LLMs 29. LoRA Series
Quick Overview
This guide explains LoRA and its variants, covering low-rank adaptation theory, LoRA implementation details, QLoRA quantization and adapter training, and practical considerations for parameter-efficient fine-tuning and deployment.
 LoRA and Its Variants: Learning How to Adapt Large Models Efficiently
LoRA and Its Variants: Learning How to Adapt Large Models Efficiently
Large language models are powerful not because we keep retraining them from scratch, but because we’ve learned how to adapt them cheaply. LoRA and its variants represent a shift in mindset: instead of rewriting a model’s knowledge, we learn how to steer it with minimal, well-placed changes. This post is designed as a learning resource rather than a checklist—something you can come back to when reasoning about parameter-efficient fine-tuning (PEFT) in real systems.
- LoRA: Low-Rank Adaptation, from intuition to practice What LoRA is really doing
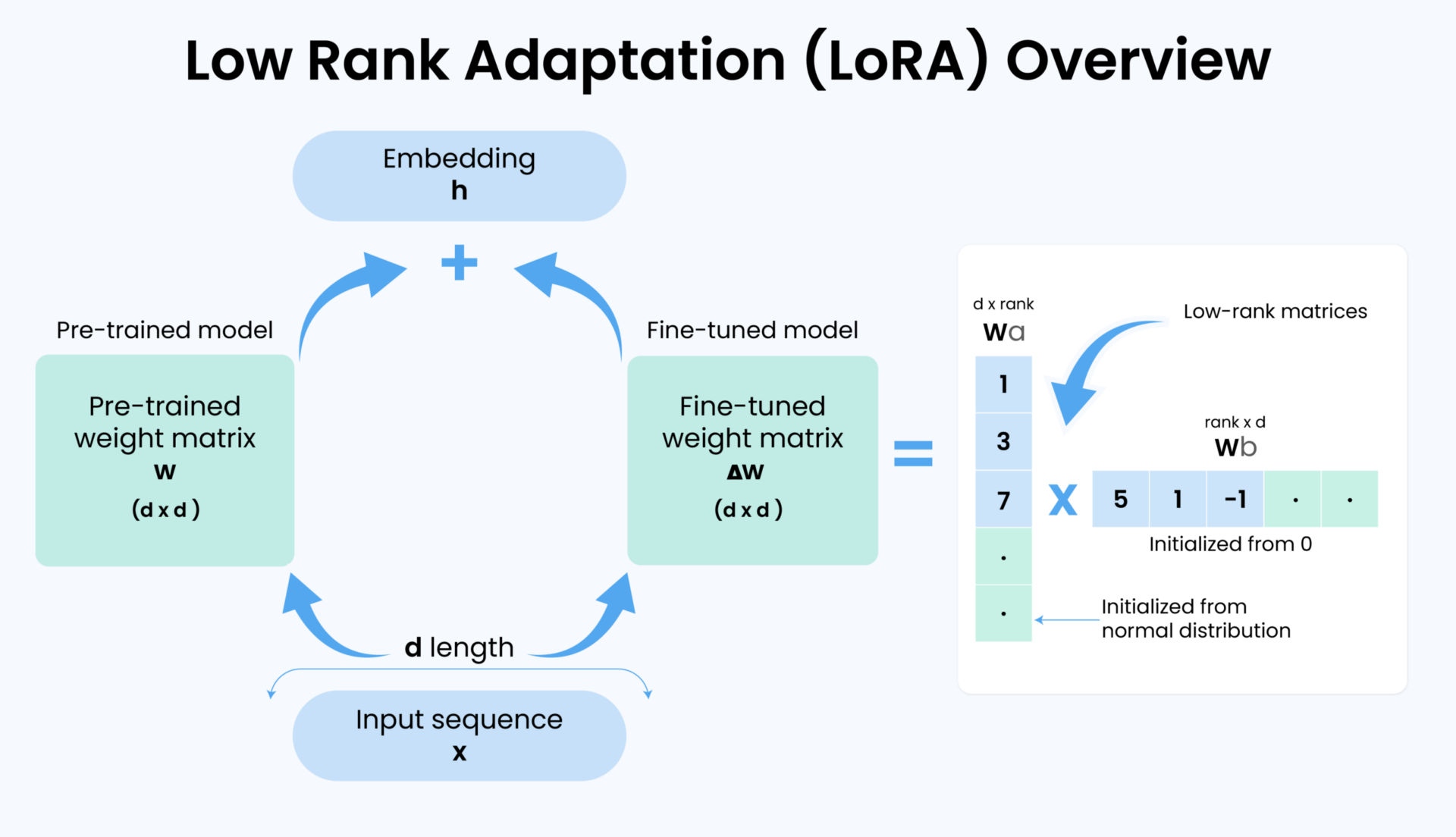
LoRA (Low-Rank Adaptation) reframes fine-tuning as a reparameterization problem. Instead of updating a full weight matrix 𝑊 W, we freeze it and learn a small update Δ 𝑊 ΔW that is constrained to be low-rank. This update is factorized into two thin matrices 𝐴 A and 𝐵 B, so that:
𝑊
𝑊 0 + 𝐵 𝐴 W=W 0
+BA
Only 𝐴 A and 𝐵 B are trained. The base model remains untouched.
