LLMs Large Models (LLMs) RAG Edition Analysis — Table Recognition Methods (17)
Quick Overview
This practical learning guide analyzes table recognition methods for document understanding in LLM-based RAG systems, covering table detection, table structure recognition, handling of scanned and noisy PDFs, and the impact of extraction quality on retrieval and embeddings.
Large Language Models (LLMs) × RAG
A Practical Learning Guide to Table Recognition in Document Understanding
Tables are one of the most information-dense structures in documents—and also one of the hardest for machines to understand. In retrieval-augmented generation (RAG) systems, poor table understanding directly leads to incorrect retrieval, hallucinated answers, or silent data loss. This post is written as a learning-oriented resource: it explains why table recognition matters, what problems it actually solves, and how different technical approaches fit into real LLM pipelines.
I. Why Table Recognition Is Necessary
Tables are deceptively complex. Two tables can convey identical information while looking completely different at the pixel and layout level. Borders may be explicit, implicit, or missing entirely. Cells can span rows and columns. Text alignment, background shading, and font usage vary wildly across documents.
The challenge is amplified in real-world corpora. Modern PDFs generated from spreadsheets behave very differently from scanned financial statements, academic papers, invoices, or historical documents. Lighting, skew, scan quality, and handwriting introduce noise that breaks naïve extraction strategies.
In RAG systems, tables often contain critical facts: financial metrics, experiment results, configuration matrices, or legal clauses. If these structures are flattened incorrectly or partially extracted, downstream embeddings and LLM reasoning operate on corrupted data. Table recognition is therefore not an optional preprocessing step—it is a core reliability requirement.
::contentReference[oaicite:0]{index=0}
II. What Are Table Recognition Tasks?
Table recognition is best understood as two tightly coupled problems rather than a single algorithm.
The first is table detection. This answers a simple but fundamental question: where is the table? The system must locate table regions within a page that may also contain paragraphs, figures, headers, and footnotes. Modern approaches treat this as an object detection or instance segmentation problem.
The second is table structure recognition, which is significantly harder. Once a table region is known, the system must reconstruct its logical structure: rows, columns, merged cells, and reading order. This step determines whether the output is a faithful representation or just a visually cropped image with text.
At a finer level, structure recognition involves identifying individual cells, understanding how they relate spatially, and mapping text content into the correct cell coordinates. For LLM usage, this is the step that decides whether a table becomes a usable JSON, a Markdown grid, or a meaningless text blob.
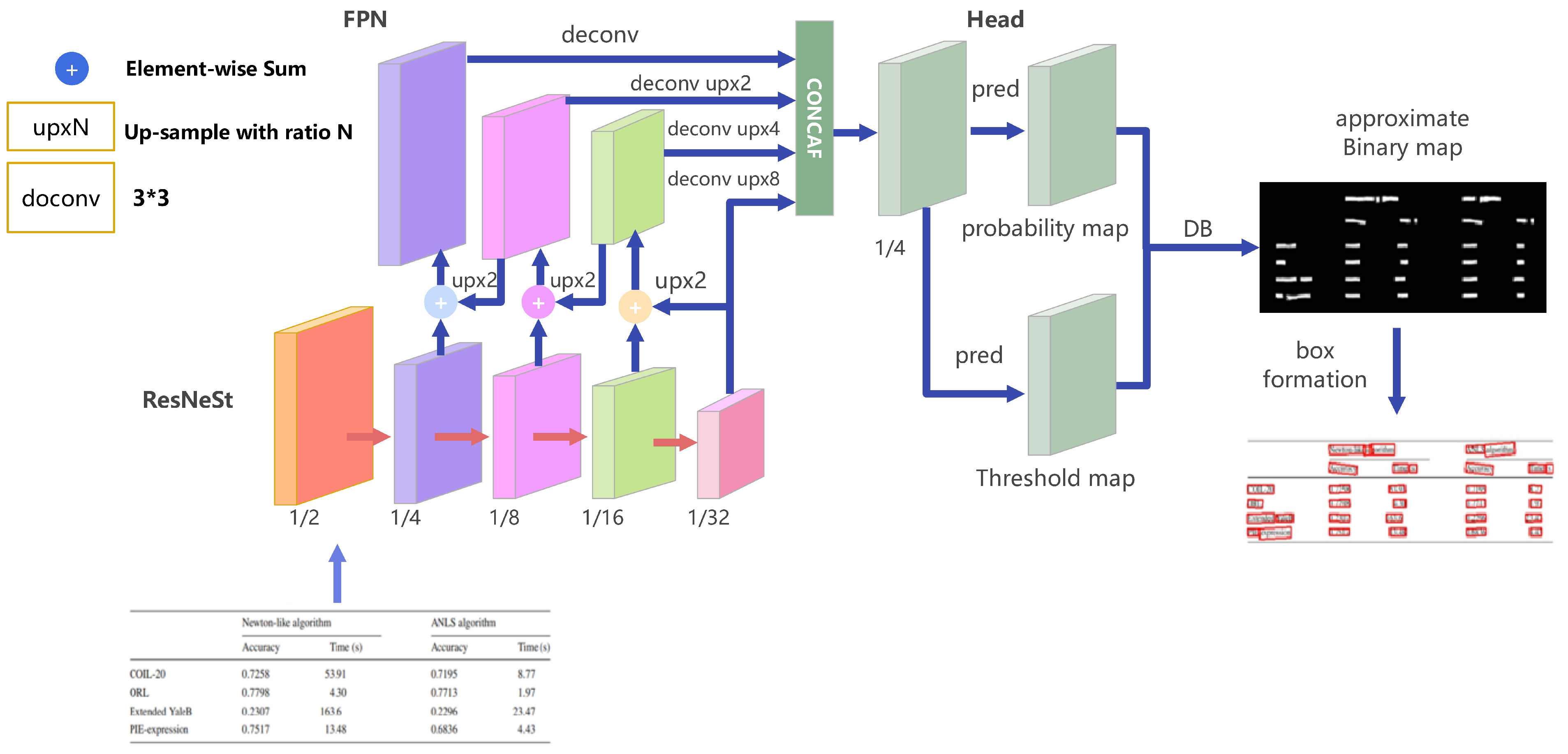
