LLMs 19. Large-Model External Knowledge Base Optimization — How to Use Large Models to Assist Retrieval?
Quick Overview
This guide covers large-model-assisted retrieval techniques for optimizing external knowledge bases, explaining why LLMs should participate in retrieval, limitations of plain RAG, query formation and timing issues, and representative strategies such as HYDE (hypothetical document embeddings) and FLARE.
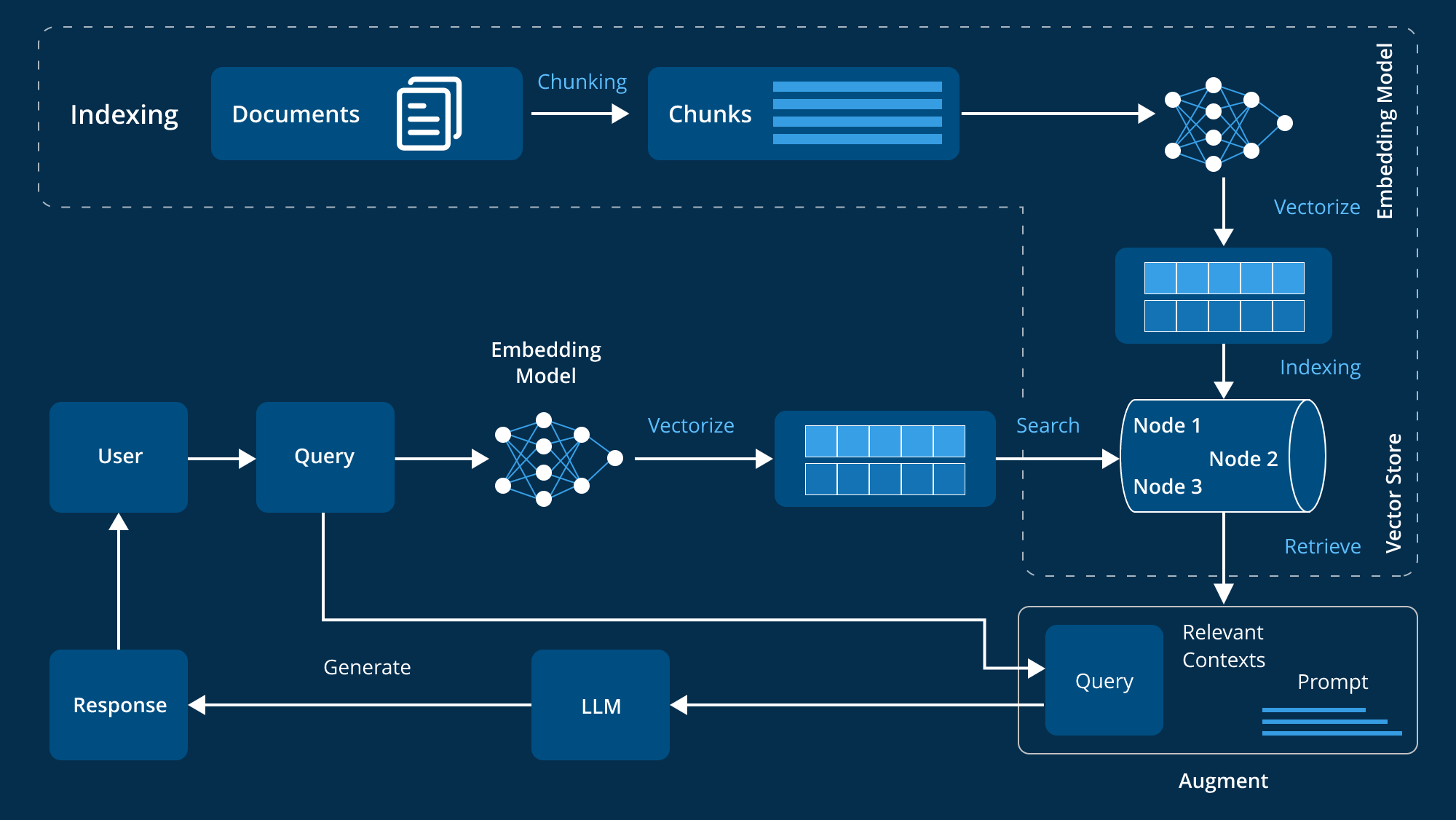
Large-Model External Knowledge Base Optimization
How Large Language Models Assist Retrieval (Beyond Plain RAG)
Retrieval-Augmented Generation (RAG) is often introduced as a simple two-step pipeline: retrieve relevant documents, then let a large language model generate an answer. In practice, this naïve setup breaks down quickly. The quality of retrieval is highly sensitive to how queries are formed and when retrieval is performed. This learning hub focuses on a deeper question: why large models themselves should participate in retrieval, and how two representative strategies—HYDE and FLARE—push retrieval beyond static similarity search.
