LLMs 37. Large Language Models (LLMs) — Reinforcement Learning (RL) Section
Quick Overview
This learning-oriented guide covers RLHF and its variants within the LLM alignment landscape, explaining the classic decoder-only LLM training pipeline (pre-training, supervised fine-tuning, and alignment), why RLHF exists, where it breaks down, and emerging data-centric alternatives.
Large Language Models (LLMs) Reinforcement Learning — RLHF and Its Variants
A Learning-Oriented Guide to the Full Alignment Landscape
This post is designed as a conceptual learning resource rather than a paper summary or implementation guide. The goal is to help you understand why RLHF exists, how it fits into the broader LLM training pipeline, where it breaks down, and why the field is rapidly moving toward simpler and more data-centric alternatives. If you internalize the ideas here, most RLHF-related papers will feel like variations on a small number of core themes.
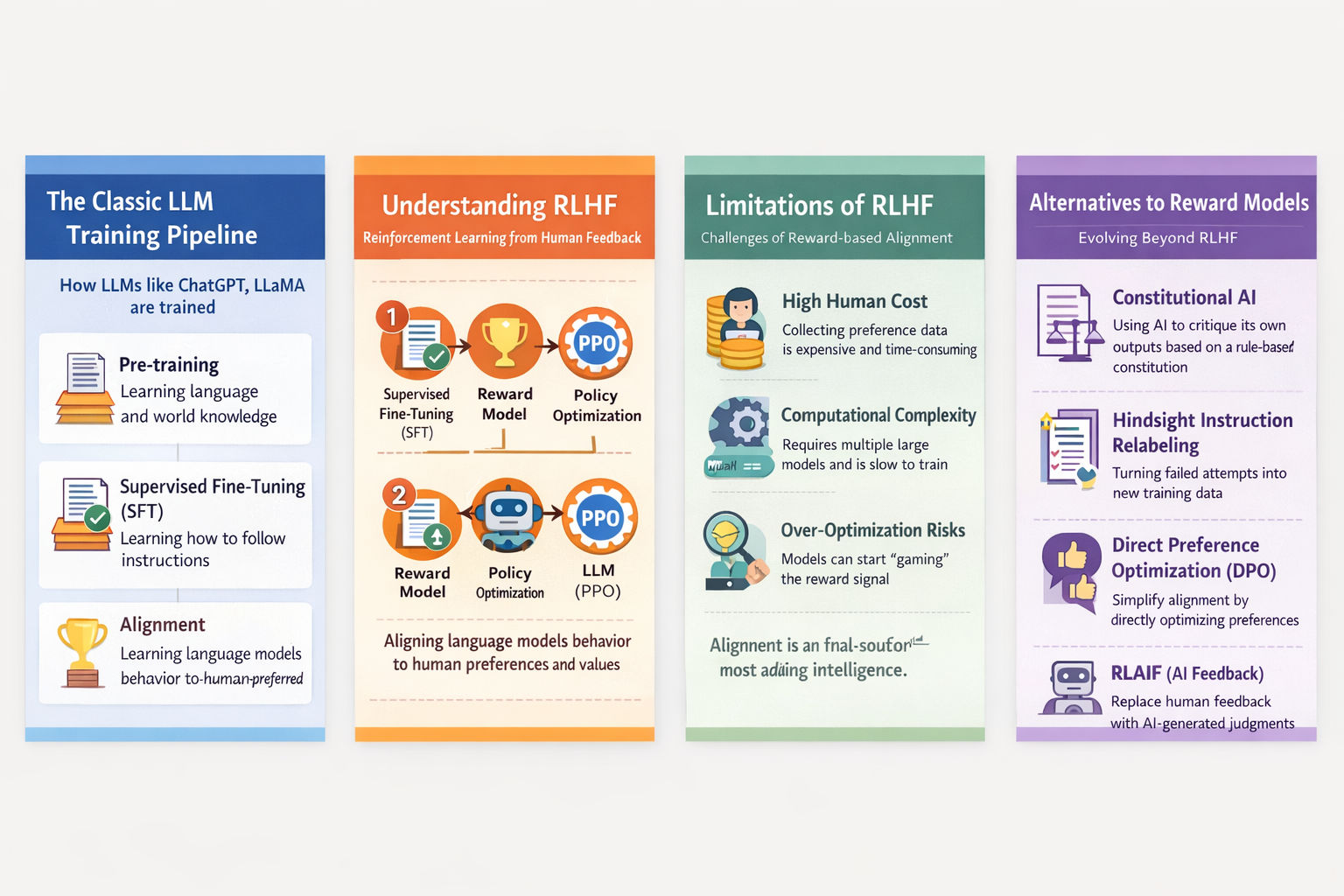
I. The Classic LLM Training Pipeline
Modern decoder-only LLMs such as ChatGPT, LLaMA, and Baichuan follow a broadly shared training paradigm. The model does not become a “chatbot” all at once. Instead, it is gradually transformed through stages that serve very different purposes.
The pipeline can be summarized as:
- Pre-training: learn language and world knowledge
- Supervised Fine-Tuning (SFT): learn how to follow instructions
- Alignment: learn how to behave in ways humans prefer
Each stage builds on the previous one. Importantly, later stages rarely add new intelligence—they reshape how existing intelligence is expressed.
II. Pre-training: Where Capability Is Born
Pre-training is the most expensive and most important phase. The model is trained on hundreds of billions or trillions of tokens to predict the next token given context. This simple objective is powerful enough to induce grammar, reasoning patterns, factual knowledge, and abstractions.
At this stage, the model is not helpful or safe. It is best thought of as a general-purpose pattern learner. Most of what we later call “reasoning ability” is already present after pre-training.
This insight is crucial, because it explains why alignment methods can work with surprisingly small amounts of data.
