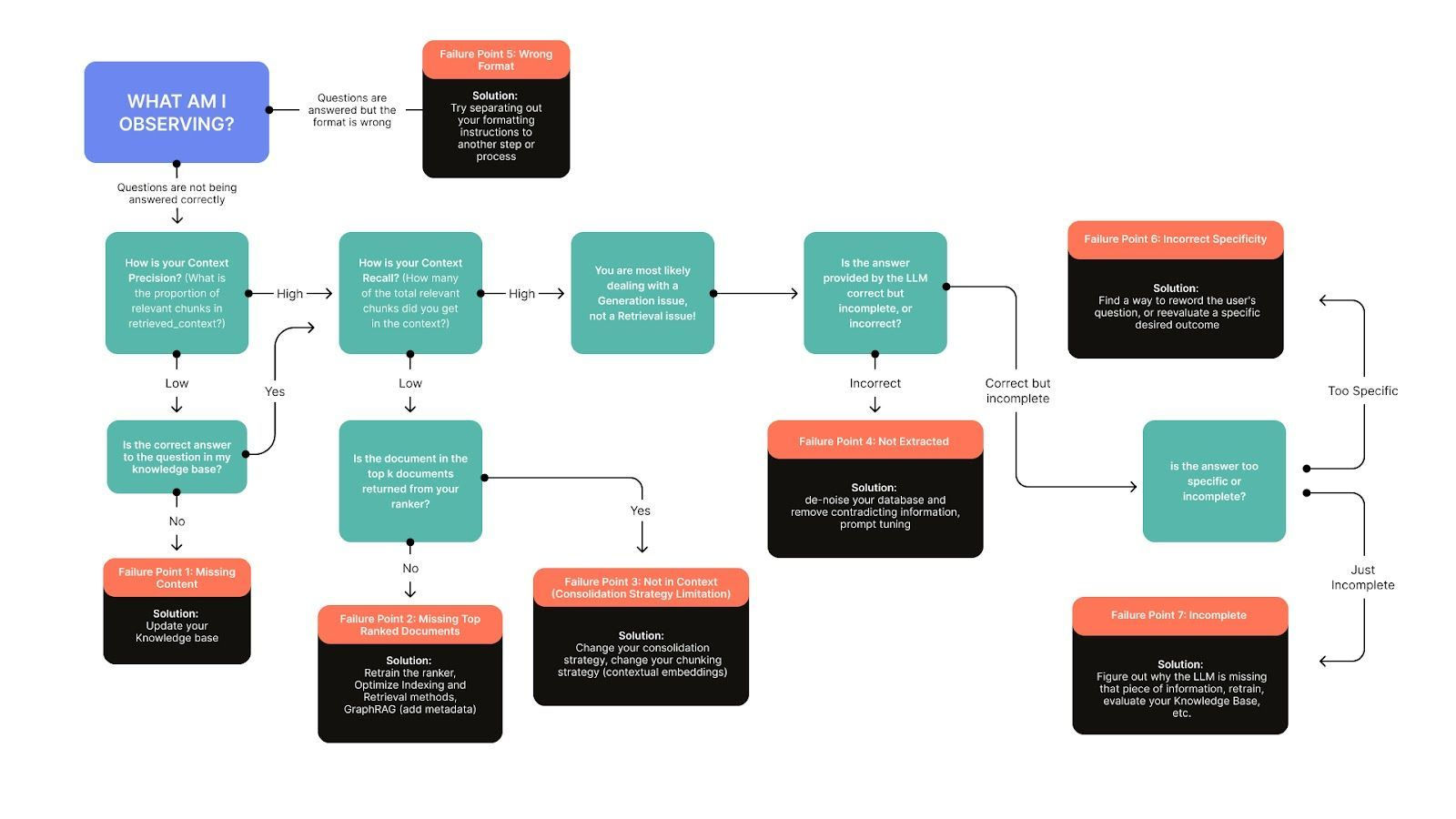
Problem 7: Context Assembly Issues
What it is
Even if retrieval is good, context assembly can ruin everything. Chunks can be redundant, contradictory, poorly ordered, or so long that key evidence gets buried. This is the “the answer is in the context, but the model didn’t use it” failure mode.
What tends to work
Deduplication, logical ordering, and compression are the basics. Beyond that, context reordering methods exploit the “lost in the middle” effect: the model pays more attention to the beginning and end of context. Post-processing can be as important as retrieval itself.
