LLMs 24. Large Language Models (LLMs) RAG Optimization Strategies — RAG-Fusion Edition
Quick Overview
This technical guide and learning hub covers RAG-Fusion optimization strategies for large language models, including multi-query generation, vector embeddings and database retrieval, fusion and aggregation methods, system architecture considerations, and comparisons with standard RAG.
Large Language Models (LLMs) × RAG Optimization
RAG-Fusion: Turning Single Queries into Multi-Perspective Retrieval
RAG works well when the user knows exactly what to ask. Reality is messier. Users ask vague, partial, or under-specified questions, while knowledge bases are large, heterogeneous, and unevenly structured. RAG-Fusion exists to bridge this gap. This learning hub explains why RAG-Fusion emerged, how it works technically, and where its ideas generalize beyond RAG.
::contentReference[oaicite:0]{index=0}
1. What Advantages Does Standard RAG Have?
RAG fundamentally changed how LLMs interact with external knowledge. By grounding generation in retrieved documents, it reduced hallucination and made large models usable in enterprise and professional settings. Vector search integration allows models to surface relevant context even when wording differs from stored documents, while generation turns retrieval results into coherent answers rather than raw snippets.
Just as importantly, RAG aligns well with how organizations already manage information: documents, databases, and logs can be indexed without retraining the model. This separation of knowledge from reasoning is one of RAG’s greatest strengths.
2. What Limitations Does RAG Still Have?
Despite its strengths, standard RAG inherits the weaknesses of retrieval systems. It relies on a single query to represent user intent. If that query is vague, incomplete, or phrased differently from the corpus, retrieval quality collapses.
There is also a semantic gap between how humans think and how retrieval systems work. People rarely express their intent in one clean sentence; they imply background knowledge, constraints, and priorities. Traditional RAG maps one query directly to ranked documents, often missing nuanced or multi-facet intent.
In short, RAG improves generation quality, but retrieval still bottlenecks the system.
