LLMs 40. Large Language Models (LLMs) — Training Section
Quick Overview
This technical guide examines how data is structured, selected, and scaled across LLM training pipelines, covering supervised fine-tuning (SFT) formats, reward model (RM) ranking data, PPO/RLHF workflows, dataset scaling and distribution-shift considerations, and contrasts between pre-training and fine-tuning datasets.
Large Language Models (LLMs) — Training Data, Formats, and Data-Centric Strategy
A Learning-Oriented Resource for SFT, RM, and PPO
This post focuses on how data is structured, selected, and scaled across the LLM training pipeline. Rather than listing datasets or recipes mechanically, the goal here is to help you understand why different stages require different data formats, how much data actually matters, and why modern LLM training has shifted from “more data” to “better data”.
If you understand this section well, you will also understand why many recent alignment methods reduce or even remove PPO entirely.
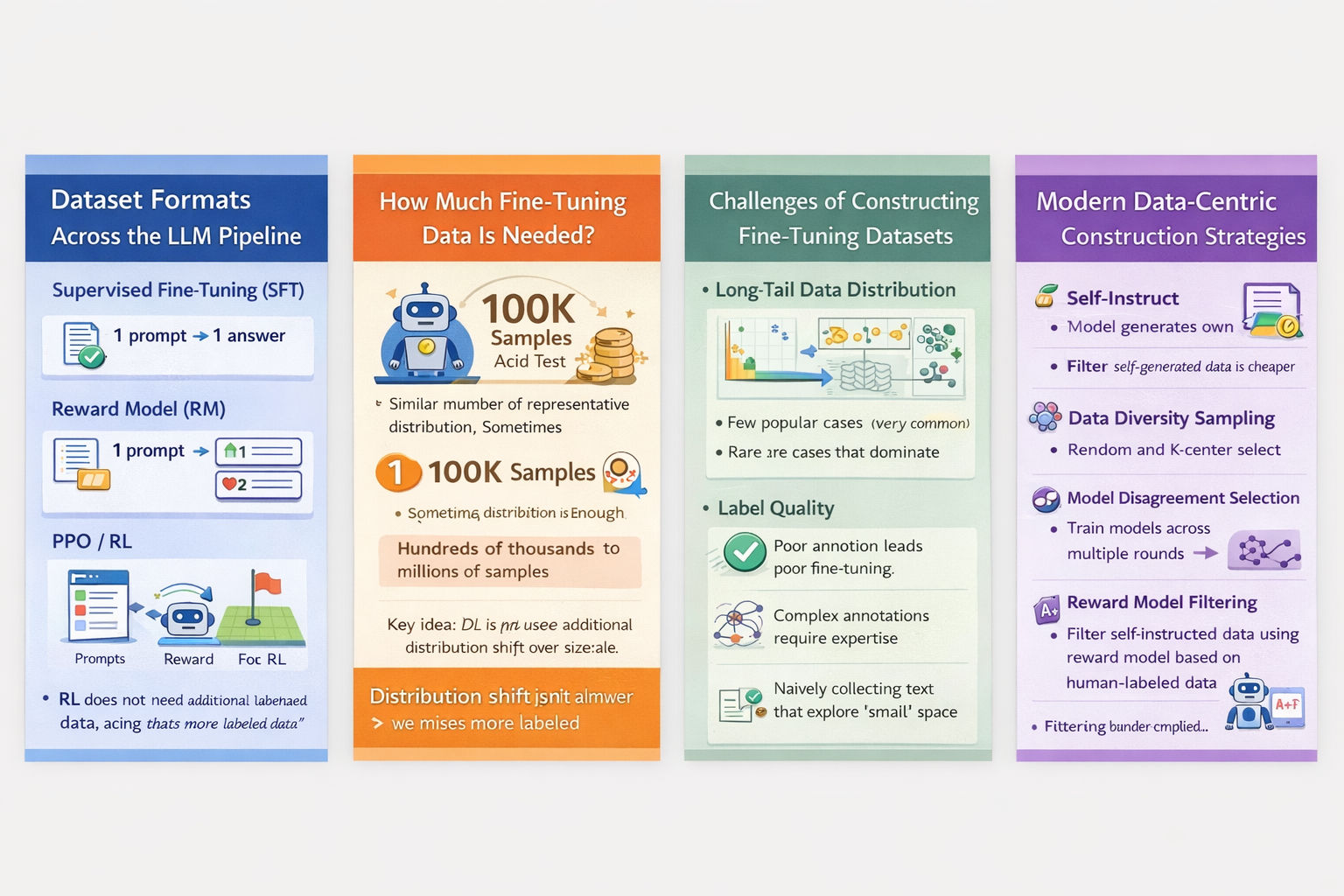
I. Dataset Formats Across the LLM Training Pipeline
1. Supervised Fine-Tuning (SFT)
The dataset format for SFT is intentionally simple:
one prompt → one answer
Each sample represents an instruction–response pair. The model is trained with standard next-token prediction, but the distribution of inputs is now instructional rather than raw text.
SFT data teaches the model:
- how to respond,
- what tone to use,
- what structure humans expect.
