LLMs 26. Large Language Models (LLMs): Parameter-Efficient Fine-Tuning (PEFT)
Quick Overview
This article explains parameter-efficient fine-tuning (PEFT) for large language models, covering how PEFT differs from full-model retraining, the mechanisms changed under the hood, common techniques and trade-offs, and how these ideas generalize beyond LLMs.
Parameter-Efficient Fine-Tuning (PEFT): How Modern LLMs Adapt Without Retraining Everything
Fine-tuning sits at the boundary between general intelligence and task usefulness. Pretrained language models know a lot, but they rarely know exactly what your task, domain, or style demands. Fine-tuning is how we bridge that gap. Over the last few years, however, the field has moved away from the idea that “updating everything” is always the right answer. This post explains why that shift happened, what PEFT actually changes under the hood, and how these ideas generalize beyond LLMs.
1. What does fine-tuning really mean?
At its core, fine-tuning means continuing training a pretrained model on task-specific data. Historically, this meant full-parameter fine-tuning: every weight in the network was updated via backpropagation. This approach, popularized by early Transformer models like BERT, works well because it gives the optimizer maximum freedom to adapt representations.
The downside is cost. Large language models contain billions of parameters, and updating all of them is slow, memory-intensive, and fragile. Small datasets can easily cause overfitting or catastrophic forgetting, where the model loses general knowledge it previously had.
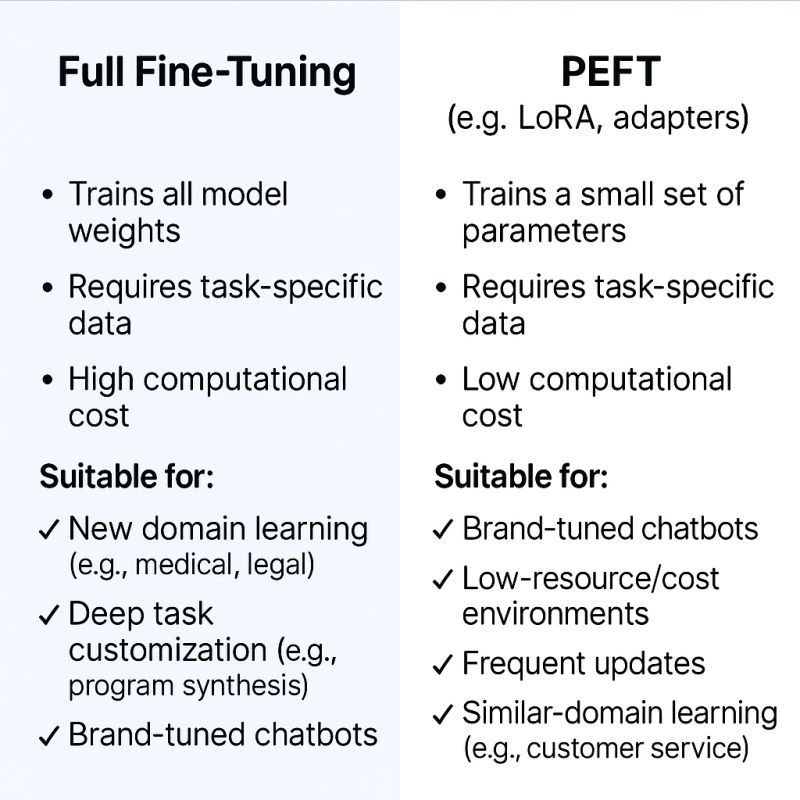
This tension led to a second family of methods: parameter-efficient fine-tuning (PEFT). Instead of changing the whole model, PEFT methods introduce small, trainable components or selectively update limited parameters, while freezing the rest.
2. Two philosophies of adaptation: full FT vs PEFT
A useful way to think about the difference is knowledge vs behavior.
Full fine-tuning can change the model’s internal knowledge representation. If you want the model to genuinely “learn new facts” or deeply restructure how it reasons, this is still the most powerful option.
PEFT methods, in contrast, primarily steer behavior. They bias attention, reshape intermediate activations, or condition generation without rewriting the entire knowledge base. For most downstream tasks - classification, instruction following, style control - this turns out to be sufficient.
Empirically, studies such as BELLE show a consistent pattern: full fine-tuning tends to outperform LoRA-style methods in absolute score, but PEFT recovers much of the performance at a fraction of the cost. In practice, this trade-off is often the difference between possible and impossible.