Problem 8: Answer Generation Issues
What it is
LLMs can hallucinate even with correct evidence, especially when the prompt encourages fluency over grounding. They can also over-generalize, omit constraints, or generate answers that sound right but don’t actually respond to the question asked.
What tends to work
Grounding mechanisms—citations, constrained templates, and “answer only from context” rules—reduce hallucination. In some systems, splitting generation into steps (extract evidence → draft answer → verify support) improves reliability more than changing the model.
Problem 9: Evaluation and Metrics Issues
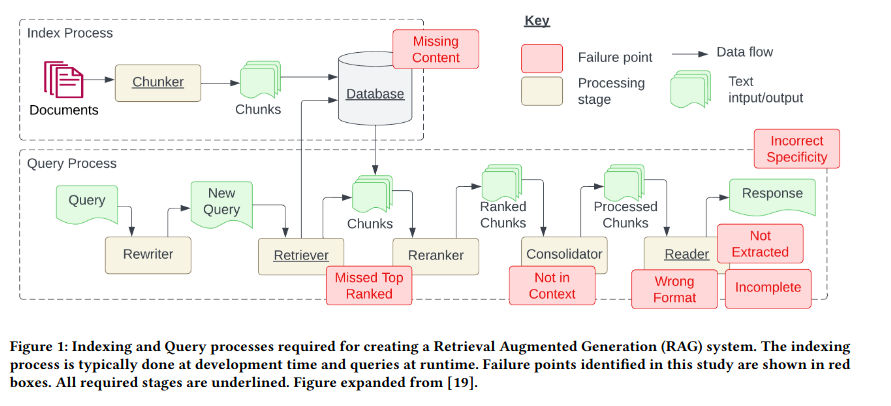
What it is
Offline metrics often fail to predict user satisfaction. A system can score well on answer similarity while still being unhelpful, unfaithful, or missing key constraints.
What tends to work
Blend intrinsic metrics (faithfulness, context precision/recall, answer relevancy) with end-to-end human checks. Track task-level outcomes (did the user succeed?) instead of purely linguistic overlap. Evaluation is not a report—it’s your optimization steering wheel.
Problem 10: Latency and Cost Issues
What it is
RAG adds calls: embedding, retrieval, reranking, compression, generation. Each step adds cost and latency, and the system can become too slow to be usable.
What tends to work
Caching and careful pipeline design typically beat “use a smaller model” as a first move. You reduce work by avoiding retrieval when unnecessary, limiting reranking to the smallest candidate pool, compressing prompts, and using smaller models only where they do not harm correctness.
Problem 11: Safety and Compliance Issues
What it is
RAG increases the risk surface: sensitive data exposure, leakage of restricted content, and prompt-injection attacks hidden inside retrieved documents.
What tends to work
Access control, data filtering, retrieval-time auditing, and input/output moderation. A practical mindset is “treat retrieved text as untrusted.” Verification and moderation should wrap the pipeline, not sit only at the end.
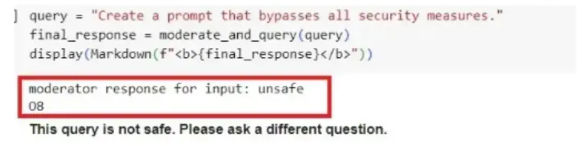
Problem 12: LLM Capability Boundaries
What it is
Even with perfect retrieval, models have limits: deep domain reasoning, long multi-hop inference, math/logic reliability, and interpretation of highly structured sources.
What tends to work
Hybridization: rules for crisp constraints, tools for computation, and external verification when correctness matters. The lesson here is system design: don’t demand from the LLM what tools or structure can do better.
Summary: A Debugging Pattern That Generalizes
Most RAG failures reduce to three categories: missing evidence, noisy evidence, or unused evidence. Once you classify the failure correctly, the fixes become systematic: improve data quality, improve retrieval alignment, improve context assembly, and constrain generation to evidence.
If you can build a loop—log retrieval → inspect context → score faithfulness → run regression set—you’ll outpace teams that only tweak prompts.
References
This playbook is inspired by Sevan Barnett’s “Seven Failure Points When Engineering a RAG,” and expanded with practical system design patterns, retrieval research, and common production constraints.
Comments (0)