Experimentation Under Network Interference
Asked of: Data Scientist
Last updated
-
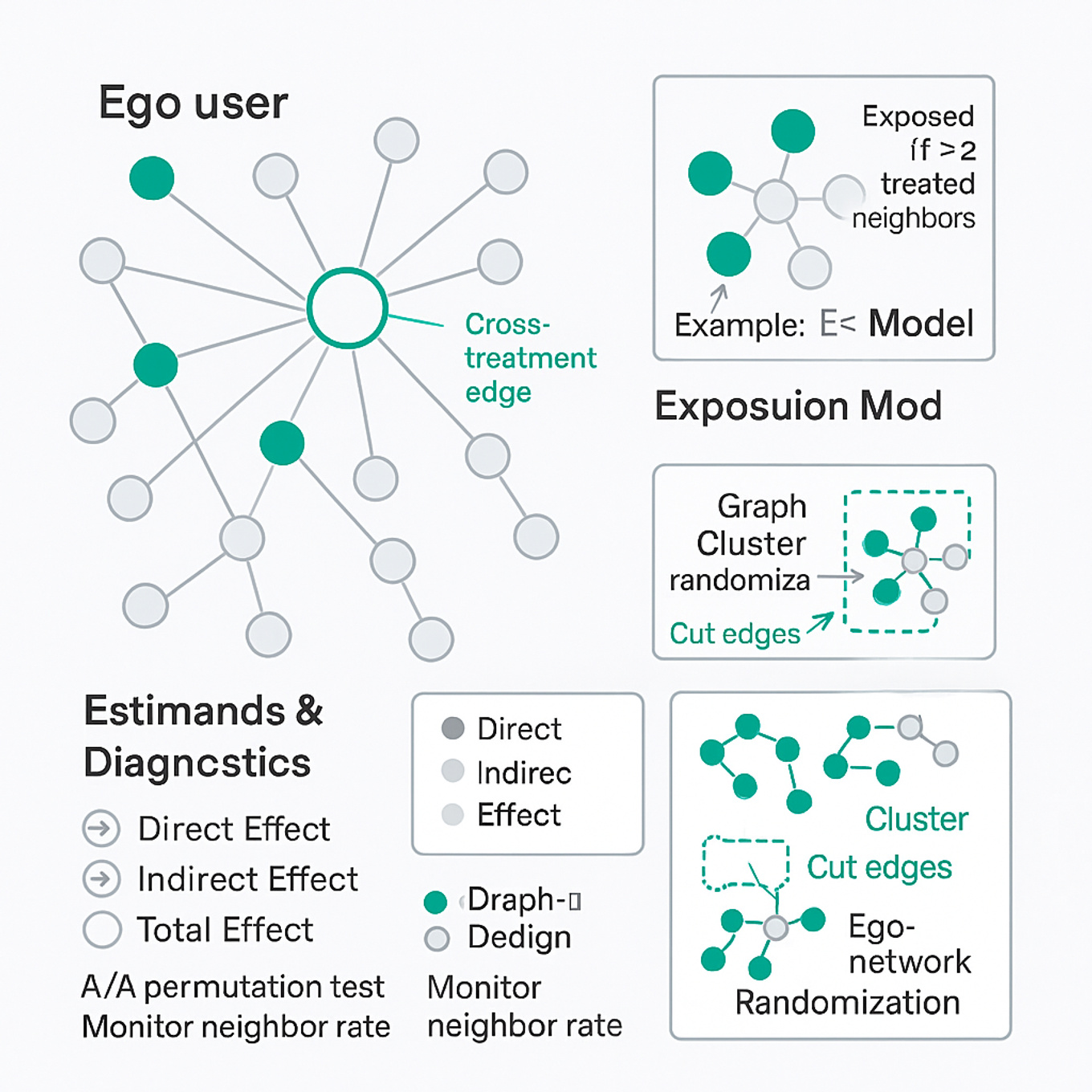
What it is Experimentation under network interference is when one unit’s outcome is affected by other units’ treatment assignments, violating the “no interference” part of SUTVA. It shows up in social graphs, marketplaces, and recommendation systems where actions spill across connections (friends, buyers-sellers, viewers-creators).
-
Why interviewers ask about it At companies like Meta, product changes propagate through graphs: a small tweak to sharing, invites, feed ranking, or notifications can affect friends-of-friends. If you run a plain user-level A/B test, estimates can be biased or diluted, leading to bad launch decisions and user or creator harm at scale.
-
Core ideas to know
- Interference types: direct effect on treated users vs. spillovers on neighbors; define your estimand (e.g., total, direct, indirect, global average effects).
- Exposure models: specify when a unit is “exposed” (e.g., k treated neighbors) to make analysis tractable.
- Designs that mitigate bias: graph cluster randomization, ego-network designs, or edge-level randomization to limit cross-treatment edges.
- Estimation: use exposure-aware estimators (e.g., Horvitz–Thompson with exposure probabilities) instead of simple difference-in-means.
- Power and variance: clustering reduces contamination but increases variance; plan larger samples and measure cut edges between clusters.
- Diagnostics: pretest for interference (A/A with permutation/randomization tests), monitor neighbor-treatment rates, and audit leakage across clusters.
- Practical levers: throttling invites, seeding limited communities, switchbacks for temporal spillovers, and marketplace-wide holds for global shocks.
-
A common pitfall Candidates often propose “just cluster by user ID hash” or “randomize at user level and hope neighbors are rare.” In dense graphs (feeds, messaging), this creates heavy cross-treatment edges and biased estimates. Another miss is failing to predefine exposure conditions and compute exposure probabilities, making downstream estimators invalid. Finally, people forget that marketplace or ranking changes can create near-global interference, requiring geo- or network-wide holdouts rather than user-level tests.
-
Further reading
- Design and Analysis of Experiments in Networks: Reducing Bias from Interference — overview of interference, designs, estimands, and analysis from industry-facing researchers. (degruyterbrill.com)
- Graph Cluster Randomization — seminal method to randomize by graph clusters and formalize exposure conditions; foundational for social-network A/B tests. (arxiv.org)
- Testing for arbitrary interference on experimentation platforms (LinkedIn) — practical detection strategy and platform learnings; useful for “should we worry about interference here?” (academic.oup.com)
Related concepts
- Cluster Randomized Experiments And Network InterferenceAnalytics & Experimentation
- Clustered And Networked Experiments
- Network Interference And Cluster RandomizationAnalytics & Experimentation
- Marketplace Interference And Switchback ExperimentsAnalytics & Experimentation
- Notification Experiment Design and Tradeoffs
- Statistical Inference For Experiments