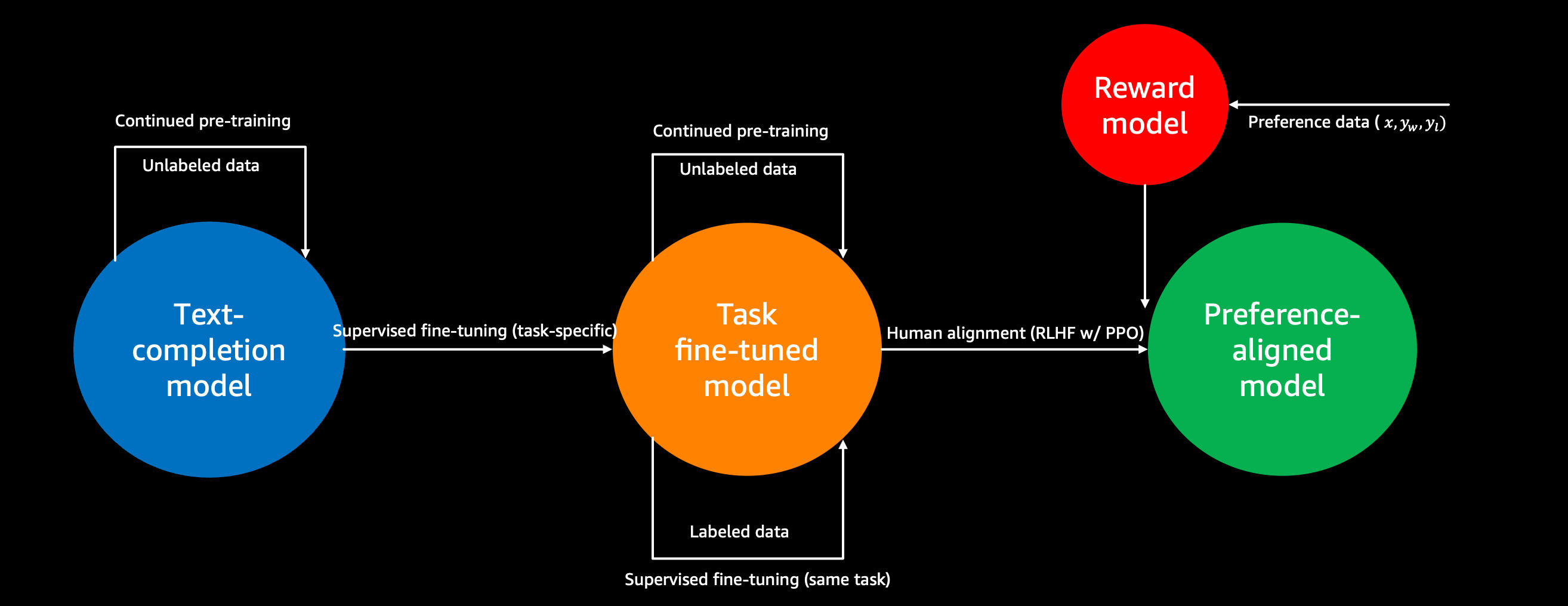
LLMs 34. LoRA-Based Continued Pretraining for LLaMA 2
Quick Overview
This conceptual guide explains LoRA-based continued pretraining for LLaMA 2, covering distributional adaptation, intrinsic dimensionality, low-rank parameter updates, and practical implications for stability, overfitting, hardware requirements, and cost.
LoRA-Based Continued Pretraining for LLaMA 2
A Learning-Oriented Resource for Understanding Why, When, and How It Works
This post is written as a conceptual learning resource, not just a how-to manual. The goal is to help you understand why LoRA-based continued pretraining exists, what problem it actually solves, and how these ideas transfer to other models, languages, and domains. Code and parameters matter, but they only make sense once the learning objective is clear.
