LLMs 44. Distributed Training of Large Language Models (LLMs)
Quick Overview
An interview-prep guide to distributed training of large language models, covering data, tensor, and pipeline parallelism, sharding strategies, and communication and memory trade-offs.
Distributed training is what you reach for when a single accelerator can no longer hold, compute, and update a model on its own. This guide is for machine learning engineers preparing for system-design and ML-infra interviews: it explains distributed training of large language models (LLMs) as a systems problem rather than a list of framework flags, so you can reason about why each technique exists, when it works, and where the same logic shows up well beyond LLMs.
If you can articulate those three things in an interview, you stand apart from candidates who can only name frameworks. Pair this with hands-on practice on the Machine Learning Engineer question bank and the broader PracHub question set.
Why LLMs Force Distribution
Two hard limits collide in LLM training, and together they make a single device impossible.
Memory. Parameter count scales linearly with model size, but training memory grows much faster than the weights alone. For a given model you must also store:
- Optimizer states - for Adam, the running first and second moments, which add roughly two more values per parameter on top of the weight itself
- Gradients - one value per parameter
- Activations - intermediate outputs kept for the backward pass, which grow with batch size and sequence length
Add these up and the training-time footprint is several times the size of the raw weights. A high-memory GPU that can hold a model's parameters often still cannot train it without sharding state across devices. The exact multiplier depends on precision (FP16/BF16 vs FP32), optimizer choice, and how aggressively you recompute activations, but the direction is always the same: training memory dwarfs inference memory.
Time. Even with infinite memory, training a model with hundreds of billions of parameters on one accelerator would take an impractically long time. Splitting the work across many devices is not a nice-to-have optimization here; it is the only way the job finishes on a useful timescale.
These two constraints - capacity and throughput - define everything that follows.
Communication Is the Real Cost
Once training is distributed, raw computation is rarely the bottleneck. Communication is.
Every distributed strategy is really a different answer to one question:
What must be synchronized, when, and how often?
Two communication primitives behave very differently:
- Point-to-point sends (one device to one device) are cheap but narrow in scope.
- Collective operations - AllReduce, ReduceScatter, AllGather, Broadcast - coordinate every participating device and are far more expensive, scaling with both the number of workers and the volume of data moved.
