LLMs 27. Adapter Fine-Tuning (Adapter-Tuning)
Quick Overview
This guide covers adapter fine-tuning for large language models, explaining why adapters emerged, how adapter-tuning works, parameter-efficient fine-tuning techniques, implementation considerations, trade-offs, and evaluation strategies for adapting pretrained models under compute and storage constraints.
Adapter Fine-Tuning: Why It Exists, How It Works, and Why It Still Matters
As pretrained language models grew from millions to billions of parameters, fine-tuning quietly became one of the most expensive steps in the entire ML pipeline. Adapter Fine-Tuning emerged not as a clever trick, but as a structural response to scale. Understanding adapters is useful far beyond this specific method - they reveal how modern LLM adaptation is designed around constraints, not just accuracy.
1. Why Adapter Fine-Tuning is needed
Full fine-tuning assumes that, for every new task, we can afford to update all parameters of a pretrained model. That assumption breaks quickly in practice. Large models are expensive to train, expensive to store, and expensive to duplicate across tasks. Even worse, updating all parameters risks overwriting useful general representations learned during pretraining.
Adapter Fine-Tuning was proposed to solve a very pragmatic problem: how do we adapt a large pretrained model to many downstream tasks without retraining or duplicating it each time? The answer was to treat the pretrained model as a frozen backbone and attach task-specific “plugins” that are cheap to train and easy to swap.
2. The core idea behind Adapter Fine-Tuning
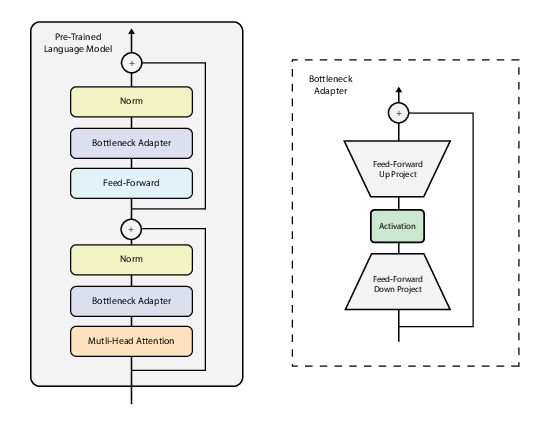
An adapter is a small neural module inserted inside each Transformer layer. Its structure is intentionally simple: a down-projection that compresses high-dimensional features into a low-dimensional bottleneck, a non-linear transformation, and an up-projection that maps the representation back to the original dimension.
Crucially, adapters use a skip connection. This guarantees that, if the adapter learns nothing useful, it can behave like an identity function and leave the original model untouched. This design makes adapters safe to insert into large models without destabilizing training.
During fine-tuning, all original model parameters are frozen. Only the adapter parameters are updated. The pretrained model retains its general knowledge, while the adapters learn task-specific behavior. From a systems perspective, this turns fine-tuning into parameter composition rather than parameter modification.
3. Characteristics and trade-offs of Adapter Fine-Tuning
Adapters dramatically reduce training cost and storage overhead, but they are not free. Because adapters are executed inside the forward pass, they introduce additional inference latency. Each Transformer layer now includes extra matrix multiplications.
This trade-off - small parameter count versus extra compute - highlights an important theme in modern model design: efficiency is multi-dimensional. Reducing training cost may increase inference cost, and vice versa. Adapter Fine-Tuning sits at a different point in this trade-off space than LoRA or prompt tuning.
4. AdapterFusion: learning across tasks, not just per task
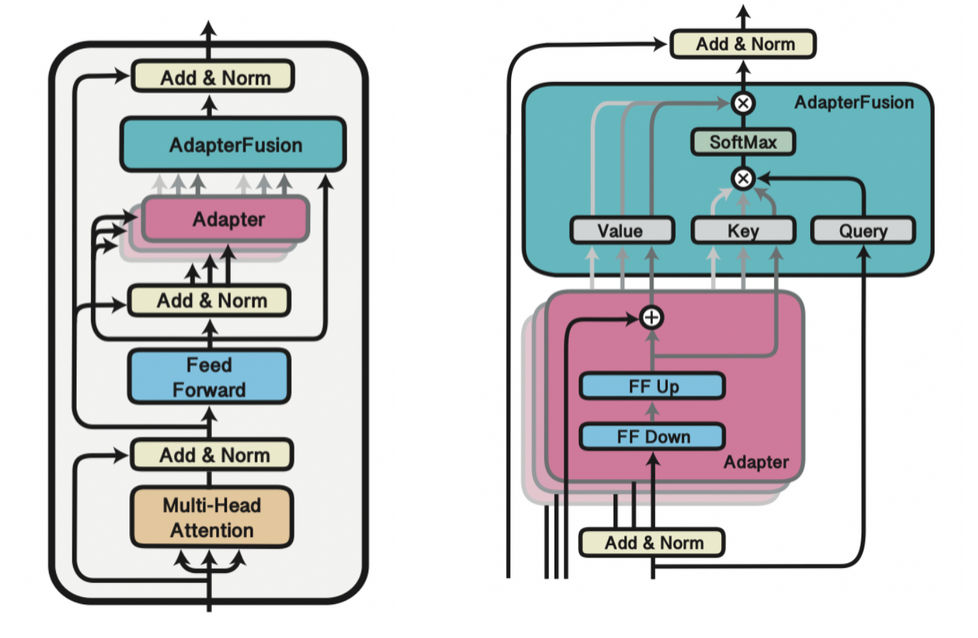
AdapterFusion extends the adapter idea to multi-task learning. Instead of training a single adapter per task and stopping there, AdapterFusion introduces a second training stage that learns how to combine multiple pretrained adapters.
