LLMs 39. Reinforcement Learning Applications in Natural Language Processing
Quick Overview
This conceptual tutorial covers reinforcement learning fundamentals and their application to natural language processing and large language models, including states and observations, discrete action spaces, stochastic versus deterministic policies, policy-gradient methods, and a learning-oriented path from first principles to PPO and RLHF.
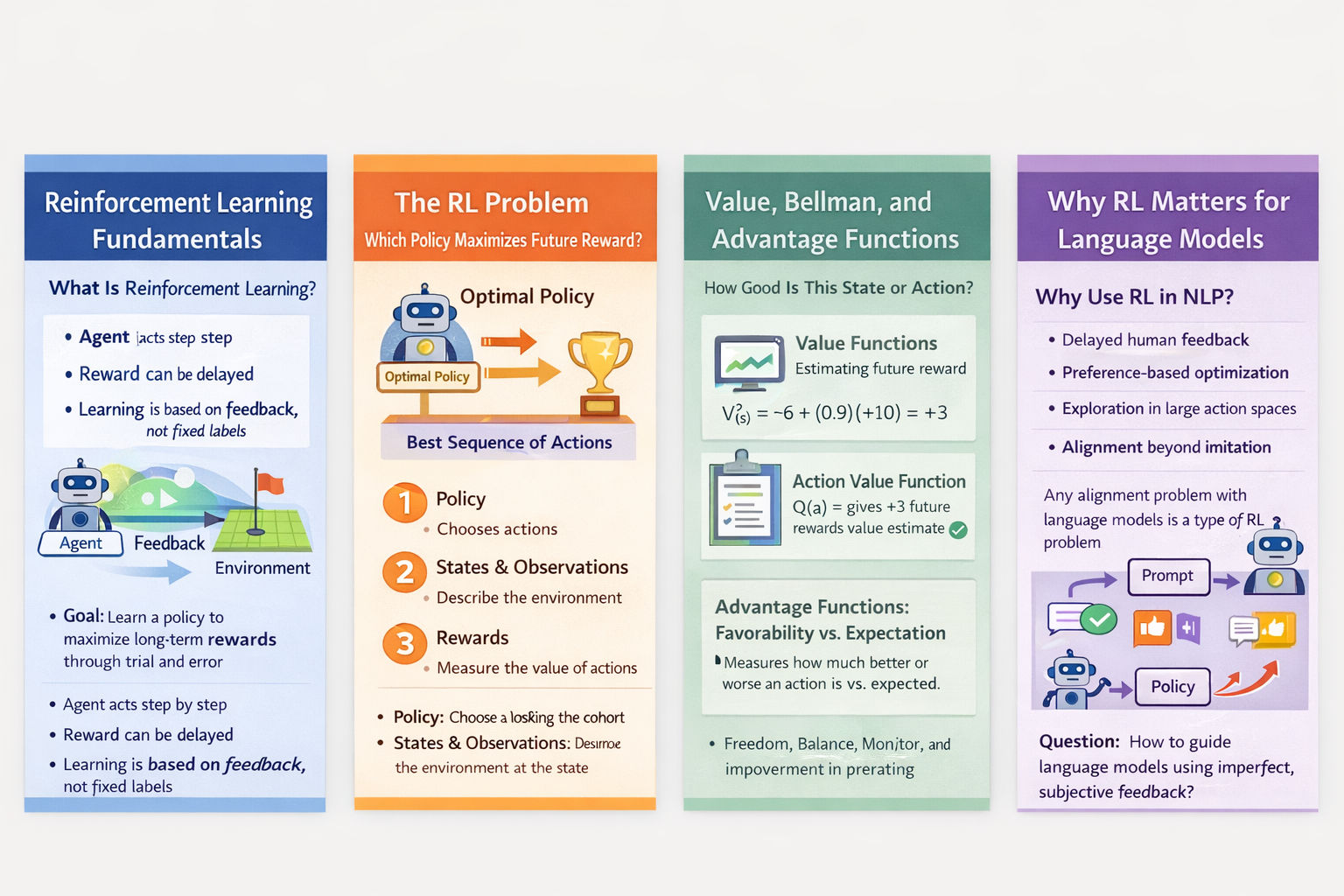
Reinforcement Learning Applications in Natural Language Processing
A Learning-Oriented Path from First Principles to PPO
This post is written as a conceptual learning resource for candidates who want to truly understand reinforcement learning (RL) as it applies to NLP and large language models, rather than memorizing formulas in isolation. The emphasis here is on building intuition that naturally leads toward PPO and modern LLM alignment methods such as RLHF.
I. Reinforcement Learning Fundamentals
What Is Reinforcement Learning?
Reinforcement Learning is a time-dependent decision-making framework. An agent interacts with an environment step by step, choosing actions according to a policy and receiving feedback in the form of rewards. Unlike supervised learning, there are no explicit “correct labels.” The agent must learn by experiencing the consequences of its actions over time.
At each time step, the agent observes the environment, takes an action, and receives a reward. The goal is not to maximize immediate reward, but to learn a policy that maximizes long-term cumulative reward.
This framing is particularly powerful for NLP tasks where quality is subjective, delayed, or only observable after an entire response is generated.
