LLMs Large Models (LLMs) RAG Edition Analysis — Text Chunking (18)
Quick Overview
This practical learning guide analyzes text chunking for Retrieval-Augmented Generation (RAG) with Large Language Models, covering why chunking is necessary, common strategies (fixed-length, sentence-level, etc.), effects on embeddings, retrieval quality, semantic integrity, and cost-performance trade-offs.
Large Language Models (LLMs) × RAG
A Practical Learning Guide to Text Chunking
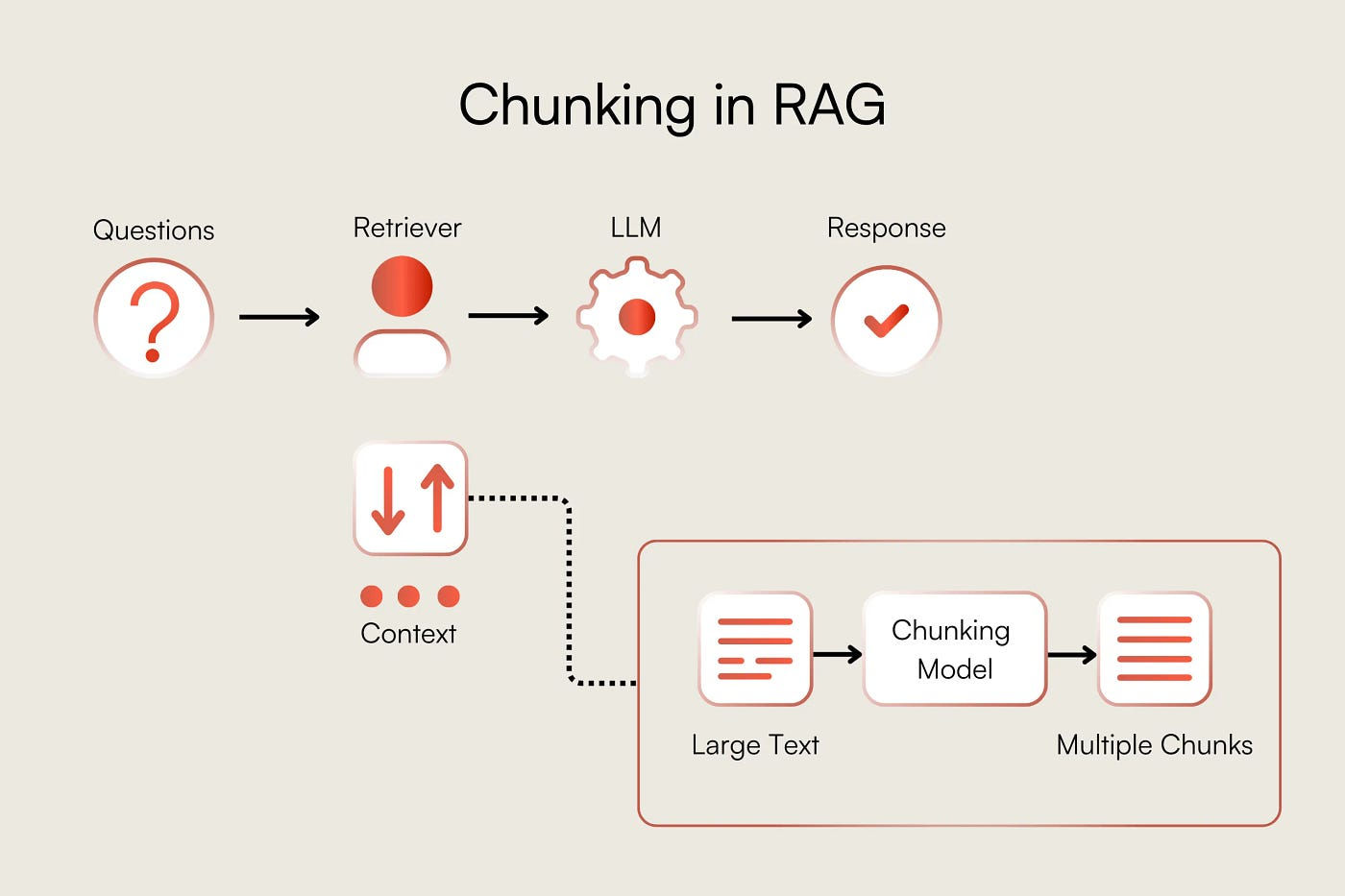
Text chunking looks deceptively simple, but in Retrieval-Augmented Generation (RAG) systems it is one of the highest-leverage design decisions you will ever make. Chunking determines what the model sees, what gets embedded, and ultimately what can be retrieved and reasoned over. This guide is written as a learning-focused resource: it explains why chunking exists, how different strategies behave in practice, and where each method is most useful beyond textbook examples.
