LLMs Large-Model RAG Explained (15)
Quick Overview
This systems-level guide explains Retrieval-Augmented Generation (RAG), covering LLM capability gaps such as timeliness, coverage, and verification, plus retrieval mechanics including embeddings, similarity metrics, chunking, and pipeline design for updatable and verifiable generation.
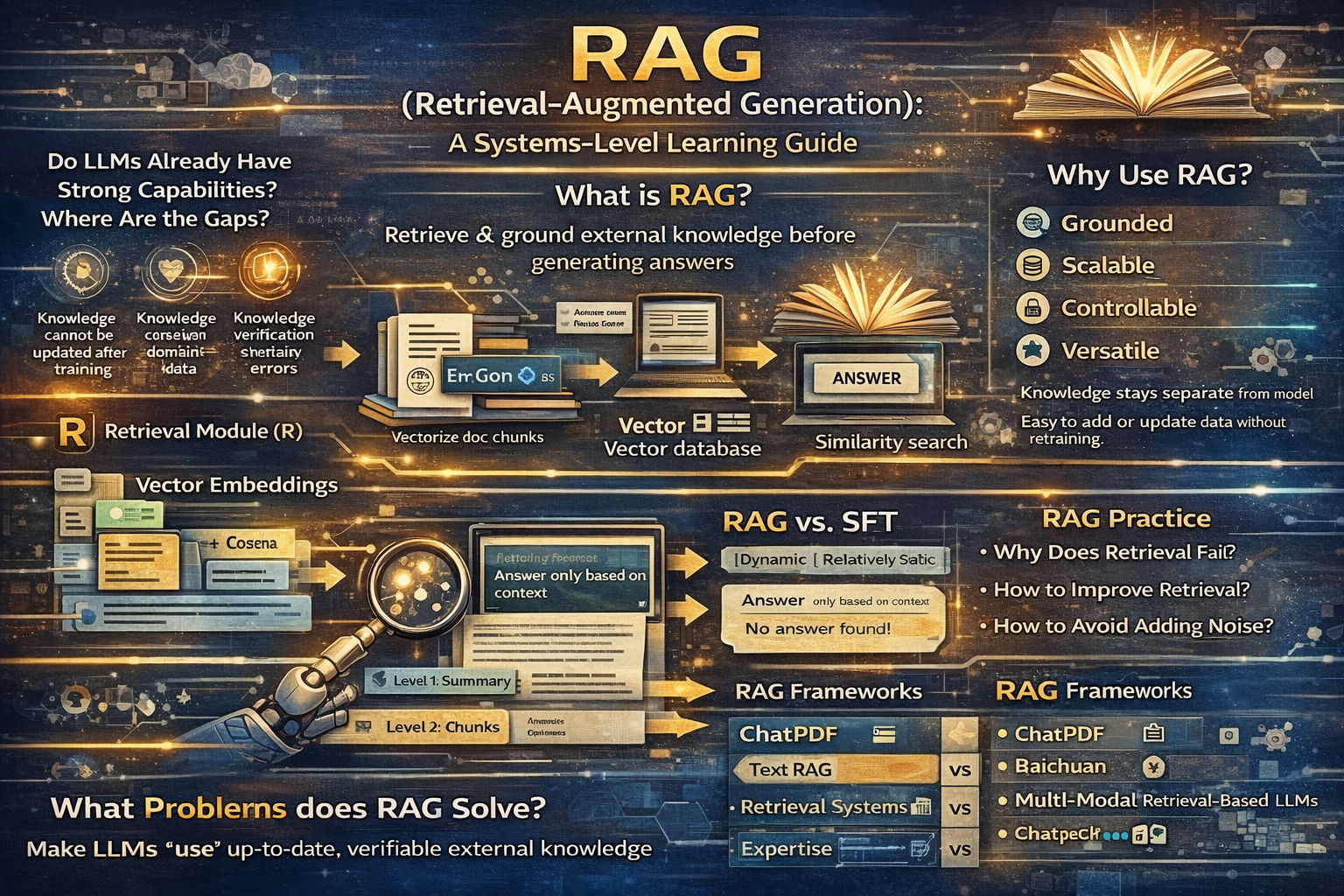
RAG (Retrieval-Augmented Generation): A Systems-Level Learning Guide
This resource is designed to help you understand what RAG really is, why it exists, and how to design it correctly from an engineering perspective. The goal is not to memorize components, but to build a mental model that transfers across tools, frameworks, and domains.
I. Do LLMs Already Have Strong Capabilities? Where Are the Gaps?
Large Language Models are already impressive general-purpose reasoners. They can summarize, translate, explain concepts, and generate fluent text. However, these strengths hide several structural weaknesses that matter in real systems.
The first gap is knowledge timeliness. An LLM’s knowledge is encoded in parameters learned during training. Once deployed, it cannot naturally “learn” new facts. Any information that changes frequently—policies, prices, product specs, regulations—quickly becomes outdated.
