LLMs 30. How to Use LoRA in the PEFT Library
Quick Overview
This deep-dive tutorial explains LoRA theory and practical usage within the PEFT library, covering conceptual motivations (separating knowledge from adaptation), LoraConfig parameters (rank, lora_alpha, dropout, target modules), model loading and quantization patterns (8-bit loading, prepare_model_for_int8_training), training memory and optimization trade-offs, and how these ideas generalize to QLoRA, AdaLoRA, and other adapter-style systems. It is targeted at Machine Learning Engineers implementing or evaluating parameter-efficient fine-tuning and deployment workflows and functions as a learning-first guide rather than a quick-start recipe.
LoRA in Practice: From Configuration to Deployment (PEFT Deep Dive)
This post is designed as a learning-first resource, not a quick-start recipe. The goal is to help you understand why LoRA works, how the PEFT library implements it internally, and where these ideas generalize to other parameter-efficient tuning and systems problems. If you grasp the concepts here, QLoRA, AdaLoRA, and even non-LLM adapter systems will feel far more intuitive.
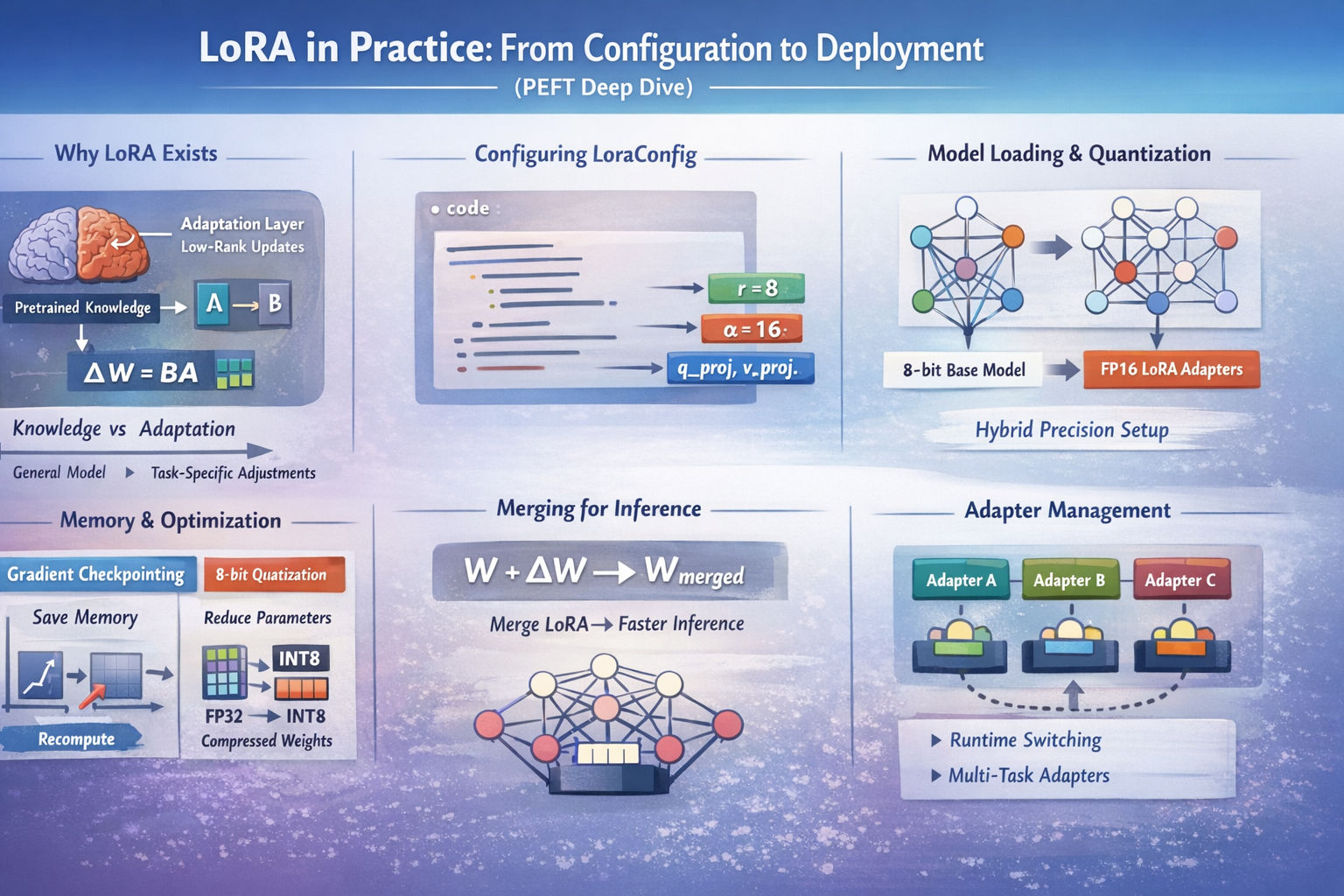
1. Why LoRA Exists (Beyond “Saving GPU Memory”)
LoRA (Low-Rank Adaptation) is often introduced as a way to fine-tune large models cheaply. That’s true, but incomplete. The deeper idea is separating knowledge from adaptation.
A pretrained LLM already encodes vast general knowledge. Most downstream tasks don’t require rewriting that knowledge; they require nudging how it is used. LoRA does this by constraining updates to a low-rank subspace, forcing the model to learn directional adjustments instead of wholesale rewrites.