I. Why Text Chunking Is Necessary
Large Language Models operate under hard context window limits. Even with modern long-context models, feeding an entire book, codebase, or multi-year report directly into a model is inefficient, expensive, and often counterproductive. Chunking is the mechanism that turns an unbounded document into manageable, retrievable units.
Beyond context length, chunking directly affects semantic integrity. If chunks are too large, retrieval becomes noisy: irrelevant sections dilute signal and confuse generation. If chunks are too small, meaning fractures: definitions lose explanations, arguments lose premises, and answers become shallow or incorrect. Chunking is therefore a balancing act between completeness and precision.
Cost and performance also matter. Token usage scales linearly with input size. Poor chunking inflates embedding costs, slows retrieval, and degrades answer quality when irrelevant context dominates the prompt. Well-designed chunking strategies are one of the simplest ways to improve both accuracy and efficiency without touching the model itself.
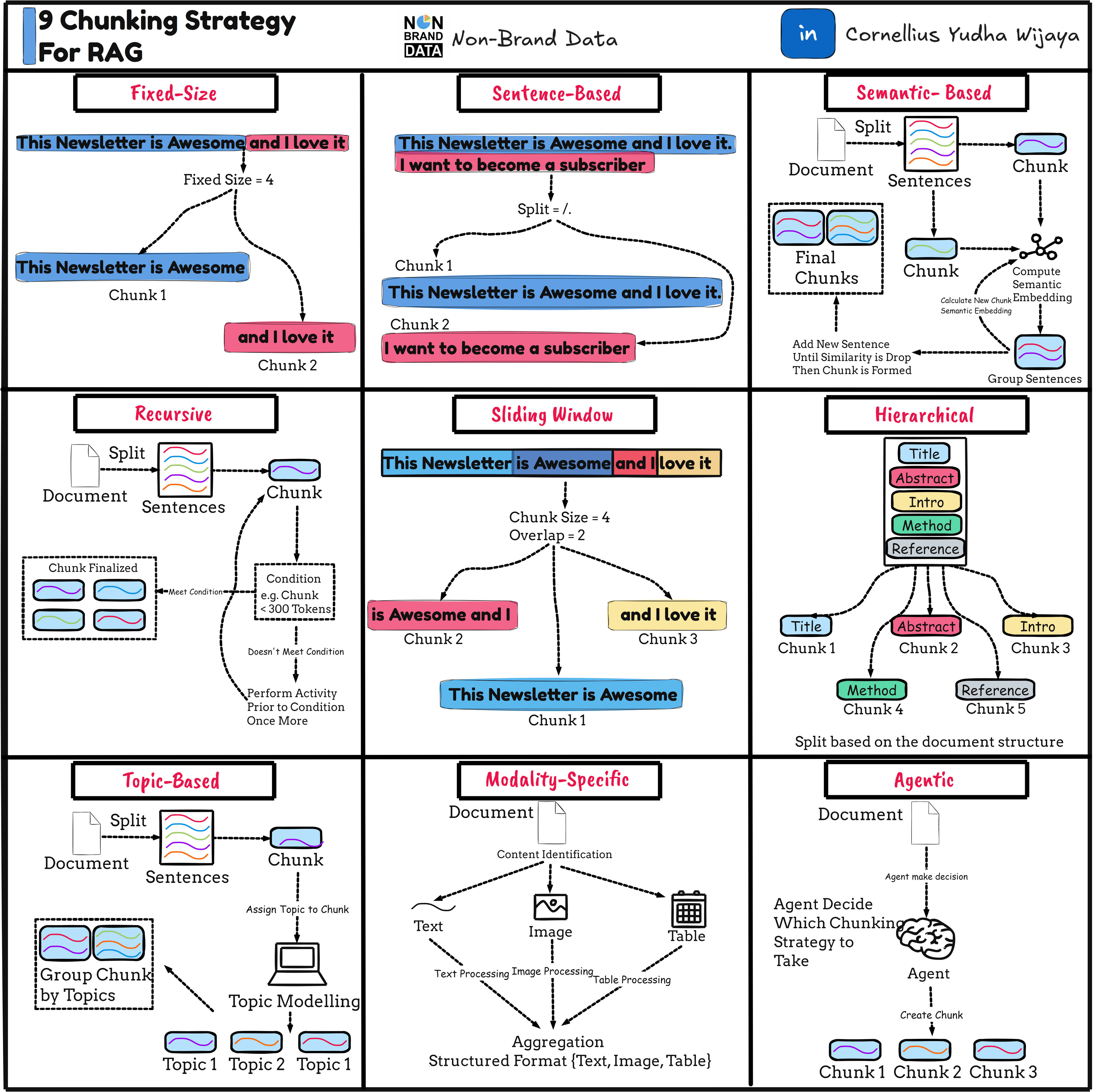
II. Common Text Chunking Methods (and When They Matter)
1. Simple Fixed-Length Chunking
The most basic approach splits text by a fixed number of characters or tokens. It is easy to implement and fast to run, which makes it attractive for quick prototypes or internal tools.