1. Why Continued Pretraining with LoRA Matters
LLaMA 2 is trained primarily on English-centric data. While it has some multilingual capacity, its internal representations are still biased toward the data distribution it saw during pretraining. Continued pretraining allows us to reshape the model’s linguistic priors without starting from scratch.
When we introduce large-scale Chinese text and continue pretraining, the model does not merely “learn vocabulary.” Instead, it adapts deeper structures: syntax expectations, discourse patterns, idiomatic phrasing, and long-range dependencies specific to Chinese. This is fundamentally different from instruction tuning, which focuses on behavior rather than linguistic grounding.
LoRA makes this process feasible by dramatically reducing cost. Without LoRA, continued pretraining would require updating billions of parameters. With LoRA, we inject a small number of trainable parameters and let them steer the model in a new direction.
2. What Is the Objective of LoRA-Based Continued Pretraining?
The objective is distributional adaptation, not task alignment.
Continued pretraining aims to shift the base model closer to a new data distribution (e.g., Chinese classical literature) while preserving its general reasoning and world knowledge. This is why it happens before instruction fine-tuning.
LoRA enables this by:
- keeping the original pretrained weights frozen,
- learning only low-rank updates,
- and achieving effects similar to full-parameter training with far fewer trainable parameters.
From a learning perspective, this is equivalent to saying:
Most of what the model knows is still useful; we only need to adjust a small set of directions in parameter space.
3. The Core Idea: Intrinsic Dimensionality
Research on intrinsic dimensionality shows that although modern LLMs have billions of parameters, the space of meaningful updates is surprisingly small. Only a low-dimensional subspace strongly influences model behavior.
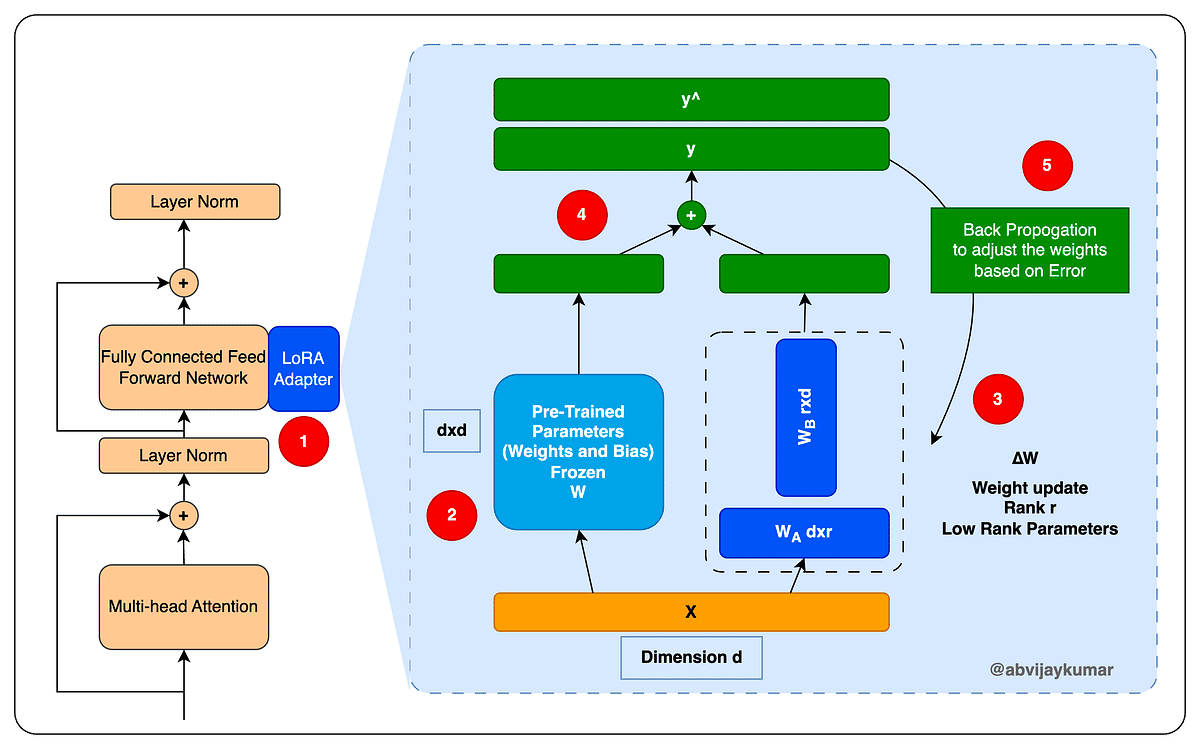
LoRA exploits this observation by decomposing weight updates as:
[ W = W_0 + \Delta W,\quad \Delta W = B A ]
Instead of learning a full matrix update, we learn two low-rank matrices. This has several implications:
- Learning becomes more stable.