III. What Table Recognition Methods Exist?
1. Traditional Rule-Based and Image Processing Methods
Early table recognition systems relied on deterministic pipelines. Images were enhanced to highlight edges, straight lines were detected using classical vision techniques, and intersections of horizontal and vertical lines were used to infer grid structures. Candidate regions were filtered by geometric constraints such as aspect ratio and minimum size.
These methods are interpretable and fast, but fragile. They break down when tables lack explicit borders, contain merged cells, or are embedded in noisy scans. Today, they are mainly useful as baselines or as components in hybrid systems.
2. Table Extraction with pdfplumber
When dealing with born-digital PDFs, pdfplumber remains one of the most practical tools. Its strength lies in leveraging PDF internal representations rather than pixels alone.
The core idea is simple: tables are implicitly defined by the alignment of text and invisible layout lines. pdfplumber first extracts all candidate horizontal and vertical edges—both visible and invisible. It then computes their intersections to form the smallest possible cell units. Adjacent cells are merged based on continuity rules to form full tables.
Two extraction strategies dominate its usage:
- Lattice-based extraction, which works best when tables have clear grid lines. The page is rasterized, lines are detected, intersections define cells, and text is filled accordingly.
- Stream-based extraction, which is designed for borderless tables. Here, aligned text streams are clustered into rows and columns based on spacing and character coordinates.
For RAG systems ingesting reports, manuals, or system-generated PDFs, this approach is often the highest return on investment before introducing deep learning.
3. Deep Learning Methods: Semantic Segmentation and Beyond
As document complexity increases, deep learning becomes unavoidable. Modern systems treat table understanding as a pixel-level prediction problem, often using semantic or instance segmentation.
Some approaches focus on table frame detection, separating tables from surrounding content. Others go further and predict row lines, column lines, and even cell boundaries directly.
Representative ideas across models include:
- Using encoder–decoder architectures to label pixels as table regions, lines, or separators.
- Predicting multiple overlapping classes to handle intersections and invisible boundaries.
- Combining object detection for table regions with segmentation for internal structure.
End-to-end models such as those based on cascaded detection networks attempt to jointly solve table localization and structure recognition. Two-stage methods instead decompose the problem: first split a table into a grid, then merge cells based on learned relationships.
A recurring theme across these models is data efficiency. Many rely on transfer learning from large vision datasets and fine-tune on relatively small table-specific corpora. This makes them attractive for enterprise settings where labeled documents are scarce.