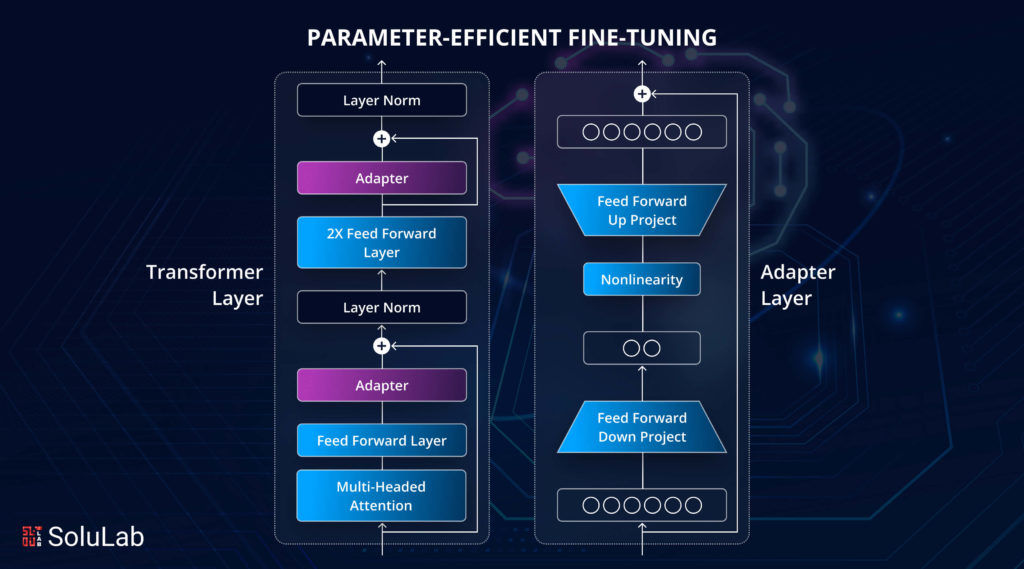
3. What is PEFT, conceptually?
Parameter-efficient fine-tuning is not a single technique but a design principle:
Reuse the pretrained model as a frozen backbone, and adapt it with minimal additional parameters.
This principle appears in several concrete forms:
- adding trainable vectors to the input (prompt-based methods),
- injecting small modules into the network (adapters),
- or reparameterizing weight updates in low-rank form (LoRA-style methods).
What they share is that the pretrained weights remain intact, preserving general knowledge while allowing fast specialization.
4. Why PEFT became necessary (not just convenient)
Three pressures made PEFT unavoidable rather than optional.
First, scale. Modern LLMs are too large for full fine-tuning to be routine. Even with powerful GPUs, updating billions of parameters for every task is economically unrealistic.
Second, data scarcity. Many real tasks have tens of thousands of examples, not millions. Updating the full model on small datasets often hurts more than it helps.
Third, deployment reality. Organizations want multiple task-specific variants of the same base model. PEFT allows storing and swapping small “delta” modules instead of duplicating entire models.
Seen this way, PEFT is less about clever tricks and more about systems engineering.
5. LoRA, AdaLoRA, and the idea of low-rank change
LoRA reframes fine-tuning as a low-rank update problem. Instead of modifying a large weight matrix directly, LoRA learns two small matrices whose product approximates the update. This dramatically reduces the number of trainable parameters while keeping inference unchanged.
AdaLoRA builds on this idea by allocating parameter budget dynamically. Instead of fixing the rank everywhere, it learns where capacity matters most. Results on benchmarks like GLUE show that AdaLoRA can consistently outperform standard LoRA with similar parameter counts.
This idea generalizes beyond NLP. Anywhere large matrices dominate computation - vision models, multimodal models, even recommendation systems - low-rank adaptation can offer the same efficiency gains.
6. Prompt-based methods: adapting without touching the network
Prompt tuning and P-Tuning take a different route. Rather than changing internal layers, they learn continuous prompt embeddings that condition the model’s behavior. Conceptually, this is closer to learning how to ask the model than changing what it knows.
These methods work surprisingly well for simpler tasks and classification-style problems. They struggle when deep reasoning or domain knowledge shifts are required, but they shine when compute is extremely limited.
This distinction mirrors an old lesson in machine learning: feature engineering versus model capacity. Prompt tuning is closer to feature engineering; LoRA is closer to lightweight model adaptation.