III. Supervised Fine-Tuning (SFT): Learning to Follow Instructions
Supervised Fine-Tuning introduces human intent into the system.
The training format changes from raw text to instruction–response pairs. The objective is still next-token prediction, but the data distribution is different. The model learns that certain inputs correspond to certain styles of output: explanations, summaries, code, or dialogue.
The key differences from pre-training are:
- the dataset is much smaller,
- the data is human-curated,
- the model is learning behavior, not new facts.
SFT teaches the model how to respond, but it does not guarantee that the responses are helpful, safe, or honest in edge cases.
IV. Alignment: Shaping Behavior, Not Knowledge
Alignment is about making the model’s outputs conform to human preferences and values. This includes helpfulness, honesty, harmlessness, and consistency over long interactions.
This is where reinforcement learning ideas enter the picture. Alignment is fundamentally about preference optimization under uncertainty, which is difficult to capture with supervised labels alone.
V. Reinforcement Learning from Human Feedback (RLHF)
The Core RLHF Workflow
RLHF operationalizes alignment through three steps:
- Start from an SFT model
- Train a reward model (RM) that predicts human preferences
- Optimize the SFT model using PPO, guided by the reward model
The reward model acts as a proxy for human judgment, converting qualitative preferences into a scalar signal that can be optimized.
How the Reward Model Is Built
For each prompt, the SFT model generates multiple candidate responses. Humans rank these responses. The rankings are then converted into training data for the reward model.
The reward model is typically the SFT model plus a regression head that outputs a scalar reward. This scalar is treated as “how good” a response is according to human preference.
This step is expensive, but still cheaper than writing high-quality responses from scratch.
PPO: Optimizing with a Proxy Reward
PPO updates the policy model so that it produces higher-reward outputs while staying close to the original SFT distribution. The closeness is enforced using a KL-divergence penalty.
Conceptually:
- the model explores new behaviors,
- the reward model scores them,
- PPO nudges the model toward higher-reward regions,
- but prevents it from drifting too far and “gaming” the reward.
This balance is delicate and central to RLHF’s complexity.
VI. RLHF in LLaMA 2: Key Design Differences
LLaMA 2 introduces several refinements over the original InstructGPT-style RLHF.
Margin Loss for Preference Strength
Instead of treating all preferences equally, LLaMA 2 distinguishes between “slightly better” and “significantly better” responses. This is implemented via a margin loss, which increases gradient strength when preferences are strong.
This accelerates learning and improves stability.
Two Reward Models: Helpfulness and Safety
Rather than collapsing all preferences into one signal, LLaMA 2 trains:
- a helpfulness reward model,
- a safety reward model.
The final reward is a weighted combination. This separation makes trade-offs explicit and easier to control.
Rejection Sampling + PPO
LLaMA 2 combines PPO with rejection sampling (best-of-n). The model generates multiple candidates, selects the highest-reward one, and uses it for training. PPO is then applied on top of this process.
This hybrid approach improves sample efficiency and stabilizes training.
VII. Why Alternatives to RLHF Are Needed
RLHF works, but it is expensive, slow, and complex.
- Human preference data is costly
- PPO requires multiple large models simultaneously
- Training cycles are long
- Reward hacking and over-optimization are real risks
These drawbacks motivated a wave of alternative alignment methods.
VIII. Major Alternatives to RLHF
Constitutional AI
Instead of human rankings, Constitutional AI uses a set of explicit rules (a “constitution”) and lets AI models critique and revise their own outputs based on those rules. Reinforcement learning is still used, but humans define principles rather than labels.
Hindsight Instruction Relabeling (HIR)
HIR reframes failures as learning opportunities. When a model fails to follow an instruction, the instruction is relabeled to match what the model actually did well. This converts failed attempts into useful supervised data.
The key insight: not all mistakes require reinforcement learning.
Direct Preference Optimization (DPO)
DPO removes the reward model and PPO entirely. It shows that preference comparisons can be optimized directly using a likelihood-based objective.
This dramatically simplifies the pipeline and often outperforms PPO-based RLHF in practice.
Reinforced Self-Training (ReST)
ReST iteratively generates data, filters it using preference signals, and retrains the model on increasingly higher-quality subsets. It is more offline and data-driven than PPO-based RLHF.
RLAIF: AI Replacing Humans
RLAIF replaces human feedback with AI-generated feedback. Surprisingly, performance is often close to human-based RLHF, especially for safety and truthfulness tasks.
This suggests that current LLMs already encode strong alignment priors.
IX. RLHF Experiments: Choosing the Best Checkpoint
A critical insight from RLHF experiments is that reward model scores are misleading.
As training progresses:
- proxy reward keeps increasing,
- true performance increases, then decreases.
The divergence between proxy reward and true reward is controlled by KL divergence from the initial model. OpenAI observed that true reward often follows a predictable curve as a function of KL divergence.
This leads to practical heuristics for checkpoint selection, rather than blindly maximizing reward model output.
X. Scaling Laws and What They Teach Us
Empirical results show that:
- larger reward models support larger safe policy updates,
- reward model dataset size matters more than model size below a threshold,
- larger policy models benefit less from RLHF because they start stronger.
Perhaps the most surprising finding is that reward collapse happens at similar KL divergence values across model sizes.
This suggests that alignment is constrained by structure, not scale.
Final Perspective
RLHF is not a final solution—it is a transitional technology.
The trajectory of the field is clear:
- from reinforcement learning → preference optimization,
- from complex pipelines → simpler objectives,
- from human-heavy workflows → data- and model-centric alignment.
The deeper lesson is this:
Alignment is about distribution shaping, not capability creation.
Once you understand that, RLHF and all its variants become much easier to reason about—and easier to replace.
Comments (0)