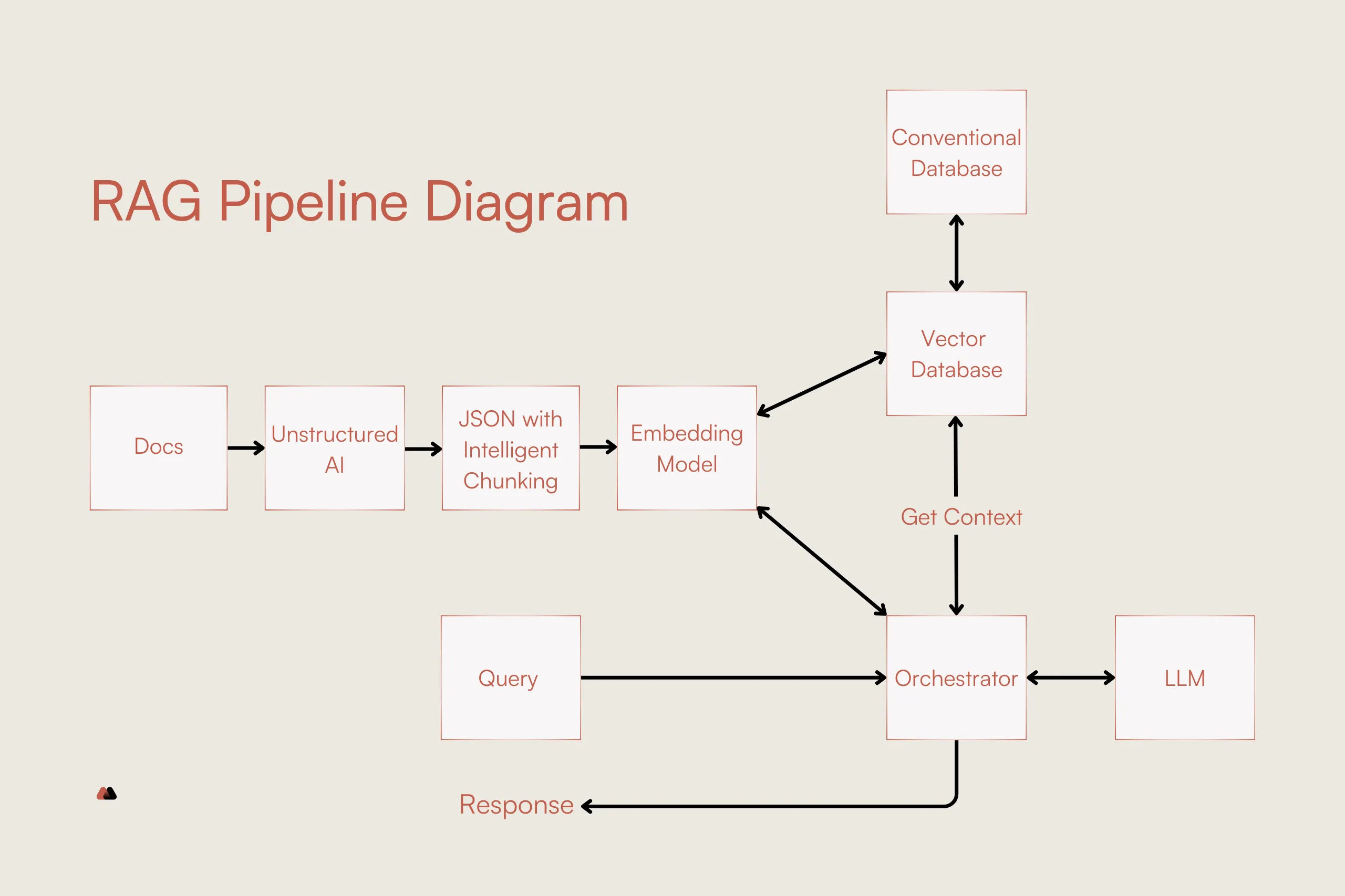
IV. How This Connects to LLM and RAG Systems
Table recognition is not an isolated computer vision task—it directly shapes how LLMs reason.
A well-recognized table can be:
- Converted into structured formats (JSON, CSV, Markdown)
- Chunked meaningfully for embedding
- Queried precisely using hybrid retrieval (text + structure)
Poor table recognition, by contrast, leads to fragmented embeddings, lost numerical context, and hallucinated aggregations. This is why modern RAG pipelines increasingly treat document parsing as a first-class system component rather than a preprocessing afterthought.
The broader lesson extends beyond tables. The same principles apply to forms, charts, and diagrams: layout is semantics. As LLM applications move deeper into enterprise and research workflows, layout-aware understanding becomes a prerequisite for trustworthy AI systems.
Acknowledgements
This resource synthesizes ideas from classical document analysis, open-source tooling, and deep learning research in document understanding. It is intended as a conceptual map rather than a model leaderboard—use it to choose the right level of complexity for your problem, not the most fashionable architecture.
Comments (0)