The entire design space of distributed training comes down to minimizing how much data moves and how often it moves. That same insight carries straight over to distributed databases, streaming systems, and large-scale inference.
Here is a quick reference for the collectives you should be able to name and reason about in an interview.
| Operation | What it does | Common use in training |
|---|---|---|
| AllReduce | Every worker contributes a value; all workers end up with the combined (e.g. summed) result | Gradient synchronization in data parallelism |
| ReduceScatter | Combines values across workers, but each worker keeps only its shard of the result | First half of sharded gradient reduction (ZeRO/FSDP) |
| AllGather | Each worker shares its shard; all workers end up with the full assembled tensor | Reassembling sharded parameters before a forward/backward pass |
| Broadcast | One worker's value is copied to all others | Distributing initial weights or a shared scalar |
| Point-to-point send/recv | One device hands a tensor to exactly one other | Passing activations between pipeline stages |
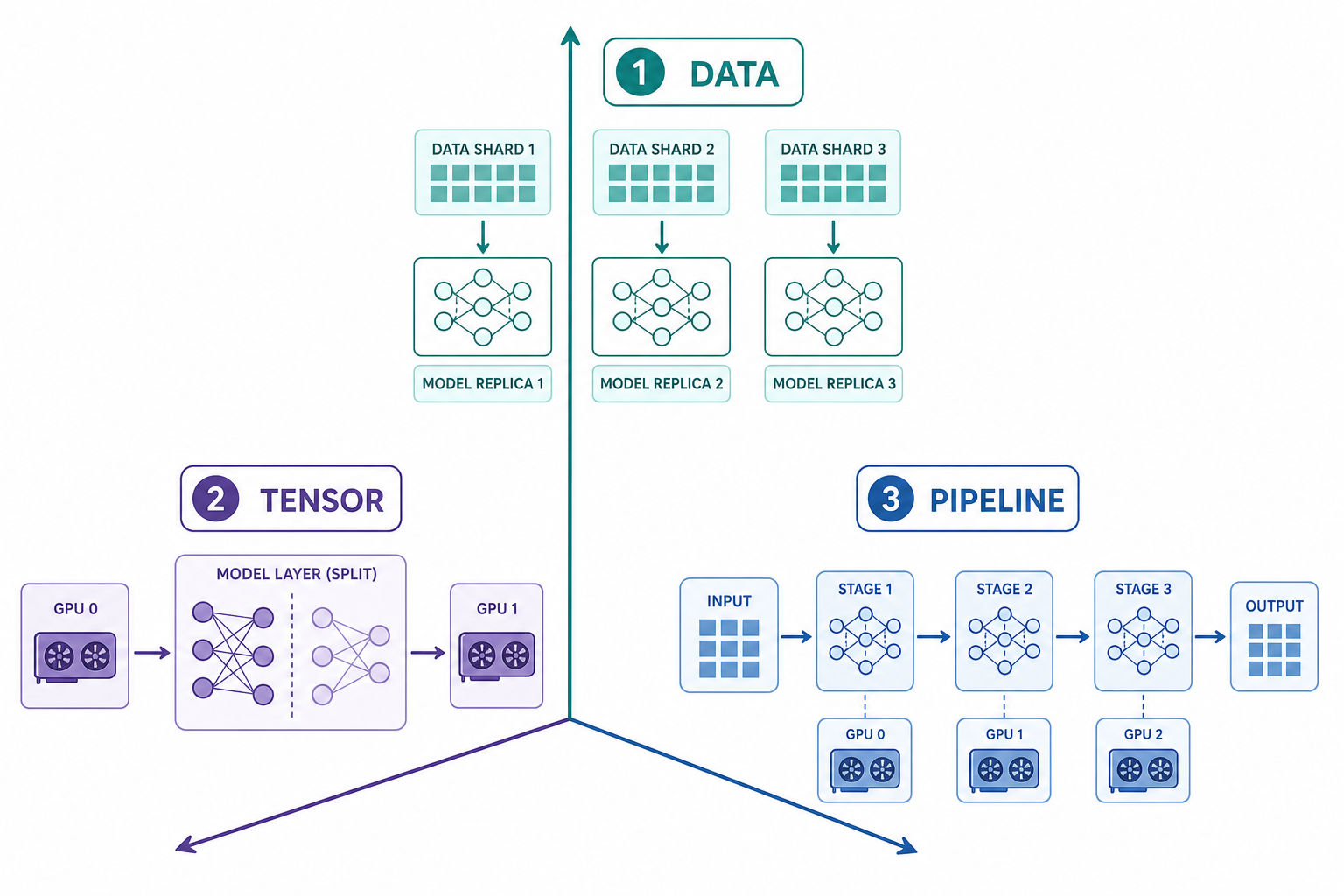
Data Parallelism: Scaling Compute, Not Memory
Data Parallelism (DP) is the simplest strategy: every worker holds a full copy of the model and processes a different slice of the batch. After each step, gradients are synchronized (typically via AllReduce) so all replicas apply the same update.
DP works well when:
- The model, its gradients, and its optimizer states fit on a single device
- Communication bandwidth is high enough to absorb the gradient sync
- Compute time dominates communication time
Its limitation is fundamental: memory does not scale. Each GPU still stores the full model, optimizer state, and gradients, so DP buys you throughput, not capacity. It mirrors a familiar pattern elsewhere - replicating a stateless web service raises throughput but does nothing for per-node storage.
Interview framing - example answer: "I'd start with data parallelism because it's the cheapest to reason about: replicate the model, shard the batch, AllReduce the gradients. The moment the model plus optimizer states stop fitting on one GPU, DP alone is dead and I have to start sharding state or the model itself." Notice how that answer leads with the constraint that breaks the approach, not just the mechanism.
Model Parallelism: Sharding the Model Itself
When the model no longer fits on one device, the model itself must be split. There are two distinct ways to cut it.
- Tensor Parallelism splits within a layer - a single large matrix multiply is partitioned across GPUs, and each device computes a slice of the same operation.
- Pipeline Parallelism splits across layers - different GPUs own different consecutive blocks of the network, and activations flow from one stage to the next.