This same idea shows up elsewhere:
- Low-rank updates in recommender systems
- Adapter layers in multilingual models
- Control vectors in representation steering
LoRA is not just a trick—it’s an architectural bias.
2. Configuring LoraConfig: What Actually Matters
A LoraConfig defines capacity, stability, and placement.
config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=["q_proj", "v_proj"],
bias="none",
task_type="CAUSAL_LM",
)
Instead of memorizing parameters, think in terms of roles:
Rank (r) controls expressive power. Smaller ranks enforce stronger regularization and faster convergence.
Scaling (lora_alpha) stabilizes optimization by normalizing updates across different ranks.
Target modules decide where learning is allowed. Attention projections are ideal because they shape token-to-token interaction.
Dropout protects against overfitting when data is limited.
A practical lesson: target module names are model-specific. Always inspect model.named_modules() before assuming defaults will work.
- Model Loading Is a First-Class Design Choice
Most LoRA issues originate before training even starts.
model = AutoModel.from_pretrained(
"THUDM/chatglm3-6b",
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model = prepare_model_for_int8_training(model)
This setup combines two ideas:
Quantized base weights to reduce static memory
Full-precision LoRA weights to preserve learning capacity
The result is a hybrid system: frozen knowledge in compressed form, adaptation in high precision. This pattern appears again in QLoRA, optimizer sharding, and even retrieval-augmented systems where memory and compute are asymmetric.
- Where Memory Is Really Spent During Training
Training memory has two very different sources:
Static memory: model parameters
Dynamic memory: intermediate activations for backpropagation
LoRA reduces the trainable parameter set, but PEFT goes further by enabling:
8-bit quantization → static memory reduction
Gradient checkpointing → dynamic memory reduction
This explains an important observation: even with LoRA, batch size often remains the bottleneck. LoRA is not magic—it just shifts the constraint.
- Two Key Optimization Techniques 5.1 8-bit Quantization
Using bitsandbytes, FP16/FP32 weights are stored as INT8. Quantization relies on scaling values so the largest magnitude maps to 127. To avoid large errors, extreme outliers are kept in higher precision.
A crucial nuance: this quantization is about storage, not learning. LoRA parameters are never quantized.
This separation—compressed storage, precise updates—is a recurring theme in large-scale systems.
5.2 Gradient Checkpointing
Gradient checkpointing trades compute for memory. Instead of storing activations, it recomputes them during backpropagation.
The cost:
Slower training
Double forward computation
The benefit:
Dramatically lower memory usage
Because cached activations conflict with this strategy, use_cache must be disabled. This is why PEFT explicitly sets it to False.
- How PEFT Injects LoRA into a Model
Calling get_peft_model() does more than “add adapters”.
model = get_peft_model(model, config)
model.config.use_cache = False
Internally, PEFT:
Scans the model for target layers
Replaces them with LoRA-augmented versions
Freezes all original parameters
Keeps only LoRA weights trainable
Conceptually, PEFT rewrites the computation graph while preserving the original semantics. This pattern is similar to graph rewriting in compilers and differentiable programming frameworks.
- Inside the LoRA Layer Design
Each LoRA layer decomposes a weight update as:
Δ 𝑊
𝐵 𝐴 ΔW=BA
A: projects inputs into a low-rank space
B: projects back to output space
Base weight W: frozen
Initialization is intentional:
A uses Kaiming initialization
B is initialized to zero
This guarantees the model starts identical to the base model at step zero. Learning begins only through the adapter.
This is a subtle but powerful stability trick.
- Training vs Inference: Why Merging Exists
During training, LoRA updates are applied dynamically. During inference, those updates can be merged into the base weights.
This:
Removes extra matrix multiplications
Reduces latency
Produces a standard Transformers model
The PEFT implementation carefully tracks merge state to avoid numerical drift. The same logic is triggered during eval() because PyTorch internally calls train(False).
This design mirrors compiler optimizations: dynamic behavior during development, static fusion for deployment.
- Saving LoRA Models Correctly
PeftModel.save_pretrained() saves only LoRA weights, which is what you want.
However, Hugging Face’s Trainer.save_model() does not automatically respect this. If you resume training from checkpoints, you may accidentally save full base weights unless you override the saving logic.
This distinction matters in:
Long-running jobs
Distributed training
Storage-constrained environments
- Inference Strategies with LoRA
There are two valid deployment paths:
Runtime injection Flexible, slower, ideal for experimentation or adapter switching.
Merged weights Faster inference, simpler deployment, less flexible.
Choosing between them is a systems decision, not a modeling one.
- Multiple Adapters and Runtime Switching
PEFT allows multiple LoRA adapters to coexist in a single model and be switched dynamically.
This enables:
Multilingual specialization
Task-specific personalities
Controlled comparisons without reloading models
Adapters can be enabled, disabled, or merged on demand, turning LoRA into a modular specialization layer rather than just a fine-tuning trick.
- Transferable Ideas Beyond LoRA
What you should carry forward from this:
Low-rank constraints are an inductive bias, not just an optimization
Separating base knowledge from adaptation improves modularity
Memory, compute, and deployment constraints shape model design
Many “training tricks” are really systems tradeoffs
If you understand LoRA at this level, you are not just learning a library—you are learning how modern large models are engineered under real constraints.
If you want next:
- a one-page mental model summary
- a PEFT vs Full Fine-Tuning comparison
- or a LoRA → QLoRA → AdaLoRA conceptual bridge
Just tell me.
Comments (0)