::contentReference[oaicite:0]{index=0}
I. Why Do We Need Large Models to Assist Retrieval?
Traditional retrieval systems assume the user’s query is a clean, well-formed representation of their intent. Reality is very different. Real queries are colloquial, underspecified, and often mix intent with constraints in ambiguous ways. When such queries are embedded directly and used for retrieval, even strong vector databases struggle to surface the right evidence.
Large language models offer a way out because they do something retrieval systems cannot: they can reason about what the answer should look like. Instead of treating the query as a static string, we can use an LLM to expand, reinterpret, or actively refine it. In effect, retrieval becomes model-aware, rather than a blind preprocessing step.
This shift reframes retrieval as a semantic reasoning problem rather than a pure similarity problem.
Strategy 1: HYDE (Hypothetical Document Embeddings)
1. Core Idea Behind HYDE
HYDE is built on a simple but powerful intuition: even if a model does not know the correct answer, it can usually generate a plausible-looking answer. That plausibility alone is enough to guide retrieval.
The process works as follows. Given a user query, an LLM generates one or more hypothetical answers using sampling to encourage diversity. These answers do not need to be factually correct. They only need to resemble what a real answer might look like in structure and content. Each hypothetical answer, along with the original query, is embedded into vector space. The embeddings are then averaged to form a single retrieval vector, which is used to search the document corpus.
What makes this effective is that the fused embedding captures not just the surface form of the query, but the expected answer distribution. Retrieval is guided toward documents that “look like” answers, not just those that repeat query terms.
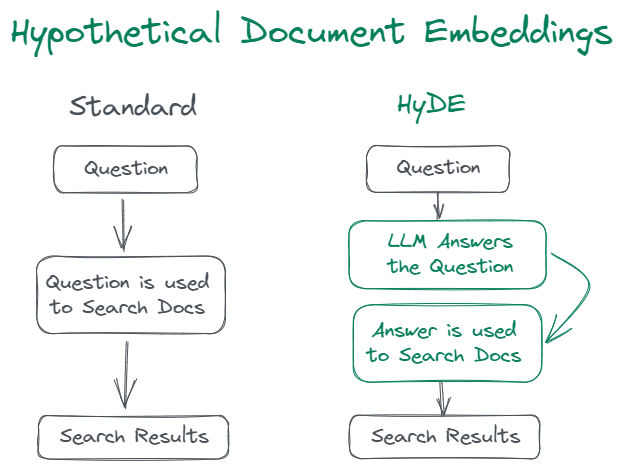
2. Limitations and Failure Modes of HYDE
HYDE is highly effective under the right conditions, but it is not free.
Its performance is tightly coupled to the strength of the assisting LLM. When the model generates high-quality hypothetical answers, retrieval quality improves significantly. However, weaker models may produce misleading or overly generic answers, which pollute the embedding space and degrade retrieval performance.
Empirical results show a sharp divide: when combined with fine-tuned embedding models and strong LLMs, HYDE delivers large gains. When paired with weaker models or non–fine-tuned embeddings, it can produce neutral or even negative effects. In short, HYDE amplifies both the strengths and weaknesses of the model you use to assist retrieval.
Strategy 2: FLARE (Active Retrieval Augmented Generation)
1. Why FLARE Is Necessary
HYDE still assumes a single retrieval step before generation. This assumption breaks down for long-form answers. As generation proceeds, the model may drift into subtopics that were not covered by the initial retrieval. When supporting evidence is missing, hallucination becomes likely.
FLARE addresses this by allowing retrieval to happen during generation. Instead of treating retrieval as a one-time operation, FLARE treats it as an ongoing interaction between the model and the knowledge base.
2. Retrieval Strategies in FLARE
Early approaches to iterative retrieval relied on fixed heuristics: retrieve after a fixed number of tokens, or after each sentence. These methods are simple but crude. They often retrieve too early or too late, wasting context budget or missing critical information.
FLARE’s key contribution is allowing the model itself to decide when retrieval is needed.
2.1 Strategy 1: Model-Initiated Retrieval Triggers
In the first FLARE strategy, the model is trained—via prompting and examples—to explicitly request retrieval when it encounters uncertainty. This resembles the Toolformer paradigm.
During generation, the model emits a special marker such as [Search(query)]. This marker triggers a retrieval call using the generated query. The retrieved content is inserted into the context, the marker is removed, and generation resumes. To prevent compounding errors, any text generated after the previous retrieval is discarded before continuing.
This approach gives the model fine-grained control over retrieval timing. However, it is brittle. Models do not naturally produce retrieval triggers, so token probabilities often need to be artificially biased. Excessive retrieval can harm fluency, and prompt design becomes complex and fragile.