3. Why Is RAG-Fusion Needed?
RAG-Fusion reframes the problem: instead of asking “How do we retrieve better from one query?”, it asks “Why are we forcing intent into a single query at all?”
RAG-Fusion generates multiple semantically distinct queries from the original input. Each query explores a different aspect of intent. Retrieval is performed independently for each query, and results are then fused into a single ranking using a robust aggregation method.
This reduces sensitivity to phrasing, captures latent intent, and dramatically improves recall without requiring perfect embeddings or hand-crafted rules.
4. Core Technologies Behind RAG-Fusion
At a system level, RAG-Fusion uses the same building blocks as standard RAG: embeddings, vector databases, and an LLM. The difference lies in where the intelligence is applied.
Instead of pushing all reasoning into generation, RAG-Fusion injects intelligence before retrieval. The LLM becomes a query-planner, not just an answer-writer. Ranking fusion then replaces raw similarity scores with a more stable aggregation mechanism.
This architectural shift is subtle but powerful: it turns retrieval from a passive lookup into an active exploration process.
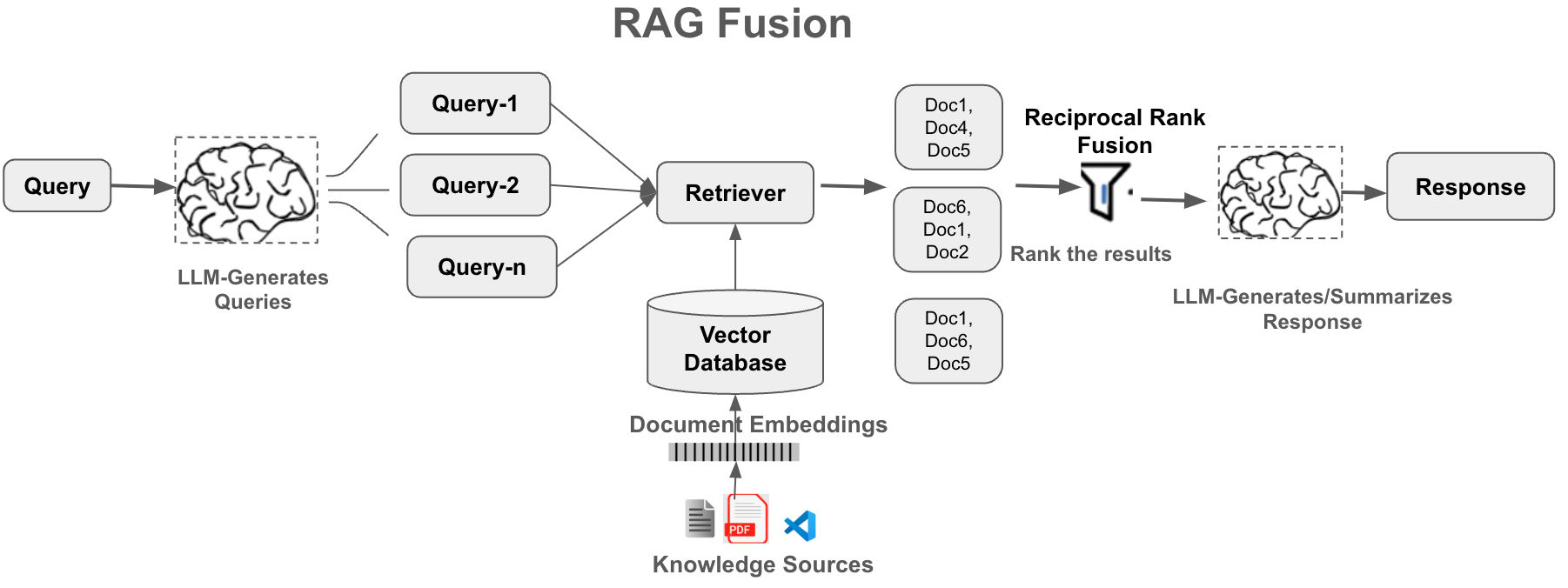
5. RAG-Fusion Workflow Explained
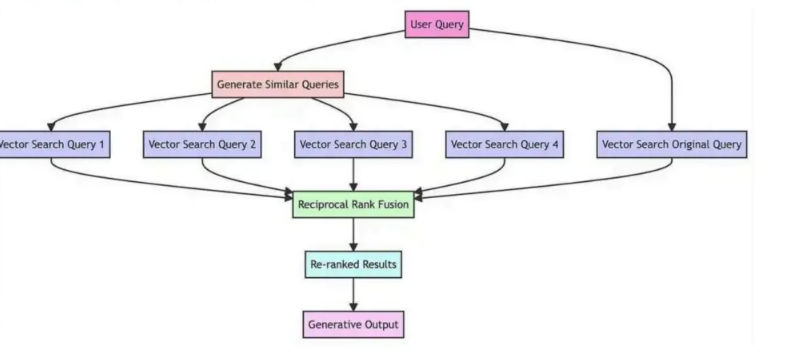
Multi-Query Generation
The workflow begins by asking the LLM to generate multiple queries from the original user input. These are not simple paraphrases. Each query reflects a different dimension, assumption, or interpretation of intent.
For example, a question about climate change might expand into economic impact, public health consequences, and policy responses. Each query acts as a probe into a different region of the knowledge space.
How Multi-Query Generation Works
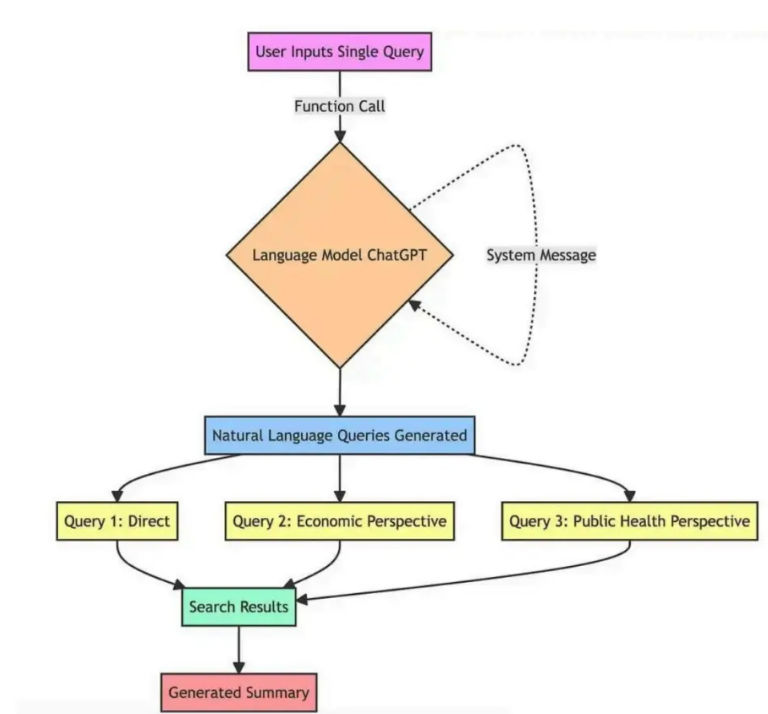
A system-level prompt instructs the model to preserve the original intent while expanding coverage. Diversity is intentional. Overlap is acceptable. The goal is to reduce blind spots, not to produce a single “best” query.
This idea generalizes beyond RAG. It is essentially intent decomposition, a technique that also appears in planning agents, search engines, and recommendation systems.