It does not teach preference trade-offs or safety boundaries in edge cases. That is why SFT alone is insufficient for alignment.
2. Reward Model (RM)
The reward model requires a fundamentally different structure:
one prompt + multiple candidate responses + a ranked preference
Instead of asking “what is the correct answer?”, the RM dataset asks:
Which answer is better, and by how much?
This shift is critical. RM training captures relative human preference, not absolute correctness. Ranking is slower than labeling, but it provides much richer supervision for alignment.
3. PPO / Reinforcement Learning Stage
In theory, PPO does not require new labeled data.
You only need:
- prompts (often reused from SFT),
- a reward model,
- and a regularization mechanism (typically KL divergence).
The model generates its own responses and learns from reward feedback. In practice, many pipelines still reuse SFT data to stabilize early training.
This highlights an important principle: RLHF is behavior optimization, not data expansion.
II. How Much Fine-Tuning Data Is Actually Needed?
The amount of data required depends less on model size and more on distribution shift.
If the downstream task distribution closely matches pre-training:
- ~100K samples is often sufficient.
If the distribution differs significantly (domain-specific tasks):
- hundreds of thousands to millions of samples may be required.
For smaller models, empirical practice shows:
- ~100K samples,
- 20+ epochs, are often enough to reach acceptable performance.
This explains why high-quality instruction datasets punch far above their weight.
III. Pre-Training vs Fine-Tuning Datasets
Large-Scale Pre-Training Data
Representative example: RedPajama-Data-1T
This dataset is massive, heterogeneous, and designed to teach general language competence. After preprocessing, it supports training base models like LLaMA.
Key characteristics:
- extremely large token count,
- broad coverage,
- lower per-sample value.
Storage requirements alone reach several terabytes.
Instruction and CoT Fine-Tuning Data
Instruction datasets are smaller but more valuable per token.
Examples include:
- Alpaca-CoT,
- OpenAI-style instruction datasets,
- chain-of-thought (CoT) corpora,
- multilingual and Chinese instruction datasets.
These datasets reshape how the model uses its knowledge, not what it knows.
IV. Domain-Specific Pre-Training: When and Why It Works
To build domain-specific LLMs, teams often introduce domain-focused pre-training data.
These datasets are:
- smaller,
- highly relevant,
- knowledge-dense.
Examples include:
- domain websites,
- specialized news,
- professional documents.
The benefit is faster adaptation with fewer tokens, because the data distribution aligns tightly with the target task.
V. The Real Challenge: Constructing High-Quality Fine-Tuning Data
Problem 1: Long-Tail Data Distribution
Real-world data is highly imbalanced.
A small number of popular categories dominate the dataset, while many rare categories appear infrequently. Naively collecting and annotating internet text leads to:
- massive annotation cost,
- uneven quality,
- high label noise.
This approach does not scale.
Problem 2: Label Quality
Low-quality annotations directly harm fine-tuning. For complex reasoning or technical tasks, shallow labeling produces misleading supervision and weak generalization.
This is why data construction strategy matters more than raw volume.
VI. Modern Approaches to Fine-Tuning Data Construction
Self-Instruct
The model generates its own:
- prompts,
- inputs,
- outputs.
These samples are then filtered and cleaned before training. This approach scales cheaply and leverages the model’s existing competence.
Active Learning: Data-Centric Optimization
Active learning reframes data selection around two principles:
- Maximize diversity
- Focus on uncertainty
Instead of collecting more data, we select better data.
Data Diversity Sampling
Diversity is measured using semantic similarity, typically via embeddings.
Common strategies include:
- random sampling,
- k-center greedy selection.
The goal is to cover the input space as broadly as possible with minimal redundancy.
Avoiding Redundancy with Existing Data
When high-quality labeled data already exists, new samples should add new information.
One effective approach:
- combine old and new data,
- train multiple models via cross-validation,
- select samples where models disagree most.
High disagreement signals unexplored or ambiguous regions of the data space.
Uncertainty-Based Sampling
Model uncertainty is another powerful signal.
For generative models:
- low token-level confidence,
- high perplexity, often indicate valuable training samples.
However, uncertainty alone is dangerous—low-quality data can harm training if not filtered.
Reward Model–Based Filtering
To address this, reward models are repurposed as quality filters.
A reward model, trained on human-labeled data, can:
- classify samples as high or low quality,
- filter self-generated data automatically,
- approximate human judgment at scale.
This replaces expensive manual filtering with a scalable, learned alternative.
VII. Key Takeaways
Modern LLM fine-tuning is no longer about collecting more data. It is about choosing the right data.
Across SFT, RM, and PPO, the guiding principles are:
- maximize diversity,
- focus on uncertainty,
- filter aggressively for quality.
Techniques such as self-instruct, active learning, model disagreement, uncertainty sampling, and reward-based filtering represent the current best practices in data-centric LLM training.
Once you understand this, many recent trends become clear:
- why PPO is being simplified,
- why small datasets can outperform large ones,
- and why alignment increasingly looks like a data problem, not an algorithm problem.
Comments (0)