However, this method is blind to language structure. Sentences, paragraphs, and even words may be split in half. While usable for rough semantic search, it often underperforms for question answering or reasoning-heavy tasks. In practice, fixed-length chunking is best treated as a baseline rather than a final solution.
2. Sentence-Level Chunking
Sentence-based chunking improves semantic coherence by ensuring each chunk aligns with natural language boundaries. This approach is often sufficient for articles, blog posts, and documentation where sentences carry independent meaning.
The tradeoff is variability. Some sentences are short and dense; others are long and complex. A single long sentence can exceed ideal chunk size, while multiple short sentences may not provide enough context. Sentence chunking works best when paired with downstream logic that groups sentences into larger semantic units.
3. Linguistic Chunking with spaCy
Using NLP libraries such as spaCy introduces linguistic awareness into chunking. Instead of relying purely on punctuation, sentence boundaries are inferred from grammatical structure and language models.
This method shines when dealing with noisy text, abbreviations, or domain-specific writing where punctuation is unreliable. It is particularly useful in legal, biomedical, or academic documents. The downside is additional dependency complexity and runtime overhead compared to simpler approaches.
4. Character-Based Chunking in LangChain
Character-based splitters are widely used in RAG pipelines because they integrate cleanly with document loaders and vector stores. By configuring chunk size, overlap, and separators, you gain control over retrieval granularity.
These splitters are powerful but unforgiving. Poor parameter choices can silently degrade system quality by breaking semantic units or creating excessive redundancy. Character-based methods work best when document structure is simple or when paired with recursive strategies.
5. Recursive Character Chunking (LangChain)
Recursive chunking improves on naïve character splitting by attempting larger semantic boundaries first—paragraphs, then lines, then words, and finally characters only as a last resort.
This approach is one of the most robust general-purpose strategies for RAG. It adapts to document structure without requiring manual separator tuning and performs well across essays, technical docs, and reports. For most text-heavy RAG systems, recursive chunking is the safest default choice.
6. HTML-Aware Chunking
HTML chunking leverages document structure explicitly. Headings, sections, and nested elements become natural chunk boundaries, while metadata preserves hierarchical context.
This method is essential when ingesting web pages, knowledge bases, or scraped documentation. By aligning chunks with semantic sections, retrieval becomes more precise and generation more grounded. HTML chunking also enables advanced use cases such as section-aware ranking or header-based filtering.
7. Markdown-Aware Chunking
Markdown chunking mirrors HTML chunking but is tailored for developer documentation, READMEs, and knowledge repositories. Headings define semantic scope, while code blocks and lists remain intact.
For technical RAG systems—especially those targeting engineers—Markdown-aware chunking dramatically improves answer quality. It preserves conceptual boundaries and prevents destructive splitting of examples or explanations.
8. Python Code Chunking
Code is not prose. Splitting code arbitrarily can break syntax, destroy logical flow, and introduce hallucinations when the model tries to “repair” incomplete blocks.
Code-aware chunkers respect function boundaries, class definitions, and control structures. Overlap is typically avoided to prevent semantic duplication or syntactic corruption. This approach is critical for code search, debugging assistants, and developer-facing copilots.
9. LaTeX Chunking
LaTeX documents encode structure through commands rather than layout. Chunking based on sections, subsections, and environments preserves semantic grouping that would otherwise be lost in raw text extraction.
This method is especially valuable for academic papers, research notes, and scientific documentation. It enables accurate retrieval of definitions, proofs, and experimental descriptions without flattening mathematical structure.
III. Chunking as a System Design Decision
Chunking does not exist in isolation. It shapes embedding quality, vector database performance, retrieval recall, and final generation accuracy. The “best” chunking strategy depends on document type, query patterns, and downstream usage.
A common mistake is optimizing chunking in isolation. In practice, chunking should be evaluated end-to-end: retrieval results, answer correctness, latency, and cost. Small changes in chunk size or overlap often produce outsized improvements when aligned with real query behavior.
Closing Perspective
Text chunking is not a preprocessing detail—it is a core architectural layer in LLM systems. As models evolve, context windows grow, and multimodal inputs expand, chunking strategies will continue to adapt. The underlying principle remains the same: respect structure, preserve meaning, and optimize for retrieval, not ingestion.
Acknowledgements
This learning hub draws on practical experience from RAG system design, open-source tooling, and real-world document pipelines. It is intended as a conceptual guide rather than a prescriptive rulebook—use it to reason about tradeoffs, not to blindly copy defaults.
Comments (0)