- Overfitting risk is reduced.
- Hardware requirements drop dramatically.
- Continued pretraining becomes accessible on modest GPUs.
This idea generalizes well beyond LLaMA 2. Any pretrained transformer with stable representations can benefit from low-rank adaptation.
4. Data Preparation Is the Real Bottleneck
In continued pretraining, data quality matters more than labels.
The Chinese classical literature corpus used here provides:
- long-form, high-quality text,
- rich narrative and philosophical structure,
- minimal noise compared to web data.
Such data is ideal for continued pretraining because it strengthens long-context modeling and language fluency without introducing alignment artifacts.
A key insight here is that continued pretraining data does not need instructions or responses. Raw text is enough—as long as it reflects the linguistic distribution you want the model to internalize.
5. How LoRA-Based Continued Pretraining Works in Practice
At a high level, the process looks like this:
- Load a pretrained LLaMA 2 model.
- Inject LoRA adapters into selected transformer layers.
- Freeze all original weights.
- Train only the LoRA parameters on large-scale unlabeled text.
The most common choice is to apply LoRA to attention and MLP projection layers (q_proj, v_proj, k_proj, o_proj, etc.), because these layers dominate representational flow.
What matters most here is not the script, but the training regime:
- relatively small batch sizes,
- long training horizons,
- stable learning rates,
- and strong regularization via low-rank constraints.
6. Continued Pretraining vs Instruction Fine-Tuning
It is important to distinguish these two stages conceptually.
Continued pretraining changes what the model understands at a linguistic level.
Instruction fine-tuning changes how the model behaves when interacting with users.
This is why the pipeline often looks like:
- Base pretraining (English-heavy)
- LoRA-based continued pretraining (Chinese corpus)
- LoRA-based instruction tuning (Chinese Alpaca-style data)
- Optional RLHF
Skipping step (2) often leads to brittle behavior in non-English settings, even if instruction tuning is applied.
7. Why LoRA Works Especially Well for Multilingual Adaptation
Language adaptation is a near-ideal use case for LoRA because:
- grammar and syntax changes are structured,
- vocabulary expansion affects embeddings and attention patterns,
- and the base reasoning abilities remain largely intact.
LoRA allows the model to “bend” toward a new language without overwriting its core knowledge. This is why LoRA-based Chinese LLaMA variants often outperform full fine-tuning under the same compute budget.
8. Transferable Lessons Beyond LLaMA 2
Understanding LoRA-based continued pretraining gives you tools that apply broadly:
- Domain adaptation (legal, medical, financial text)
- Low-resource language modeling
- Long-context specialization
- Efficient model personalization
- On-device or private fine-tuning workflows
The deeper lesson is that model adaptation is about steering, not rebuilding. LoRA gives us a principled way to do exactly that.
Final Takeaway
LoRA-based continued pretraining is not just a cost-saving trick. It is a reflection of a deeper truth about large models:
Most of their intelligence already exists; adaptation is about finding the right low-dimensional direction.
Once you understand this, the long lists of parameters and scripts stop feeling overwhelming—and start feeling like precise tools for shaping model behavior.
Comments (0)