LLMs 41. Large Language Models (LLMs) — Methods for Generating SFT Data
Quick Overview
This guide covers practical methods for building supervised fine-tuning (SFT) datasets for large language models, detailing human annotation, model-assisted generation techniques such as Self-Instruct and backtranslation, and pipeline considerations like generation, filtering, and trade-offs between quality, cost, and diversity.
Building High-Quality SFT Datasets for Large Language Models
A Learning-Oriented Guide to Human Annotation, Self-Instruct, and Backtranslation
This post focuses on how Supervised Fine-Tuning (SFT) datasets are actually constructed in practice, and why modern LLM training has shifted from purely human-labeled data to model-assisted data generation. Rather than treating these methods as tricks, we’ll frame them as data-scaling strategies that balance quality, cost, and diversity.
I. How Is an SFT Dataset Generated?
At a high level, there are two dominant ways to build SFT datasets:
Human annotation and LLM-generated data.
Human annotation remains the gold standard for high-stakes domains such as medicine, law, or safety-critical reasoning. Human-written answers tend to be more faithful, less biased toward model artifacts, and more aligned with real user intent. However, this approach is slow, expensive, and difficult to scale.
Using LLMs (such as GPT-4) to generate instruction–response pairs dramatically lowers cost and enables rapid dataset expansion. This method is particularly effective when the goal is to teach instruction-following behavior rather than domain-specific factual accuracy.
In practice, most modern SFT pipelines combine both approaches: humans provide seed examples and quality control, while models handle large-scale generation.
II. Self-Instruct: Letting the Model Teach Itself
What Is Self-Instruct?
Self-Instruct is a framework that uses a pretrained instruction-following model to bootstrap new instruction data from a small set of seed tasks. Instead of manually designing thousands of tasks, the model is prompted to invent new ones, along with corresponding inputs and outputs.
The core insight is simple but powerful:
if a model already understands instructions reasonably well, it can help generate more instructions that look realistic and useful.
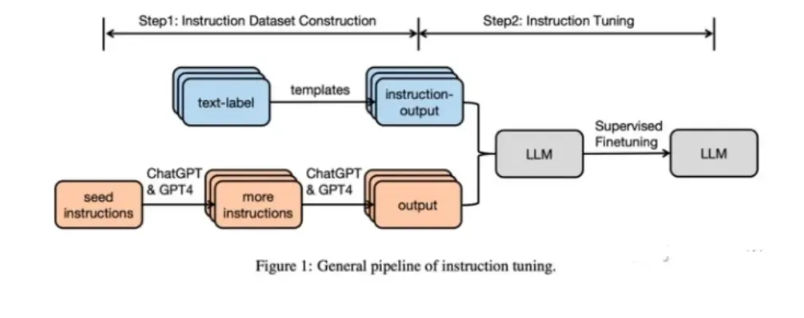
How the Self-Instruct Pipeline Works
Self-Instruct follows a multi-stage generation and filtering process designed to maximize diversity while controlling noise.
The process begins with a small set of human-curated task instructions covering a wide range of task types. These seed instructions act as anchors that define the style and scope of desired tasks.
From there, the model is prompted to generate new task instructions. Each generated instruction is then categorized based on its structure—most importantly, whether it represents a classification task or a free-form generation task.
For classification-style instructions, the model is asked to infer all possible labels implied by the instruction and then generate example inputs corresponding to each label. This ensures label coverage and reduces ambiguity.
For non-classification tasks, the pipeline introduces randomness in how data is generated. Sometimes the model generates an input first and then produces an output conditioned on both the instruction and the input. Other times, the output is generated first and an input is inferred afterward. This variation helps avoid overly rigid data patterns.
Once a large pool of instruction–input–output triples is generated, post-processing becomes critical. Redundant instructions are removed, near-duplicate samples are filtered out, and overly similar tasks are pruned. After cleaning, the original Self-Instruct work produced around 52K high-quality English instruction samples.
The key takeaway is that Self-Instruct is not just generation—it is generation plus aggressive filtering.
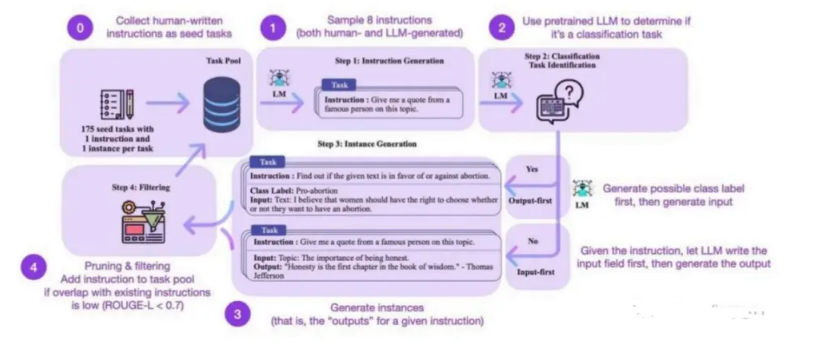
III. Backtranslation: Expanding Data Without Changing Meaning
What Is Backtranslation?
Backtranslation is a classic data augmentation technique that predates LLMs. The idea is to rewrite existing data into new surface forms while preserving meaning.
In traditional NLP, this often meant translating a sentence into another language and then translating it back. The resulting sentence differs lexically but remains semantically close to the original, providing useful variation for training.
Backtranslation with LLMs
Modern LLM-based backtranslation generalizes this idea beyond language translation. Instead of only translating between languages, models can:
- paraphrase instructions,
- rewrite prompts with different styles,
- generate alternative formulations of the same task.
In instruction tuning, this is especially valuable. A single instruction can be rewritten in many ways while retaining intent, helping the model generalize better to unseen phrasing at inference time.
LLM-based backtranslation pipelines typically:
- start from an existing instruction dataset,
- ask a model to rewrite instructions or inputs,
- optionally validate semantic consistency,
- filter low-quality or drifted samples.
This approach is particularly effective for multilingual settings and for adapting datasets to new domains or tones without collecting entirely new data.
IV. Why These Methods Matter Beyond SFT
Self-Instruct and backtranslation are not isolated techniques—they reflect a broader shift in LLM training philosophy.
Instead of asking “How do we label more data?”, modern pipelines ask:
How do we generate more useful supervision from what we already have?
These methods:
- reduce dependence on expensive human labeling,
- increase data diversity without sacrificing structure,
- and align naturally with later stages like reward modeling and RLHF.
In fact, many alignment techniques reuse the same ideas: generate candidates, score or filter them, and retrain on the best samples.
V. Practical Takeaways
SFT dataset construction is no longer a purely manual process. The most effective pipelines today are hybrid systems that combine human judgment with model-driven generation.
Self-Instruct excels at scaling instruction diversity from a small seed set. Backtranslation excels at expanding coverage without changing task intent. Together, they form the backbone of modern, cost-efficient SFT data pipelines.
Understanding these techniques helps explain why relatively small instruction datasets can produce highly capable chat models—and why data quality, not raw volume, increasingly determines success.
Comments (0)