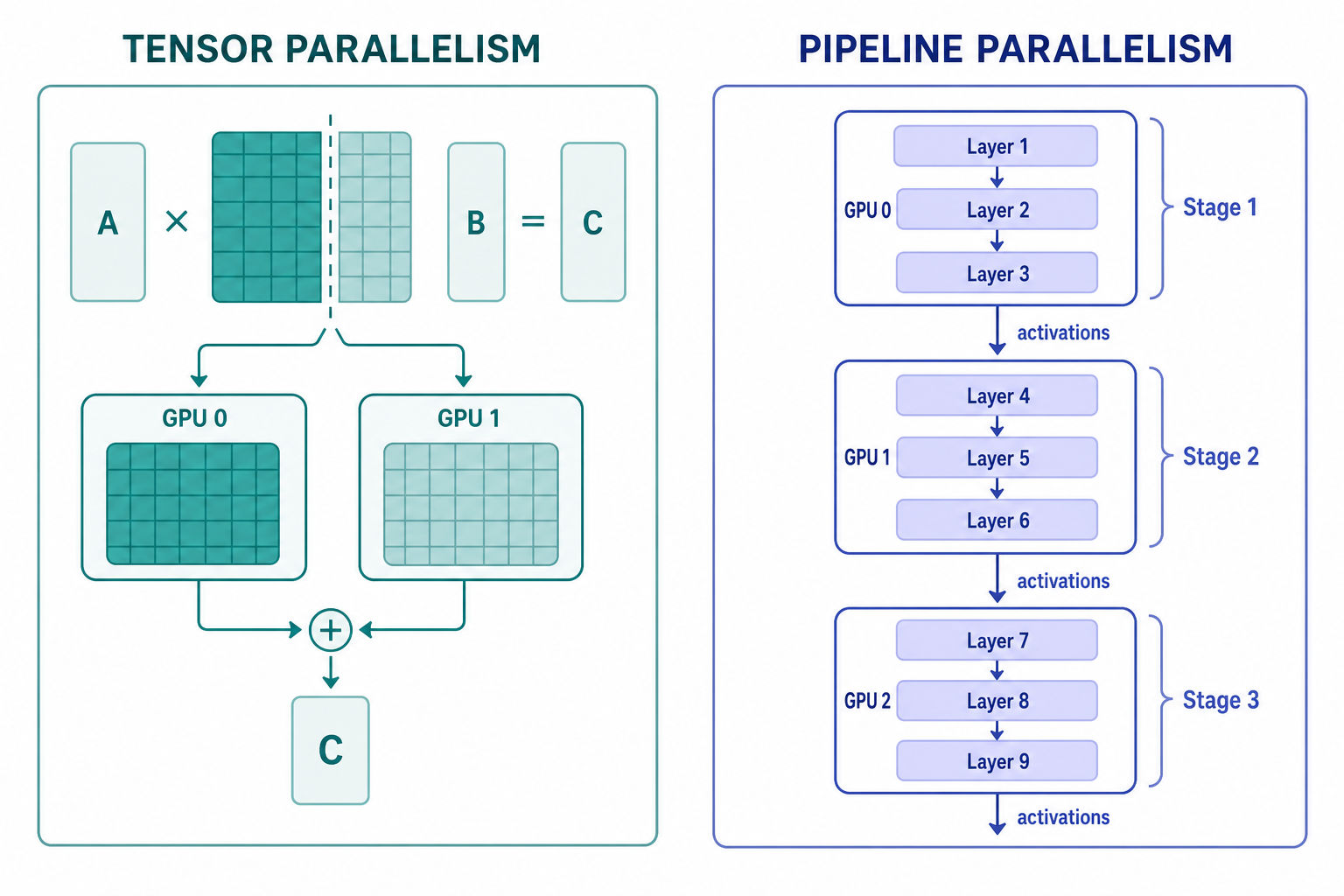
Both reduce memory per device, but each introduces its own communication cost:
- Tensor Parallelism adds frequent, fine-grained communication inside every layer, so it is highly sensitive to interconnect bandwidth.
- Pipeline Parallelism adds pipeline bubbles - idle time while stages wait for the first micro-batches to fill the pipeline - which hurts device utilization. Splitting the batch into more micro-batches shrinks the bubble but does not remove it entirely.
Neither is "better" in the abstract. The right choice depends on hardware topology, above all fast intra-node links (e.g. NVLink) versus the typically slower inter-node links (e.g. Ethernet, or InfiniBand across nodes). Tensor Parallelism wants the fastest interconnect available and is usually kept inside a node; Pipeline Parallelism tolerates slower links and is often used to span nodes.
The deeper lesson: architecture follows hardware, not the other way around.