6. Reciprocal Rank Fusion (RRF)
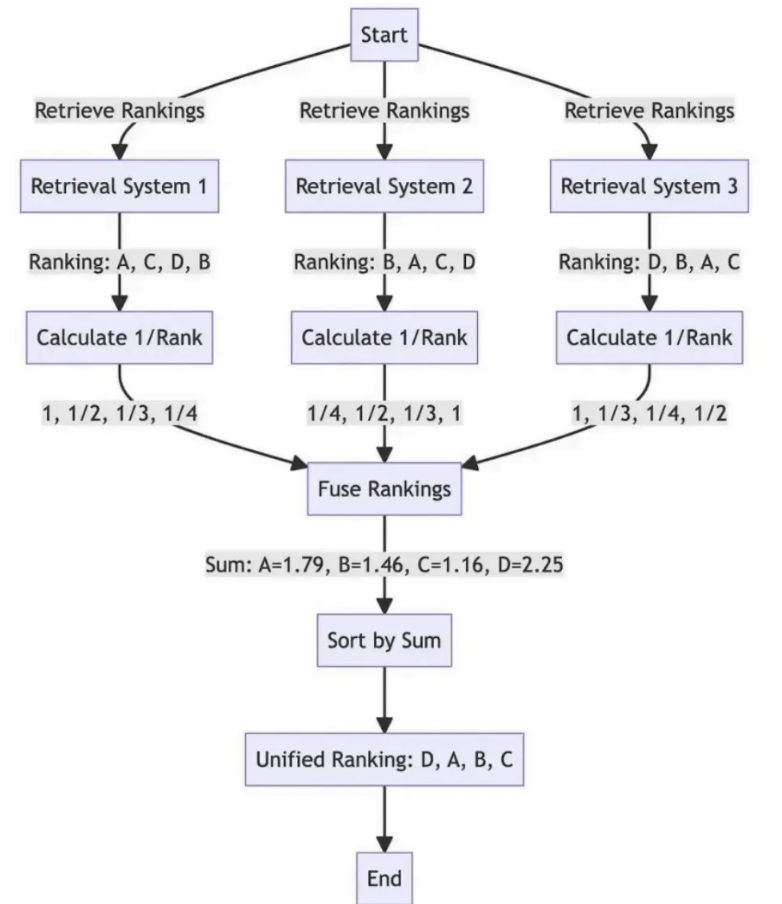
Why RRF Is Chosen
Once multiple ranked lists are retrieved, they must be merged. Raw similarity scores cannot be compared across different queries or retrieval methods. RRF solves this by ignoring scores entirely and relying only on rank positions.
Each document receives a score based on how highly it appears in each list. Documents that consistently rank well across multiple queries rise to the top, even if they were never ranked first in any single list.
This makes RRF robust, simple, and surprisingly effective across heterogeneous retrieval systems.
How RRF Works in Practice
Each ranked list contributes a small reciprocal score to documents based on rank position. These scores are summed across all lists, and the final ranking is produced by total score. No tuning of similarity scales is required, which makes RRF ideal for combining dense, sparse, and hybrid retrieval outputs.
7. Preserving User Intent
Multi-query generation introduces a new risk: intent dilution. If queries drift too far, retrieval becomes unfocused.
RAG-Fusion mitigates this at two levels. First, prompts explicitly anchor generation to the original query. Second, the original query and fused results are injected back into the final generation prompt. The LLM is reminded why the information was retrieved, not just what was retrieved.
This balance between expansion and anchoring is one of the most transferable ideas in RAG-Fusion design.
8. Advantages of RAG-Fusion
RAG-Fusion improves retrieval depth rather than simply tweaking ranking. It captures multi-dimensional intent, handles complex questions more gracefully, and often surfaces information users did not know to ask for.
It also acts as an automatic query-refinement layer. Misspellings, vague phrasing, and incomplete questions are corrected implicitly through query diversity. For expert domains, this often produces more structured and insight-rich answers.
9. Challenges and Trade-offs
RAG-Fusion is not free. Multiple queries mean more retrieval calls, more fusion computation, and more pressure on the context window. Without careful compression and ranking, verbosity can overwhelm users.
There are also UX and ethical considerations. Transforming user queries without transparency can feel manipulative. Strong systems expose generated queries, allow opt-out, and preserve the original query as a visible anchor.
Like most powerful techniques, RAG-Fusion requires restraint.
Closing Perspective
RAG-Fusion represents a shift from retrieval as lookup to retrieval as exploration. Its core idea—expanding intent, probing multiple perspectives, and fusing evidence—extends well beyond RAG. You will see the same pattern in planning agents, research assistants, and decision-support systems.
If standard RAG answers what you asked, RAG-Fusion tries to answer what you meant.
Acknowledgements
This learning resource synthesizes ideas from retrieval research, ranking fusion, and modern RAG system design, with particular inspiration from work on multi-query retrieval and reciprocal rank fusion.
Comments (0)