The key insight is that many task-specific changes live in a much lower-dimensional subspace than the original weight matrix. LoRA exploits this redundancy directly, rather than discovering it implicitly through full fine-tuning.
Why the design works
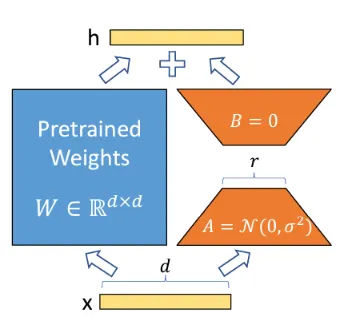
LoRA’s initialization is not accidental. Matrix 𝐴 A is randomly initialized (typically Gaussian), while matrix 𝐵 B starts at zero. At step zero, 𝐵 𝐴
0 BA=0, so the model behaves exactly like the pretrained model. Training then gradually introduces task-specific behavior without destabilizing early optimization.
This design gives LoRA three practical properties that matter in production:
The base model is preserved, reducing catastrophic forgetting.
Task switching is cheap: swap LoRA branches instead of models.
Inference can be latency-free, because 𝐵 𝐴 BA can be merged into 𝑊 W.
What LoRA is good at
LoRA shines when compute or memory is limited, but you still need strong task adaptation. It is especially effective for attention projections, where large matrices dominate parameter counts and gradient costs.
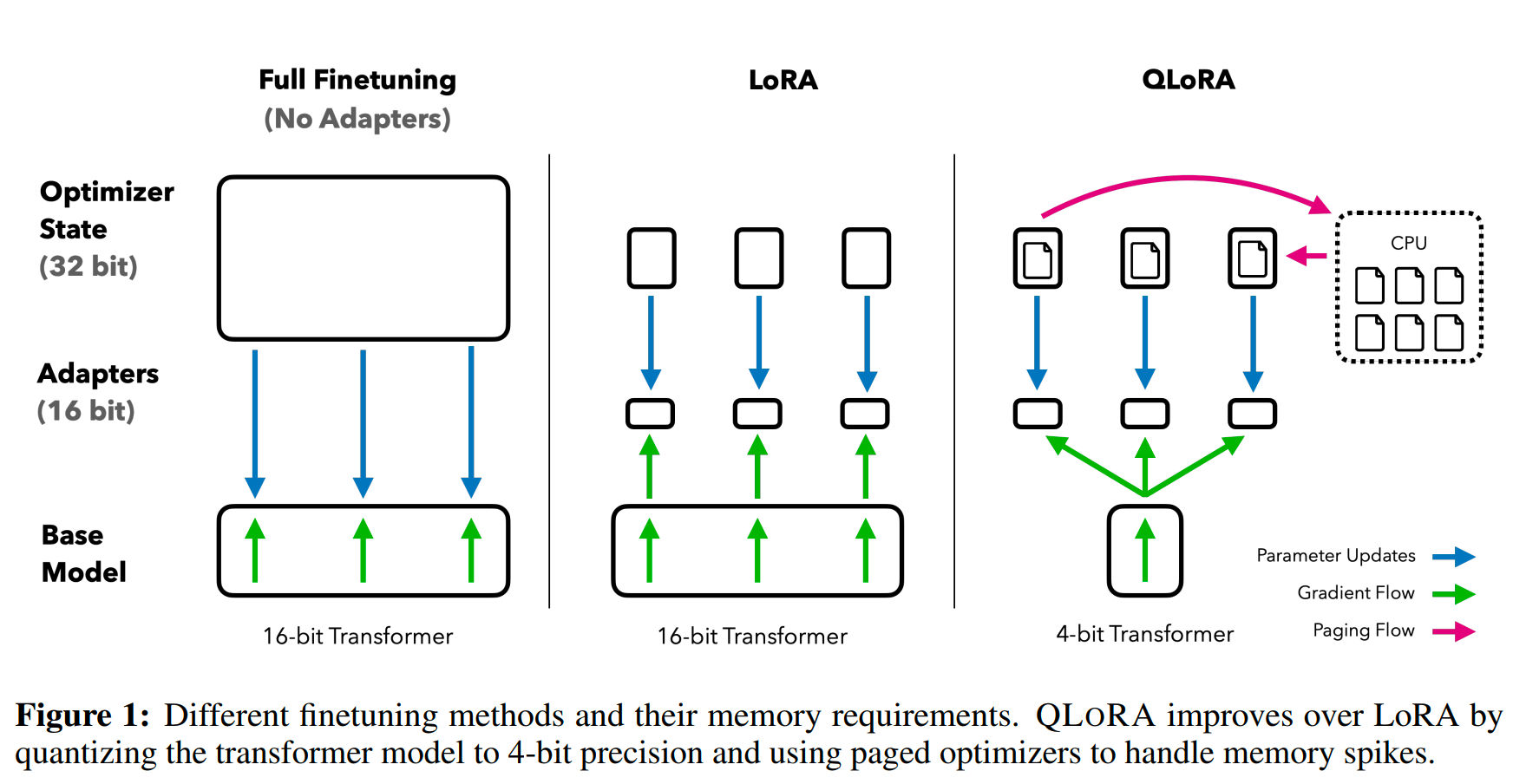
- QLoRA: When memory becomes the bottleneck
QLoRA answers a different question: What if the base model itself is too large to fit in memory during training?
Core idea
QLoRA combines two techniques:
4-bit quantization of the frozen pretrained model using a high-precision scheme (e.g. NF4),
LoRA adapters trained on top of this quantized backbone.
Gradients are backpropagated through quantized weights, but updates only affect the low-rank adapters. This allows fine-tuning models that would otherwise be impossible to load on a single GPU.