Comparing the Strategies
The table below is the mental cheat sheet most candidates are missing. It maps each strategy to what problem it solves, what it costs, and when it breaks down.
| Strategy | Splits across devices | Solves | Main cost | Breaks down when |
|---|---|---|---|---|
| Data Parallelism (DP) | The batch | Throughput | Gradient AllReduce each step | Model + optimizer state won't fit on one device |
| Tensor Parallelism (TP) | Inside each layer | Fitting a layer too wide for one GPU | Fine-grained sync inside every layer | Interconnect is slow / spans nodes |
| Pipeline Parallelism (PP) | Across consecutive layers | Fitting a network too deep for one GPU | Pipeline bubbles (idle stages) | Too few micro-batches → low utilization |
| ZeRO / FSDP | Optimizer state, then gradients, then params | DP's memory waste | Extra gather/reduce communication | Coordination cost dominates at very large scale |
Why 3D Parallelism Exists
At the largest scales, no single axis is enough, so the major dimensions are combined:
- Data Parallelism - scale throughput across replicas
- Tensor Parallelism - fit a layer that is too wide for one device
- Pipeline Parallelism - fit a network that is too deep for one device
This combination - often called 3D parallelism - is not elegant, but it is effective. It reflects a reality worth internalizing:
Large systems are rarely simple; they are layered compromises.
A useful intuition: tensor parallelism is typically kept inside a node (fastest links), pipeline parallelism spans across nodes (tolerates slower links), and data parallelism replicates whole groups of those nodes to add throughput. Understanding why each dimension exists matters far more than memorizing how to configure them.
ZeRO and FSDP: Rethinking Redundancy
Plain Data Parallelism wastes memory: every replica stores an identical copy of the optimizer states, gradients, and parameters. ZeRO (Zero Redundancy Optimizer) and PyTorch's FSDP (Fully Sharded Data Parallel), which applies the same idea, ask why that redundancy should exist at all.
The redundancy is removed in stages, each one trading more memory savings for more communication:
- Stage 1 - shard optimizer states. Often the single biggest memory consumer with Adam, and the cheapest stage to add.
- Stage 2 - also shard gradients. Gradients are reduced into shards rather than replicated everywhere.
- Stage 3 - also shard parameters. Each worker permanently holds only its slice of the weights and gathers the rest on the fly for each forward/backward pass. This is the regime FSDP operates in.
By sharding state across the data-parallel workers and gathering each shard only when it's needed, these methods cut per-device memory dramatically while keeping DP's simple, data-parallel programming model. The cost is more communication: parameters and gradients now have to be gathered and reduced on the fly.
At small to moderate scales that trade-off is clearly favorable. At very large scales, the extra coordination can begin to dominate, which is why ZeRO-style sharding is often combined with tensor and pipeline parallelism rather than used alone. It captures a recurring systems theme: removing redundancy saves space but raises coordination cost.
Training vs Inference: Different Constraints, Different Answers
A strategy that is excellent for training can be poor for inference, because the two workloads optimize for different things.
Inference prioritizes:
- Low, predictable latency per request
- Minimal synchronization per request
- High throughput under serving constraints, not raw training speed
Pipeline parallelism and aggressive state sharding - both great for squeezing a giant model through training - often add latency and coordination that inference cannot afford. This is why production inference stacks frequently look simpler than the training setup for the very same model, and why inference has its own parallelism vocabulary (for example, splitting a layer across GPUs to cut per-token latency rather than to fit the model).
The takeaway: system design must be workload-aware. The model is the same; the right parallelism is not.
How This Transfers Beyond LLMs
The core ideas generalize well past LLM training:
- Recommendation systems - sharding massive embedding tables is the same memory-vs-communication problem as model sharding
- Graph processing - at scale, communication between partitions dominates computation, exactly as in distributed training
- Distributed storage - the replication-vs-sharding choice is the same trade-off as data parallelism vs model parallelism
Once you see distributed training as a resource-allocation problem, each new domain feels familiar. For more systems-flavored practice, browse infrastructure and ML questions from the major labs, such as the Google interview question bank.
A Mental Model for Candidates
When reasoning about any distributed system - in an interview or in production - work through four questions:
- What is replicated?
- What is sharded?
- What must stay consistent, and how often is it synchronized?
- What dominates cost here: compute, memory, or communication?
Example walk-through (data parallelism through this lens): replicated = the full model and optimizer state on every worker; sharded = the input batch; consistency = gradients synchronized once per step via AllReduce; dominant cost = communication bandwidth for that AllReduce as worker count grows. Run any strategy through the same four prompts and its trade-offs fall out almost mechanically.
