LLMs Document-Based Dialogue Using LLM + Vector Database (14)
Quick Overview
This practical learning guide covers document-based dialogue architectures that combine LLMs with vector databases, including retrieval-augmented generation, embedding construction and evaluation, similarity search, prompt template techniques to limit hallucination, and system-level optimization and performance trade-offs.
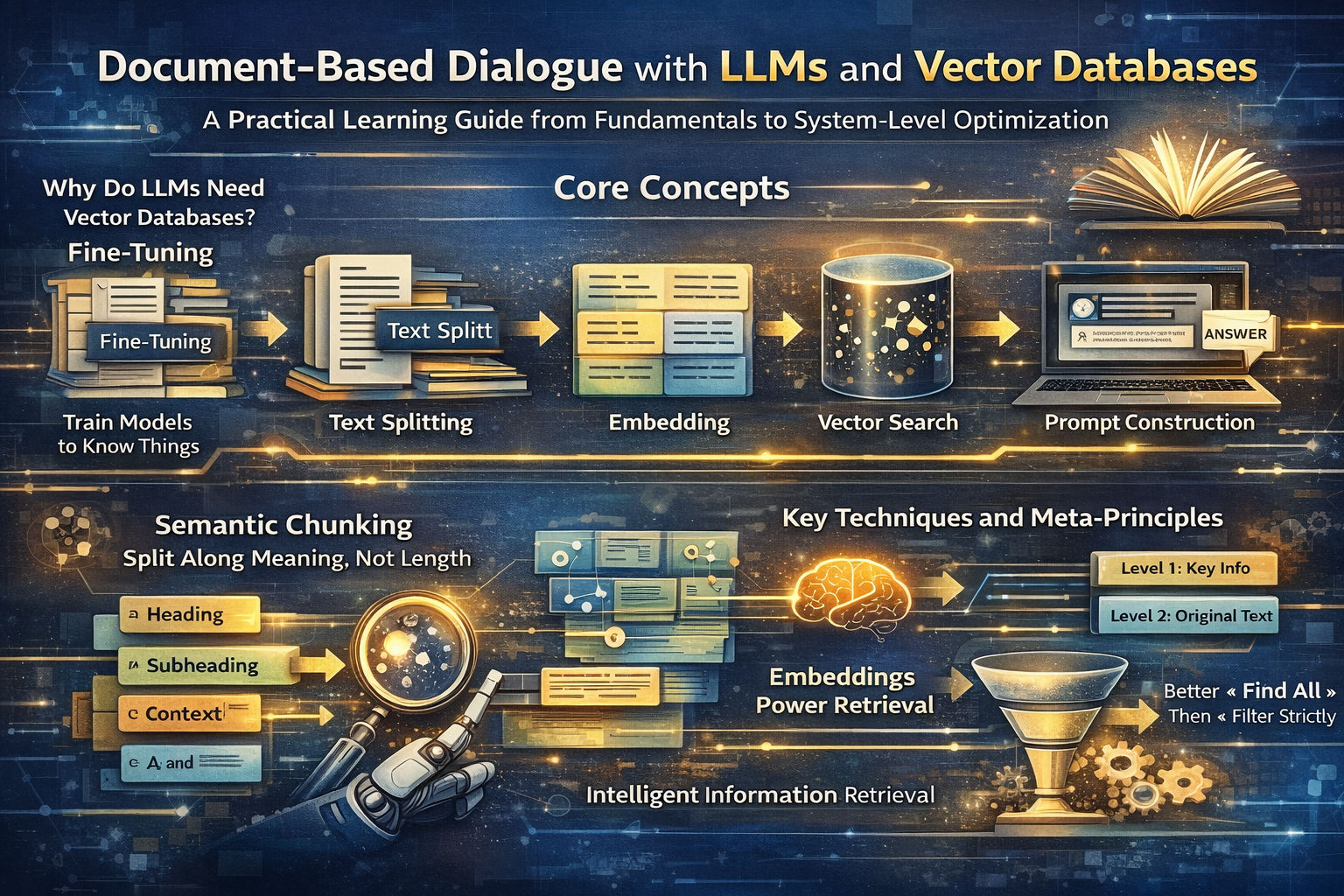
Document-Based Dialogue with LLMs and Vector Databases
A Practical Learning Guide from Fundamentals to System-Level Optimization
1. Why Large Language Models Need External Knowledge
Large Language Models (LLMs) are powerful pattern learners, but they are fundamentally closed-world systems. Their knowledge is frozen at training time, cannot be updated cheaply, and cannot reliably reflect private, real-time, or domain-specific data.
A seemingly direct solution is fine-tuning: inject external knowledge by training the model on tens of thousands of curated samples. In practice, this approach fails to scale. The data volume required to meaningfully “override” or extend a large model’s internal representation is enormous, training costs are prohibitive, iteration cycles are slow, and knowledge updates require retraining.
This is why modern systems increasingly favor retrieval over retraining.
Instead of forcing knowledge into model weights, we let the model read the knowledge at inference time.
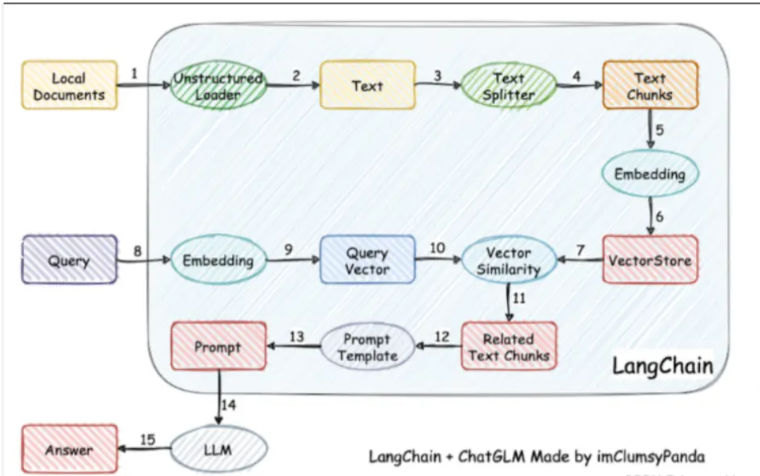
2. Core Idea: Retrieval First, Generation Second
Document-based dialogue using an LLM plus a vector database follows a simple but powerful principle:
The LLM does not store knowledge. It reasons over retrieved knowledge.