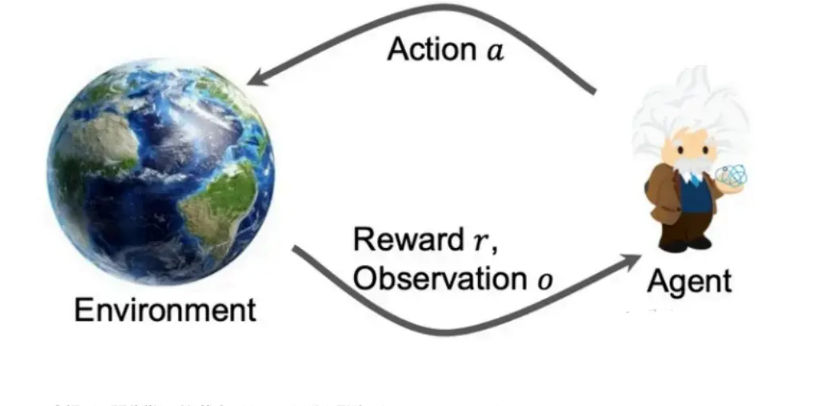
States and Observations: What the Agent Actually Sees
In theory, a state is a complete description of the environment at a given moment. In practice, agents often only receive an observation, which may be incomplete or noisy.
If the observation fully captures the state, the environment is fully observable. If not, the agent must act under uncertainty. Language modeling almost always falls into the partially observable category: the model never sees the “true” human intent or preference, only textual signals that approximate it.
This partial observability is one reason why RL in NLP is fundamentally harder than in board games or simulations.
Action Spaces: Why Language Is Special
Reinforcement learning problems differ greatly depending on the action space.
In NLP, the action space is discrete and extremely large: each token selection is an action. This is very different from robotics or control tasks, where actions are continuous values.
The discrete nature of language makes policy design, exploration, and credit assignment significantly more challenging, and is one reason policy-gradient methods dominate NLP reinforcement learning.
Policies: Deterministic vs Stochastic
A policy defines how an agent chooses actions.
A deterministic policy always selects the same action in a given state. These are common in continuous control.
A stochastic policy, by contrast, samples actions from a probability distribution. This is the standard choice for NLP, where diversity, exploration, and uncertainty are essential.
Large language models are naturally stochastic policies: given a context, they produce a probability distribution over possible next tokens.
Trajectories: The Unit of Experience
A trajectory is a complete sequence of states and actions produced by the agent during interaction with the environment. It represents a single “experience” of acting in the world.
In NLP, a trajectory often corresponds to an entire generated response. Importantly, rewards are usually assigned to the whole trajectory, not to individual tokens. This delayed feedback makes learning more difficult and increases variance.
Reward Functions: What the Agent Is Actually Optimizing
The reward function defines what the agent is encouraged to do. Rewards may depend on the current state, the action taken, or the resulting next state.
The agent’s objective is to maximize discounted cumulative reward, meaning that near-term rewards are usually weighted more heavily than distant ones.
In language tasks, rewards often approximate human preferences—helpfulness, correctness, safety, tone—rather than objective correctness. This makes reward design one of the hardest problems in RL for NLP.
The Reinforcement Learning Problem
At its core, reinforcement learning asks a single question:
Which policy maximizes expected cumulative reward?
Mathematically, this means choosing a policy that maximizes the expected return over all possible trajectories induced by that policy. Everything else—value functions, Bellman equations, advantage estimates—exists to make this optimization tractable.
II. Reinforcement Learning Development Path (Toward PPO)
Value-Based Methods: Estimating Long-Term Reward
Early RL methods focused on estimating how good states or actions are.
The state-value function measures how good it is to be in a state.
The action-value function measures how good it is to take a specific action in a state.
These functions estimate expected future reward and form the foundation of many classic algorithms.
However, in NLP, the enormous action space makes pure value-based methods impractical. This pushes us toward policy-gradient approaches.
The Bellman Equation: Recursive Structure of Value
The Bellman equation formalizes a simple but powerful idea: the value of a state equals its immediate reward plus the expected value of future states.
This recursive structure allows long-horizon problems to be broken down into local updates. Even when not used explicitly, Bellman-style reasoning underlies most modern RL algorithms.
Understanding this recursion helps explain why critics and value heads are so important in PPO.
Advantage Functions: Relative, Not Absolute, Quality
In practice, it is rarely necessary to know how good an action is in absolute terms. What matters is whether it is better or worse than expected.
The advantage function captures this idea by measuring how much better an action is compared to the average action in the same state.
This relative signal dramatically reduces variance and stabilizes training. In PPO and RLHF, advantage estimation is the key bridge between raw rewards and stable policy updates.
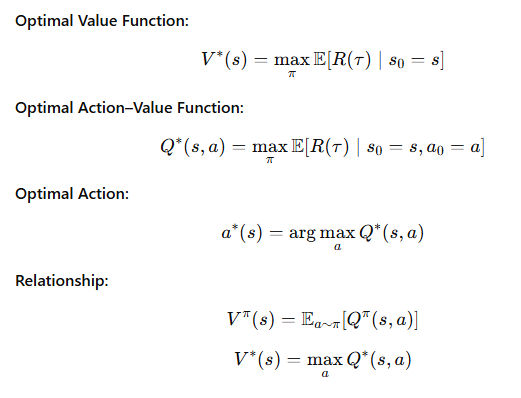
Why This Matters for NLP and LLMs
Reinforcement learning provides the mathematical language needed to describe:
- delayed human feedback,
- preference-based optimization,
- exploration in large action spaces,
- and alignment beyond imitation.
Understanding these fundamentals makes PPO feel less like a mysterious algorithm and more like a natural consequence of the constraints imposed by language modeling.
Once these concepts are clear, modern techniques—PPO, RLHF, DPO, rejection sampling—can all be seen as different ways of answering the same question:
How do we shape a language model’s behavior using imperfect, delayed, and subjective feedback?
That question sits at the heart of reinforcement learning in NLP.
Comments (0)