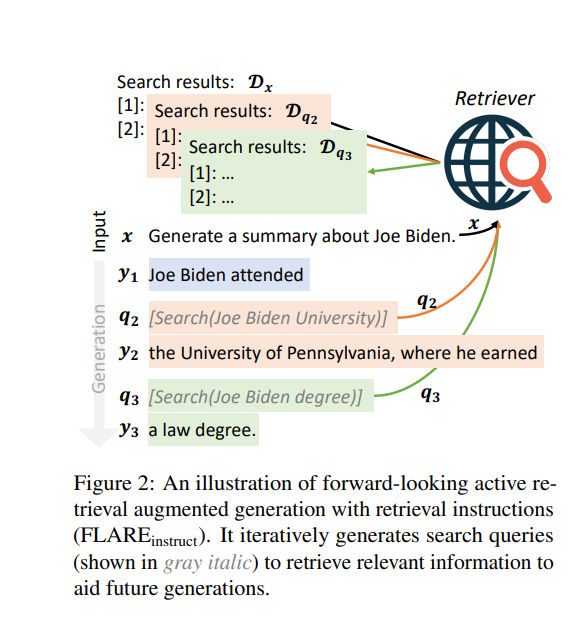
2.2 Strategy 2: Confidence-Aware Retrieval (Probability-Based)
To avoid brittle prompt engineering, FLARE proposes a second strategy grounded in model uncertainty. The underlying assumption is that token probability reflects confidence. When the model is unsure, probabilities drop.
The system first performs an initial retrieval and begins generation. As each sentence is completed, the model’s token probabilities are inspected. If any token falls below a confidence threshold, retrieval is triggered automatically. The generated sentence is treated as a “hypothetical answer” and used as the retrieval query, or alternatively, the model reformulates it into a question for retrieval.
Once new evidence is retrieved, the sentence is regenerated with corrected information, and generation continues. This approach is more adaptive and requires less prompt engineering, but it depends on access to token-level probabilities—something many closed models do not expose.
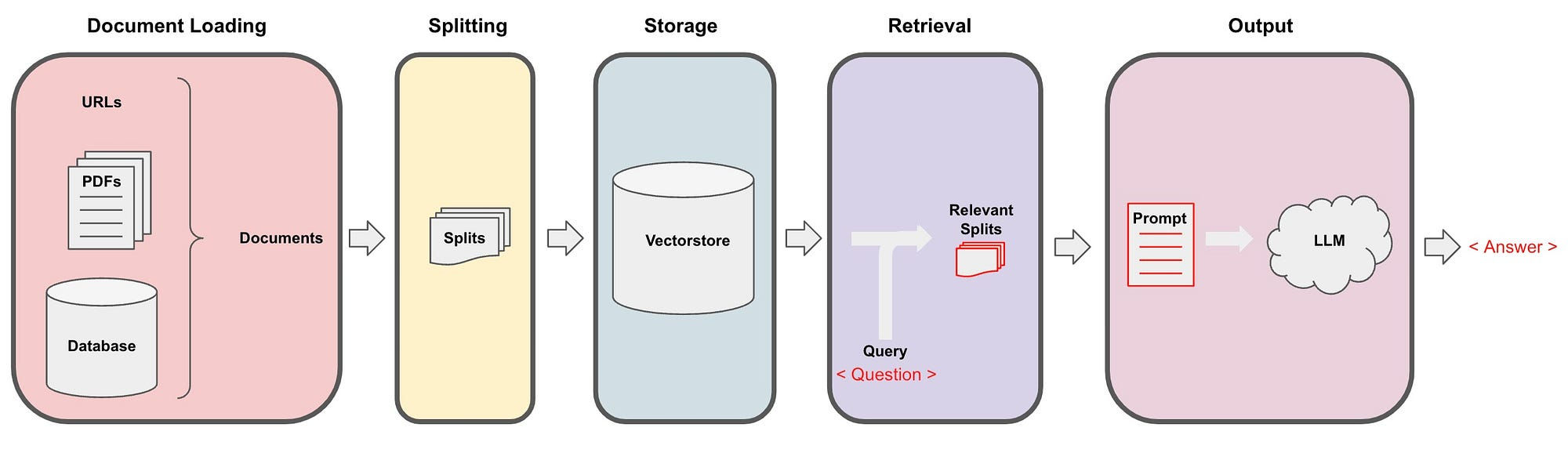
Closing Perspective
HYDE and FLARE represent two different philosophies of LLM-assisted retrieval. HYDE improves query representation before retrieval begins. FLARE improves retrieval timing during generation. Both challenge the idea that retrieval should be static and model-agnostic.
As external knowledge bases grow and applications demand higher factual reliability, retrieval will increasingly become an interactive process. Large models are not just consumers of retrieved text—they are active participants in deciding what to retrieve and when. Understanding this shift is essential for building robust, production-grade RAG systems.
Acknowledgements
This learning hub synthesizes ideas from recent research on dense retrieval, active RAG, and uncertainty-aware generation. It is intended to help readers reason about retrieval as a system-level design problem rather than a single algorithmic choice.
Comments (0)