Candidates who answer these clearly show genuine systems understanding - well beyond framework-level familiarity.
For a hands-on walkthrough that connects these concepts to real PyTorch code, this tutorial is a solid companion to the theory above.
How to Use This Page as a Prep Plan
Do not treat this as passive reading. Convert the ideas in this page into a short weekly loop: learn one idea, practice it under interview conditions, then write down what changed. That is the fastest way to turn advice into visible interview behavior.
| Prep area | What you need to prove | Practice artifact |
|---|---|---|
| Requirements | Clarify the problem before drawing boxes. | Functional and non-functional checklist. |
| Architecture | Map data flow before naming technologies. | One end-to-end diagram. |
| Tradeoffs | Explain why the design fits the constraints. | Latency, consistency, cost, and operability notes. |
| Failure handling | Show how the system behaves under stress. | Backpressure, retries, monitoring, and rollback plan. |
For LLMs 44. Distributed Training of Large Language Models (LLMs), the strongest candidates usually do three things well: they make their assumptions explicit, they use concrete examples instead of vague claims, and they review mistakes quickly enough that the next practice rep is better than the last one.
FAQ
What's the difference between data parallelism and model parallelism?
Data parallelism replicates the whole model on every device and splits the data, so it scales throughput but not memory. Model parallelism splits the model itself across devices (within a layer for tensor parallelism, across layers for pipeline parallelism), so it reduces per-device memory but adds communication. You reach for model parallelism only when the model plus its training state no longer fits on a single device.
When do I actually need tensor parallelism vs pipeline parallelism?
Tensor parallelism shines when individual layers are too wide for one GPU and you have a very fast interconnect (it communicates inside every layer, so it is bandwidth-hungry and usually kept inside a node). Pipeline parallelism shines when the network is too deep, tolerates slower cross-node links, but introduces idle "bubble" time you mitigate with more micro-batches. Many large runs use both at once.
How are ZeRO and FSDP related?
They implement the same core idea - eliminate the redundant copies of optimizer state, gradients, and parameters that plain data parallelism keeps on every worker. ZeRO is the optimizer-sharding technique popularized by DeepSpeed; FSDP is PyTorch's native implementation of fully sharded data parallelism. ZeRO is staged (shard optimizer states, then gradients, then parameters); FSDP's fully sharded mode corresponds to the most aggressive stage.
Why is communication, not computation, usually the bottleneck?
Modern accelerators are extremely fast at the matrix math, so once you split work across many devices the limiting factor becomes how much data must move between them and how often. Collective operations like AllReduce scale with both worker count and data volume, so as you add devices the synchronization cost can grow faster than the compute you saved. Designing distributed training is largely about minimizing data movement.
Does the training parallelism strategy carry over to serving the model?
Not directly. Training optimizes for total throughput and can absorb coordination overhead; inference optimizes for low, predictable per-request latency and minimal synchronization. A setup that is ideal for training (heavy pipeline parallelism, aggressive sharding) can add latency that serving cannot afford, which is why production inference stacks for the same model often look simpler.
How should I talk about this in an interview?
Lead with constraints, not framework names. State what is replicated, what is sharded, what must stay consistent and how often, and what dominates cost (compute, memory, or communication). Then explain which strategy that constraint forces and when it stops working. Interviewers consistently reward candidates who reason from first principles over those who recite config flags. Drill the pattern on real prompts from the PracHub question bank.
Final Thought
Distributed training is not about "using more GPUs." It is about aligning algorithms, hardware, and communication patterns under constraint.
If you can explain why a strategy works - and when it stops working - you are no longer just training models. You are designing systems.
Related Articles
Machine Learning Interview Questions: Complete 2026 Guide
This guide covers applied machine learning interview topics in 2026, including coding problems, ML theory such as bias–variance and evaluation......
Machine Learning Engineering Interview Guide (MLOps & AI 2026)
This guide covers MLOps and ML system design for 2026 interviews, including model deployment and production maintenance, CI/CD for models, data......
Shopify Machine Learning Engineer Interview Guide 2026
This guide details Shopify's 2026 Machine Learning Engineer interview process and study map, covering stages such as recruiter screens, the Life Story......
Snapchat Machine Learning Engineer Interview Guide 2026
This guide covers the Snapchat Machine Learning Engineer interview process in 2026, including recruiter and technical screens, virtual onsite loops......
Comments (0)