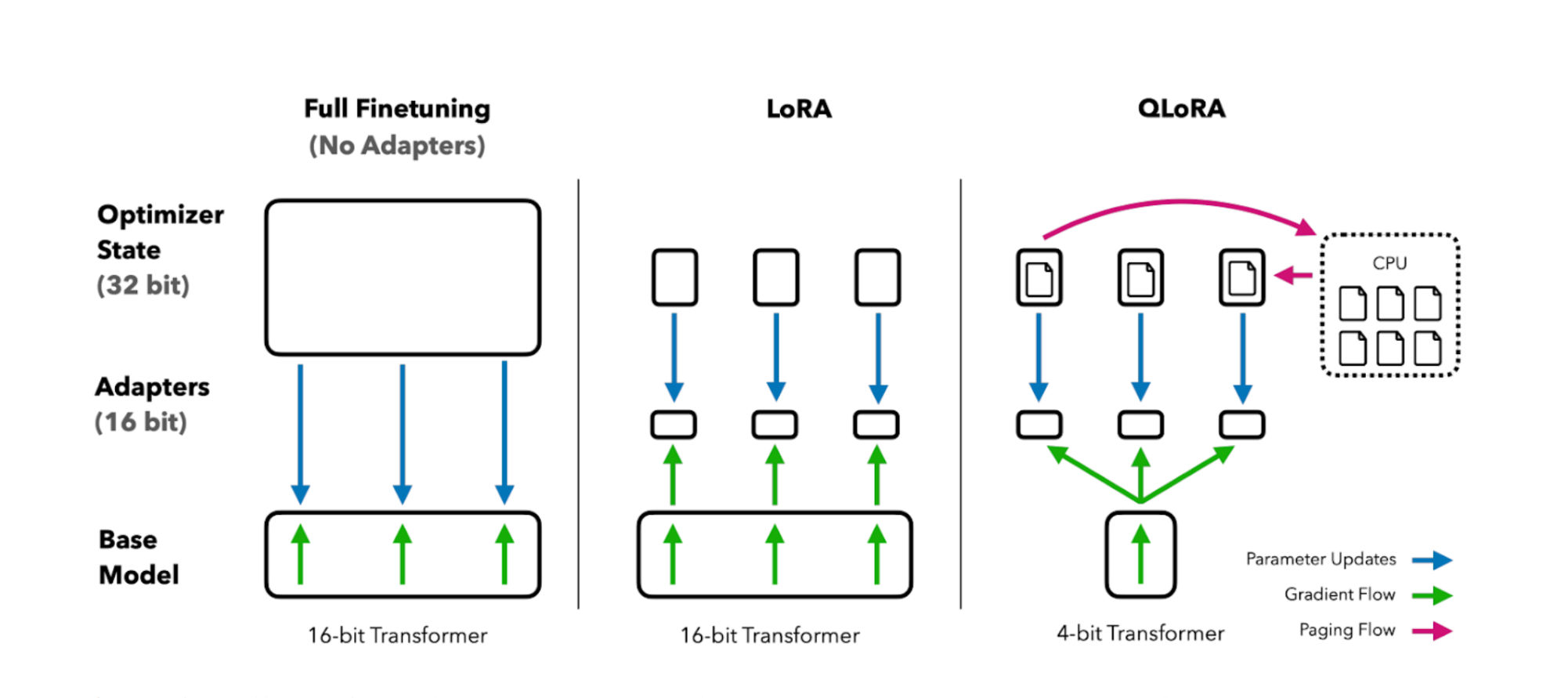
7. Memory, throughput, and why INT4 matters
One reason PEFT exploded in popularity is that it pairs naturally with quantization. Techniques like QLoRA allow models to be loaded in INT8 or INT4 precision while still training low-rank adapters in higher precision.
The result is counterintuitive at first: you can fine-tune a multi-billion-parameter model on a single GPU with less than 10GB of memory, while maintaining usable throughput. This has reshaped who can realistically experiment with LLMs.
8. Limitations you should not ignore
PEFT is not a free lunch. Compared to full fine-tuning, it often suffers from:
- slightly reduced peak accuracy,
- sensitivity to model size and architecture,
- inconsistent evaluation practices across papers.
More importantly, PEFT cannot fully rewrite a model’s worldview. If your task requires injecting new factual knowledge at scale, full fine-tuning or retrieval-based approaches (like RAG) are often a better fit.
This is why PEFT and RAG are increasingly seen as complements, not competitors.
9. Best practices that transfer across domains
Some lessons from PEFT apply well beyond language models:
- Always separate what is frozen from what is adaptable.
- Evaluate methods across multiple model sizes, not just one.
- Treat efficiency as a first-class metric, not an afterthought.
- Design adaptation modules to be modular, swappable, and inspectable.
These ideas echo classic principles in software architecture: stable cores, flexible edges.