The workflow is conceptually linear:
- Documents are loaded and parsed
- Text is segmented into meaningful chunks
- Each chunk is embedded into a vector space
- User queries are embedded into the same space
- Similarity search retrieves the most relevant chunks
- Retrieved text is appended to the prompt as context
- The LLM generates an answer strictly based on that context
This architecture transforms an LLM into a context-aware reasoning engine, rather than a hallucination-prone oracle.
3. Embeddings: The Real Core Technology
While LLMs receive most of the attention, the true backbone of document-based QA systems is embeddings.
Embeddings convert text into dense vectors that capture semantic meaning. Once knowledge and queries live in the same vector space, retrieval becomes a geometric problem rather than a linguistic one.
This enables:
- Paraphrase robustness
- Cross-paragraph reasoning
- Flexible matching beyond keywords
At system level, this is no different from a recommendation engine: the quality of answers is largely determined by retrieval recall and precision, not by generation fluency.
4. Prompt Design: Controlling Hallucination by Construction
In document-based dialogue, prompt templates are not cosmetic. They are safety constraints.
A well-designed template explicitly:
- Binds the model to provided context
- Defines failure behavior (“insufficient information”)
- Forbids fabrication
This shifts responsibility:
- Retrieval decides what is known
- The LLM decides how to express it
If the answer is wrong, the first place to debug is retrieval, not the model.
5. The First Major Bottleneck: Chunking Granularity
Most failures in RAG systems do not come from the LLM. They come from poor document segmentation.
If chunks are too small:
- Context becomes fragmented
- Cross-sentence meaning is lost
If chunks are too large:
- Irrelevant noise dominates
- Similarity scores degrade
- Answers become vague or incomplete
The deeper insight is that chunking should be semantic, not mechanical. Line breaks, page breaks, or fixed token counts are proxies, not solutions.
6. Why Semantic-Level Chunking Matters
Real questions often require:
- Cross-paragraph aggregation
- Multi-granularity reasoning
- Counting or summarizing key points
If retrieval misses one critical segment, the LLM may confidently return an incomplete or wrong answer.
Increasing chunk size is a tempting shortcut, but it degrades precision. The correct direction is semantic indexing:
- Retrieve what the text is about, not just where it appears
7. Two-Level Indexing: A Practical Architecture Pattern
A robust design separates documents into two layers:
- Level 1: Key information
- Semantic summaries
- Headings
- Event-level descriptions
- Level 2: Original text
- Full paragraphs
- Source-aligned content
Retrieval happens on Level 1. Generation consumes Level 2.
This maximizes recall while keeping noise under control, and mirrors how humans skim before reading deeply.
8. Semantic Segmentation Strategies (Beyond Fixed-Length Chunks)
Several approaches can be applied depending on constraints:
Discourse-based parsing groups sentences that describe a single event or idea, ensuring each segment is conceptually complete.
BERT-based next-sentence prediction leverages semantic continuity. Adjacent segments are merged when their relationship exceeds a similarity threshold, producing adaptive chunk sizes without manual rules.
Sentence-level extraction combined with entity recognition or semantic role labeling focuses on “who did what to whom,” which is especially useful for factual or regulatory documents.
In vertical domains, generic NLP tools often underperform. Domain-specific LLMs can be used to generate key information directly, trading computational cost for accuracy.
9. Recall Beats Precision (At Retrieval Time)
A counterintuitive but critical principle:
Redundancy is acceptable. Missing information is not.
In vector retrieval:
- High recall ensures the LLM can answer
- Precision can be enforced later via prompting
This is why overlapping chunks and repeated key phrases often improve system reliability rather than degrade it.
10. Vertical Domains and Model Limitations
Generic embeddings and LLMs struggle in specialized fields:
- Law
- Medicine
- Finance
- Industrial specifications
Solutions include:
- Fine-tuning embedding models on domain data
- Using domain-aligned multilingual embeddings
- Combining vector search with keyword-based methods (BM25 + FAISS)
Hybrid retrieval systems are often more stable than “pure vector” designs.
11. Prompt Sensitivity and Generation Stability
Different prompt phrasings can yield radically different outputs, especially for instruction-following tasks. This is not a bug—it reflects how models were trained.
High-quality systems rely on:
- Prompt experimentation
- Output constraints
- Domain-specific instruction tuning
Generation quality issues are often misattributed to “weak models” when the real cause is low-quality context.
12. A Critical Insight: Most Hallucinations Are Retrieval Failures
In practice, hallucinations usually stem from:
- Missing key chunks
- Noisy context
- Poor chunk-to-query alignment
Improving preprocessing, segmentation, and embeddings often reduces hallucinations more than switching models.
13. What This Teaches Beyond RAG
This entire pipeline is not just about QA. It trains system-level thinking applicable to:
- Search engines
- Recommendation systems
- AI copilots
- Enterprise knowledge platforms
The core lesson is architectural:
Reasoning scales with context quality, not model size.
If you understand how retrieval, segmentation, embeddings, and prompting interact, you are no longer “using” LLMs—you are engineering AI systems.
Comments (0)