In the first stage, adapters are trained independently on different tasks. In the second stage, the base model remains frozen, and AdapterFusion learns weighted combinations of these adapters. This allows the model to reuse knowledge across tasks instead of relearning everything from scratch.
Conceptually, AdapterFusion treats adapters as skills and learns how to mix them. This idea generalizes well beyond NLP and aligns with broader research on modular and compositional learning.
5. AdapterDrop: when fewer adapters are enough
AdapterDrop addresses a practical inefficiency: not all Transformer layers contribute equally to task adaptation. Empirical evidence shows that removing adapters from shallower layers often has minimal impact on performance.
AdapterDrop exploits this by dynamically removing adapters during training and inference, reducing both computation and memory usage. The key insight is that depth matters - later layers tend to be more task-specific, while earlier layers encode general features.
This idea connects adapter research to a larger trend in deep learning: adaptive computation, where models learn not just what to compute, but how much to compute.
6. MAM Adapter: unifying multiple PEFT ideas
The MAM Adapter takes a step back and asks a broader question: are Adapter Tuning, Prefix Tuning, and LoRA fundamentally different, or are they variations of the same underlying idea?
MAM Adapter shows that these methods can be unified. It combines parallel adapters in the feed-forward network with soft prompts, effectively merging structural adaptation and input-level conditioning. The result is a hybrid approach that often outperforms any single PEFT method in isolation.
This is an important lesson: PEFT methods are not mutually exclusive. In many cases, the best results come from combining complementary adaptation mechanisms rather than choosing one.
7. What Adapter Fine-Tuning teaches us beyond adapters
Adapters are more than a historical PEFT method. They illustrate several principles that now define modern LLM adaptation:
- Large pretrained models should be treated as stable cores, not constantly rewritten.
- Task-specific knowledge is often better added around a model than inside it.
- Modular design enables reuse, composition, and efficient multi-task deployment.
- Efficiency must be evaluated across training, inference, storage, and maintenance - not just accuracy.
These principles show up again in LoRA, QLoRA, RAG systems, and even agent-based architectures.
Closing perspective
Adapter Fine-Tuning was one of the first serious attempts to make large models practically adaptable. While newer methods like LoRA often dominate in practice today, adapters remain conceptually important. They shifted the field away from “fine-tune everything” toward structured, modular adaptation.
If you understand adapters, you are not just learning a technique - you are learning how modern ML systems are engineered under real-world constraints.
How to Use This Page as a Prep Plan
Do not treat this as passive reading. Convert the ideas in this page into a short weekly loop: learn one idea, practice it under interview conditions, then write down what changed. That is the fastest way to turn advice into visible interview behavior.
| Prep area | What you need to prove | Practice artifact |
|---|---|---|
| Understand | Turn the prompt into a concrete goal. | Clarifying questions and success criteria. |
| Practice | Use realistic constraints and timed reps. | Worked examples with edge cases. |
| Explain | Make reasoning visible. | Tradeoffs, assumptions, and test strategy. |
| Improve | Review misses quickly. | A short feedback log and next action. |
For LLMs 27. Adapter Fine-Tuning (Adapter-Tuning), the strongest candidates usually do three things well: they make their assumptions explicit, they use concrete examples instead of vague claims, and they review mistakes quickly enough that the next practice rep is better than the last one.
Video Walkthrough
This verified YouTube video gives a second pass on the same preparation area. Use it after reading the guide, then come back and turn the advice into a practice artifact.
FAQ
How should I use this guide?
Read it once for the structure, then turn each section into a practice task with a visible artifact.
What should I do if I am short on time?
Prioritize the skills most likely to be tested, then do one mock or timed drill to expose the largest gap.
How do I know I am ready?
You can explain your approach clearly, recover from hints, and name tradeoffs without relying on memorized wording.
Related Articles
Machine Learning Interview Questions: Complete 2026 Guide
This guide covers applied machine learning interview topics in 2026, including coding problems, ML theory such as bias–variance and evaluation......
Machine Learning Engineering Interview Guide (MLOps & AI 2026)
This guide covers MLOps and ML system design for 2026 interviews, including model deployment and production maintenance, CI/CD for models, data......
Shopify Machine Learning Engineer Interview Guide 2026
This guide details Shopify's 2026 Machine Learning Engineer interview process and study map, covering stages such as recruiter screens, the Life Story......
Snapchat Machine Learning Engineer Interview Guide 2026
This guide covers the Snapchat Machine Learning Engineer interview process in 2026, including recruiter and technical screens, virtual onsite loops......
Comments (0)