The second gap is knowledge coverage. Even very large models perform poorly on niche, domain-specific, or long-tail knowledge. Accuracy drops sharply in areas like internal company documents, legal clauses, medical guidelines, or proprietary technical specs.
The third and most dangerous gap is knowledge verification. LLMs are probabilistic generators. They can produce answers that sound confident but are factually wrong. In enterprise or regulated settings, this lack of traceability and correctness is unacceptable.
RAG exists specifically to close these gaps.
II. What Is RAG?
Retrieval-Augmented Generation is a system design pattern, not a model.
Instead of asking the LLM to answer questions purely from its internal memory, RAG forces it to retrieve relevant external knowledge first, then generate answers grounded in that knowledge.
The LLM does not become “smarter” in isolation. It becomes context-aware, updatable, and verifiable.
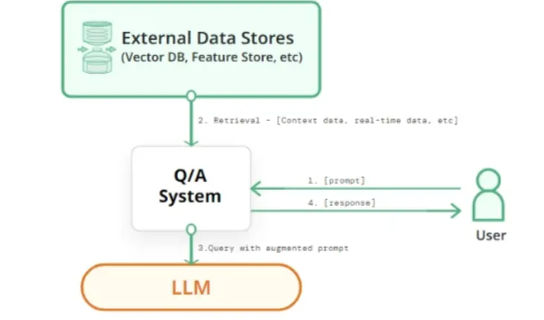
III. R: The Retrieval Module
Retrieval is the foundation of RAG. If retrieval fails, generation quality becomes irrelevant.
1. How Are Documents Represented?
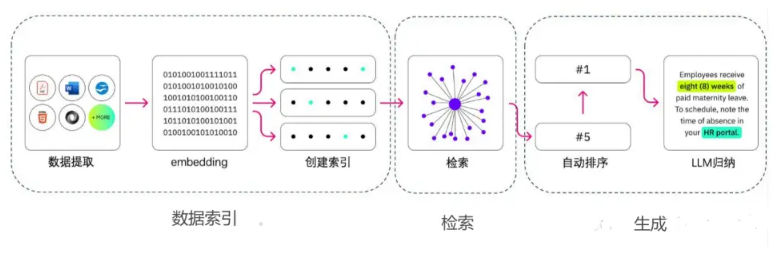
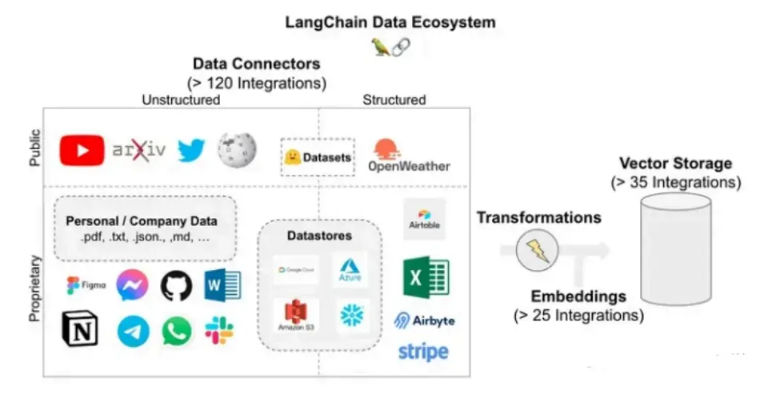
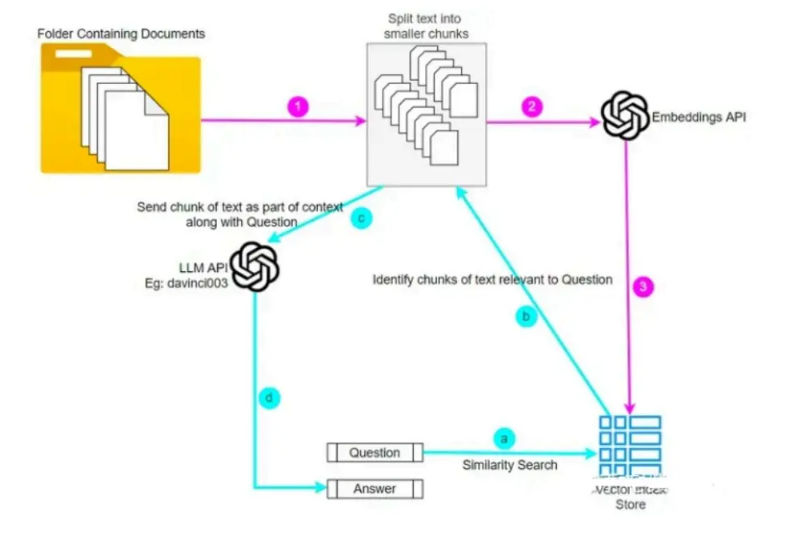
Documents cannot be searched efficiently in raw text form at scale. They must be transformed into vector embeddings—numerical representations that encode semantic meaning.
Both documents and user queries are embedded into the same vector space. Similarity metrics (such as cosine similarity) are then used to find the most relevant text chunks.