Why QLoRA matters
QLoRA doesn’t just save memory—it changes who can fine-tune large models. Researchers and small teams can now adapt multi-billion-parameter models with commodity hardware, without paying the instability cost that naïve quantization would introduce.
Importantly, QLoRA’s training speed is comparable to standard LoRA. The win is almost entirely in memory efficiency.
- AdaLoRA: Adapting the adaptation
Standard LoRA fixes the rank everywhere. AdaLoRA asks a deeper question: Do all layers deserve the same capacity?
Core idea
AdaLoRA dynamically reallocates rank during training. Layers that prove important for the task receive higher rank, while less critical layers are compressed more aggressively. This is conceptually similar to adaptive learning rates, but applied to model capacity instead.
Why this is interesting
AdaLoRA introduces a form of structural sparsity into adaptation. Instead of betting on a single global rank, it lets the model decide where expressive power is most valuable. This can reduce redundancy and improve performance under tight parameter budgets, at the cost of increased system complexity.
- Merging LoRA weights: training vs inference
Yes—LoRA weights can be merged.
After training, the low-rank update 𝐵 𝐴 BA can be added directly to the original weight matrix. Once merged, inference behaves exactly like a fully fine-tuned model, with no extra computation or latency. Multiple LoRA adapters can also be merged selectively, though each merge introduces a small amount of numerical noise.
This separation between training form and inference form is one of LoRA’s most underappreciated advantages.
