LLMs 35. Large Language Models (LLMs) — Evaluation
Quick Overview
This guide covers evaluation of large language models, including why traditional benchmarks fall short, capability-focused evaluation for reasoning and multi-turn dialogue, honesty and calibration, and interaction-based measurement approaches.
Evaluating Large Language Models: From Benchmarks to Real Capability
This post is written as a learning-oriented resource for understanding how large language models (LLMs) should be evaluated, why traditional benchmarks fall short, and how modern evaluation thinking has shifted from static scores to dynamic, interaction-based judgment. The goal is not to list metrics, but to help you build a mental model of evaluation that transfers across research, product, and real-world deployment.
1. Why Evaluating LLMs Is Fundamentally Different
Early NLP models were evaluated on narrow, well-defined tasks: classification accuracy, BLEU scores, exact match. Benchmarks like GLUE, SuperGLUE, and CLUE reflect this era. They work well for measuring isolated skills, but large language models are no longer isolated systems.
LLMs are general-purpose reasoning and interaction engines. They reason across domains, handle ambiguity, adapt mid-conversation, and generate long-form outputs. This makes traditional benchmarks increasingly misaligned with what we actually care about.
The core shift is this:
LLM evaluation is less about task correctness and more about capability, robustness, and behavior over time.
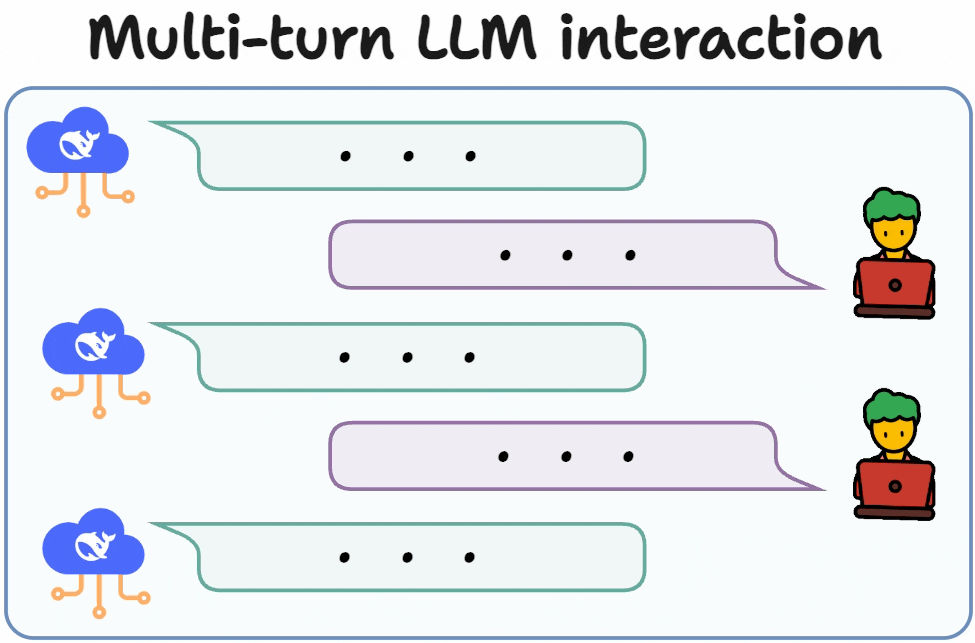
2. Why Reasoning and Multi-Turn Dialogue Matter Most
For LLMs, two abilities dominate practical usefulness:
Reasoning ability, which includes logical inference, abstraction, multi-step thinking, and problem decomposition.
Multi-turn dialogue capability, which reflects whether the model can maintain context, update beliefs, correct mistakes, and stay coherent over long interactions.
A model that scores well on single-turn QA but fails to reason consistently or collapses over multiple turns is not reliable in real applications. This is why modern evaluation increasingly emphasizes dialogue and reasoning rather than static question answering.
3. The “Honesty” Principle: What It Really Means
Large models are expected to be helpful, honest, and harmless. Honesty is often misunderstood as a moral property, but in practice it is a training and evaluation constraint.
Honesty means the model should:
- Answer correctly when it has reliable knowledge.
- Explicitly acknowledge uncertainty when it does not.
- Avoid fabricating facts or pretending to know.
This ability is not innate. It is trained deliberately by constructing datasets where:
- Known questions are paired with correct answers.
- Unknown or unanswerable questions are paired with explicit responses like “I don’t know” or “This information is not available.”
From a learning perspective, honesty is about calibration. The model must learn to align confidence with actual knowledge coverage. This concept generalizes to many domains, including safety alignment, uncertainty estimation, and decision-making under incomplete information.