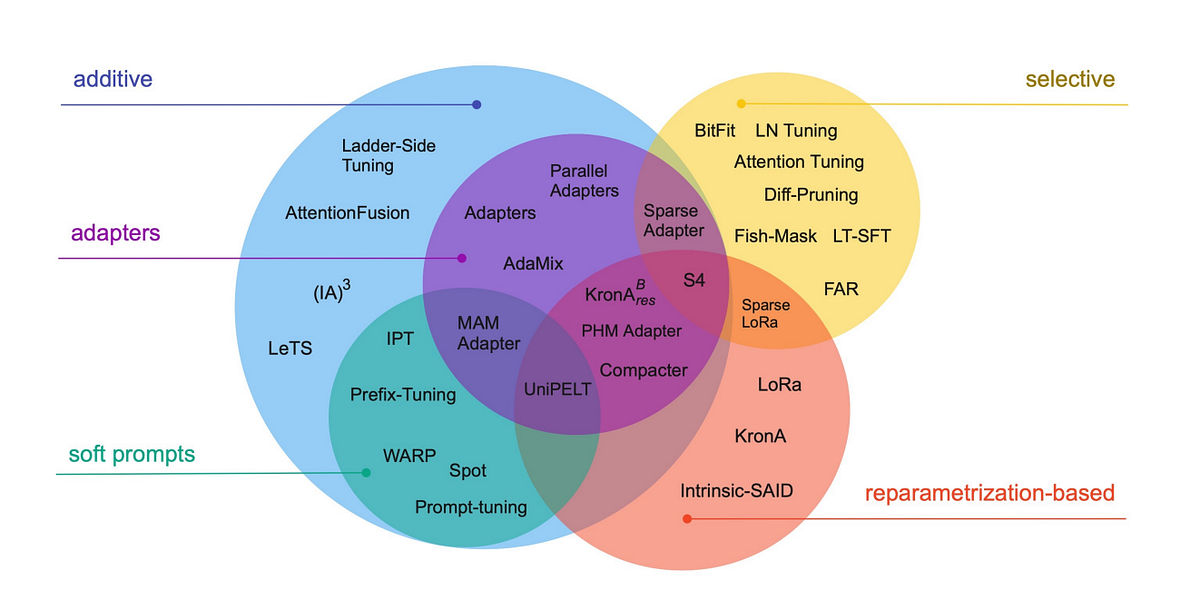
10. A useful mental map of PEFT methods
Instead of memorizing names, it helps to classify PEFT approaches by how they adapt:
- Additive methods add new parameters (prompts, adapters).
- Selective methods tune only a subset of existing parameters.
- Reparameterization methods (LoRA, AdaLoRA, QLoRA) constrain updates mathematically.
- Hybrid methods combine multiple strategies.
Once you see this structure, new papers become much easier to place.
Closing perspective
Parameter-efficient fine-tuning is not just a cost-saving trick. It reflects a deeper shift in how we think about large models: not as monoliths to be retrained end-to-end, but as general engines that can be cheaply and repeatedly adapted.
Understanding PEFT helps you reason about LLMs more broadly - how knowledge, behavior, and efficiency trade off against each other - and prepares you to design systems that scale in the real world, not just on benchmarks.
How to Use This Page as a Prep Plan
Do not treat this as passive reading. Convert the ideas in this page into a short weekly loop: learn one idea, practice it under interview conditions, then write down what changed. That is the fastest way to turn advice into visible interview behavior.
| Prep area | What you need to prove | Practice artifact |
|---|---|---|
| Understand | Turn the prompt into a concrete goal. | Clarifying questions and success criteria. |
| Practice | Use realistic constraints and timed reps. | Worked examples with edge cases. |
| Explain | Make reasoning visible. | Tradeoffs, assumptions, and test strategy. |
| Improve | Review misses quickly. | A short feedback log and next action. |
For LLMs 26. Large Language Models (LLMs): Parameter-Efficient Fine-Tuning (PEFT), the strongest candidates usually do three things well: they make their assumptions explicit, they use concrete examples instead of vague claims, and they review mistakes quickly enough that the next practice rep is better than the last one.
Video Walkthrough
This verified YouTube video gives a second pass on the same preparation area. Use it after reading the guide, then come back and turn the advice into a practice artifact.
FAQ
How should I use this guide?
Read it once for the structure, then turn each section into a practice task with a visible artifact.
What should I do if I am short on time?
Prioritize the skills most likely to be tested, then do one mock or timed drill to expose the largest gap.
How do I know I am ready?
You can explain your approach clearly, recover from hints, and name tradeoffs without relying on memorized wording.
Related Articles
Machine Learning Interview Questions: Complete 2026 Guide
This guide covers applied machine learning interview topics in 2026, including coding problems, ML theory such as bias–variance and evaluation......
Machine Learning Engineering Interview Guide (MLOps & AI 2026)
This guide covers MLOps and ML system design for 2026 interviews, including model deployment and production maintenance, CI/CD for models, data......
Shopify Machine Learning Engineer Interview Guide 2026
This guide details Shopify's 2026 Machine Learning Engineer interview process and study map, covering stages such as recruiter screens, the Life Story......
Snapchat Machine Learning Engineer Interview Guide 2026
This guide covers the Snapchat Machine Learning Engineer interview process in 2026, including recruiter and technical screens, virtual onsite loops......
Comments (0)