- How many parameters are we really training?
As a concrete reference point, a ChatGLM-6B model with rank = 8 applied to query_key_value projections has on the order of 15 million LoRA parameters. That sounds large—until you compare it to 6 billion.
The parameter count depends on:
rank,
which modules are targeted,
and the shape of the original matrices.
This makes LoRA tunable not just as a method, but as a budgeted design choice.
- Why LoRA training is faster (and when it isn’t)
LoRA reduces training cost primarily by shrinking the number of trainable parameters. Fewer parameters mean:
lower gradient computation cost,
reduced optimizer state,
and less communication overhead in distributed setups.
However, LoRA does not magically make training free. The frozen backbone is still part of the forward pass. Training time drops, but not proportionally to parameter count.
LoRA’s real advantage is that it makes previously infeasible fine-tuning feasible.
- Continuing training on an existing LoRA
There are three common strategies:
Continue training the existing LoRA adapter.
Merge the LoRA into the base model, then train a new LoRA.
Discard and retrain from scratch.
In practice, merging before continued training is often safest, especially if the task distribution shifts. Mixing in some original training data helps reduce forgetting. Each merge, however, slightly perturbs the base weights, so repeated merges should be done thoughtfully.
- Limitations and trade-offs
LoRA is not a silver bullet. Its main drawbacks are:
performance can trail full fine-tuning,
parameter counts can still reach tens of millions,
and representational flexibility is constrained by rank.
For very large models, these trade-offs are often acceptable. For smaller models or highly specialized tasks, full fine-tuning may still win.
- LoRA vs full fine-tuning: a design choice, not a rule
Full fine-tuning rewrites the model. LoRA rewrites the delta.
If you have abundant data and compute, full fine-tuning remains the upper bound. LoRA exists because, in most real settings, we don’t. It is a method optimized for constraints, not for theoretical optimality.
- Where to apply LoRA in a Transformer
Empirically, spreading LoRA across multiple attention projections works better than concentrating it in a single matrix. Applying LoRA to both 𝑊 𝑞 W q
and 𝑊 𝑘 W k
often outperforms targeting only one. Even small ranks (4–8) capture much of the benefit.
The lesson here is architectural: adaptation benefits from distribution, not just capacity.
- Choosing rank and alpha in practice
Rank controls expressiveness; alpha controls scaling. A common and effective default is:
rank between 4 and 8,
alpha equal to rank.
Higher ranks rarely yield consistent gains and can introduce overfitting. Alpha usually does not need aggressive tuning unless training becomes unstable.
- Overfitting and regularization
LoRA can still overfit. Standard tools apply:
dataset size and diversity matter,
LoRA-specific dropout can help,
regularization is still relevant.
The smaller parameter space helps, but it does not eliminate generalization issues.
- Optimizers and large-model efficiency
Beyond Adam and AdamW, second-order-inspired optimizers like Sophia are gaining attention. By approximating Hessian information, they can stabilize and accelerate training—particularly appealing when every update must count.
- Memory usage: what actually matters
Memory consumption depends on:
model size,
batch size,
LoRA parameter count,
and sequence length.
Reducing sequence length is often the most overlooked but effective memory optimization.
- Per-layer rank: powerful, but rarely used
In theory, assigning different ranks per layer makes sense. In practice, it complicates training, tuning, and deployment. AdaLoRA explores this idea systematically, but most production systems prefer simpler, uniform configurations.
- Why LoRA initializes one matrix to zero
If both 𝐴 A and 𝐵 B were zero, gradients would vanish. If both were random, early training would inject noise and destabilize learning. Initializing only 𝐵 B to zero preserves pretrained behavior while allowing clean gradient flow.
This is a small detail with outsized impact—and a good reminder that stability is often engineered, not accidental.
Closing thought
LoRA and its variants are less about squeezing performance and more about changing the economics of adaptation. They show that, with the right constraints, small changes can unlock large capabilities. Once you internalize this idea, it generalizes far beyond language models—to vision, speech, and any system built on large pretrained backbones.
Understanding LoRA is ultimately about understanding where capacity really matters.
Comments (0)