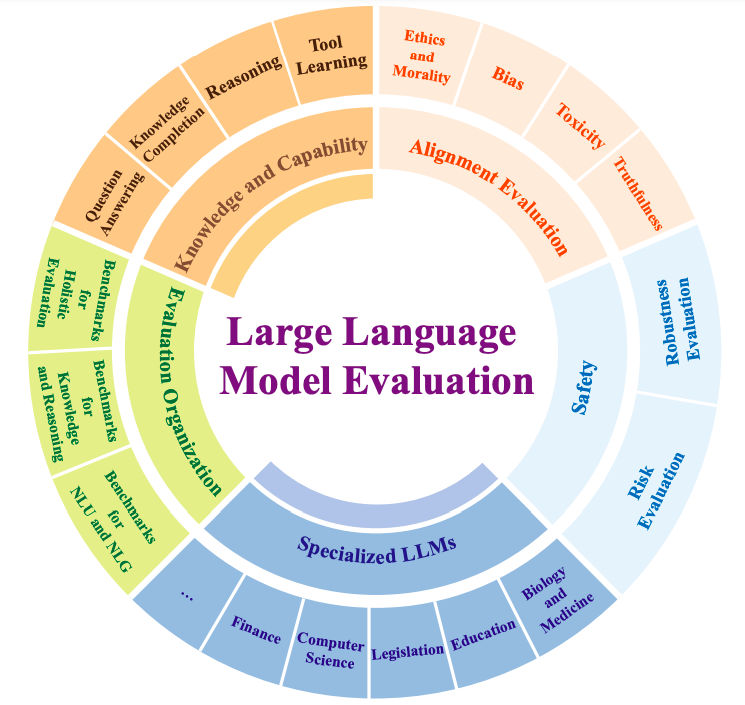
4. Measuring Overall Capability: Thinking in Dimensions, Not Scores
There is no single number that captures an LLM’s ability. Instead, evaluation must span multiple dimensions that reflect real usage.
A strong LLM demonstrates balanced performance across:
- Comprehension, showing deep understanding rather than surface pattern matching.
- Language generation, producing coherent, structured, and grammatically sound text.
- Knowledge coverage, answering questions across diverse domains with depth.
- Adaptability, switching smoothly between tasks like writing, translation, and coding.
- Long-context understanding, maintaining coherence over long inputs.
- Long-form generation, sustaining logical and narrative structure across extended outputs.
- Diversity, offering multiple valid solutions rather than collapsing to one pattern.
- Sentiment and inference, understanding tone, emotion, and implicit relationships.
- Emotional expression, generating text that matches human emotional nuance.
- Logical reasoning, handling deductive and inductive reasoning tasks correctly.
- Problem-solving, solving math, algorithmic, or practical problems reliably.
- Ethics and values, responding safely and thoughtfully to moral questions.
- Dialogue quality, engaging in natural, coherent, and context-aware conversations.
What matters is not perfection in one dimension, but consistency across many.
5. Why LLM Evaluation Is Harder Than It Looks
Several structural challenges make LLM evaluation difficult.
First, data contamination is almost unavoidable. Large models may have seen large portions of the internet, making it hard to guarantee that evaluation data is truly unseen.
Second, subjectivity plays a major role. Conversation quality, helpfulness, and coherence are difficult to score numerically.
Third, gaming the benchmark is easy. Models can be fine-tuned to perform well on specific evaluation sets without improving general capability.
These issues explain why many academic benchmarks fail to reflect real-world performance, especially for chatbots and assistants.
6. Modern Evaluation Methods: Humans, Models, and Arenas
Evaluation methods for LLMs now fall into three broad categories.
Human evaluation remains the gold standard for assessing usefulness, coherence, and alignment. Datasets like LIMA and Phoenix rely heavily on human judgment, but this approach is expensive and slow.
Automated evaluation with LLMs as judges uses strong models (e.g., GPT-4) to score or compare outputs. Projects like Vicuna, BELLE, and Chimera adopt this approach, sometimes using traditional metrics like BLEU or ROUGE as auxiliary signals. While scalable, these methods inherit biases from the judge model.
Interactive comparison systems, such as Chatbot Arena, take a fundamentally different approach. Instead of scoring against a fixed dataset, models are compared head-to-head in live conversations. Human users judge which response is better, and an Elo-style rating system aggregates results.
This approach acknowledges a key truth: conversation quality is relative, not absolute.
7. Evaluation Tools and Frameworks
Several tools formalize these ideas.
OpenAI Evals provides a prompt-driven evaluation framework, allowing automated, repeatable testing across many tasks.
PandaLM trains a dedicated evaluator model to score outputs using a simple ordinal scale, focusing on relative quality rather than absolute correctness.
These tools reflect a broader trend: evaluation itself is becoming a learned system, not just a static script.
8. Transferable Lessons Beyond LLMs
The ideas behind LLM evaluation apply far beyond language models.
- Complex systems cannot be evaluated by single metrics.
- Interaction quality often matters more than task accuracy.
- Relative comparisons are often more informative than absolute scores.
- Honesty and calibration are as important as raw capability.
- Evaluation must evolve alongside system capability.
These principles appear in recommender systems, autonomous agents, robotics, and even human performance evaluation.
Final Perspective
Evaluating large language models is no longer about passing tests—it is about understanding behavior under uncertainty, interaction, and scale.
The most important shift is conceptual:
we are moving from benchmark-driven evaluation to experience-driven evaluation.
Once you internalize this shift, evaluation stops being an afterthought and becomes a core part of designing intelligent systems.
Comments (0)