The embedding model you choose directly defines what “relevant” means. Poor embeddings lead to poor retrieval, regardless of how strong the LLM is.
2. How to Build an Efficient Retrieval Pipeline
An effective retrieval pipeline is usually multi-stage:
Documents are first chunked into semantically coherent pieces. These chunks are embedded and stored in a vector database. When a query arrives, the system retrieves the top-K most similar chunks, optionally re-ranks them, and passes them downstream.
Efficiency is not just about speed. It is about balancing recall (not missing important information) and precision (not flooding the LLM with noise).
3. How to Retrieve Large Documents
Large documents introduce two problems: context length limits and semantic dilution.
A common solution is hierarchical retrieval. Instead of embedding everything at the same granularity, the system first retrieves coarse sections (titles, summaries, headings), then drills down into finer-grained chunks only where necessary.
This mirrors how humans read: skim first, then read deeply.
IV. G: The Generation Module
Generation is the final step, but it should be treated as a controlled reasoning process, not free-form text creation.
The LLM receives:
- The user’s question
- Retrieved context from external documents
Its task is to synthesize an answer strictly from that context.
1. Improving Generation Quality
Generation quality depends less on the model than on the constraints you impose.
Clear prompts that specify tone, scope, and answer format dramatically improve consistency. Explicit instructions such as “answer only from the provided context” shift the model from creativity to compliance.
2. Controlling Hallucinations
Hallucinations are not a model bug; they are a system design failure.
They can be reduced by:
- Forcing answers to be grounded in retrieved text
- Requiring citations or references
- Allowing explicit “no answer found” responses when context is insufficient
If the model is hallucinating, the first thing to debug is retrieval quality—not the LLM.
V. Why Use RAG?
RAG replaces model retraining with knowledge injection at inference time.
This brings several system-level advantages:
RAG scales better because knowledge can be updated without retraining models. It improves accuracy because answers are grounded in explicit sources. It increases trust because retrieved documents explain why an answer was generated. It also improves security and access control, since data lives outside the model and can be permissioned.
Most importantly, RAG turns LLMs from opaque generators into auditable reasoning systems.
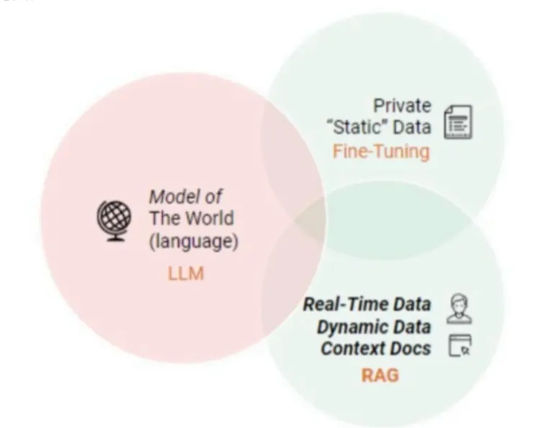
VI. RAG vs. SFT (Supervised Fine-Tuning)
RAG and SFT solve different problems.
Fine-tuning is powerful for shaping behavior: tone, style, domain language, structured outputs. But it struggles with frequently changing knowledge and lacks transparency.
RAG excels at knowledge grounding and traceability but does not inherently change model behavior.
In practice, strong systems combine both:
- Use SFT to teach how to answer
- Use RAG to supply what to answer with
VII. Why Retrieval Fails in Practice
Retrieval failures are common and usually stem from:
- Poor chunking strategies
- Low-quality embeddings
- Query–document semantic mismatch
- Overly aggressive filtering that sacrifices recall
Increasing chunk size rarely fixes the issue. It often introduces noise and reduces answer precision.
VIII. How to Improve Retrieval Accuracy Without Adding Noise
High-performing systems prioritize recall first, then filter.
This often means:
- Allowing some redundancy
- Retrieving more candidates than strictly necessary
- Applying re-ranking or semantic compression later
In RAG, missing information is more harmful than extra information.
IX. RAG Frameworks and Real Systems
Tools like ChatPDF demonstrate classic RAG patterns: document parsing, chunking, embedding, retrieval, and grounded generation.
Search-augmented systems like Baichuan extend this with intent understanding and result augmentation to further reduce hallucinations.
Multimodal RAG systems (such as RA-CM3) generalize the same idea across text, images, and other modalities, proving that RAG is a universal architectural pattern, not a text-only trick.
X. What Problems Does RAG Still Have?
RAG is not a silver bullet.
Retrieval quality depends heavily on embeddings and data quality. Conflicting retrieved sources can confuse the model. Long-context generation can become inefficient and expensive. Clear source attribution remains challenging in complex retrieval pipelines.
These are system-level problems, not model-level ones—and they require engineering, not prompting, to solve.
Final Takeaway
RAG reframes how we build AI systems.
Instead of asking, “How smart is the model?”
You start asking, “How good is the retrieval?”
Once you understand this shift, you stop using LLMs and start engineering reliable AI systems.
Comments (0)