
What this guide covers
This is a practical preparation guide for the Google Machine Learning Engineer (MLE) loop. It is for software engineers and applied ML practitioners who already know the basics and want to know exactly what each round tests, where candidates lose points, and how to prepare for the parts that are distinctly Google. You will get a round-by-round breakdown, a scoring rubric for what "strong" looks like, an ML system design checklist, and example answers you can adapt.
The single most useful thing to internalize up front: Google evaluates MLEs on three axes at once - software engineering rigor, applied ML judgment, and production ML systems thinking. Candidates who prepare only the modeling topics are usually the ones who get a "no hire" on the coding rounds.
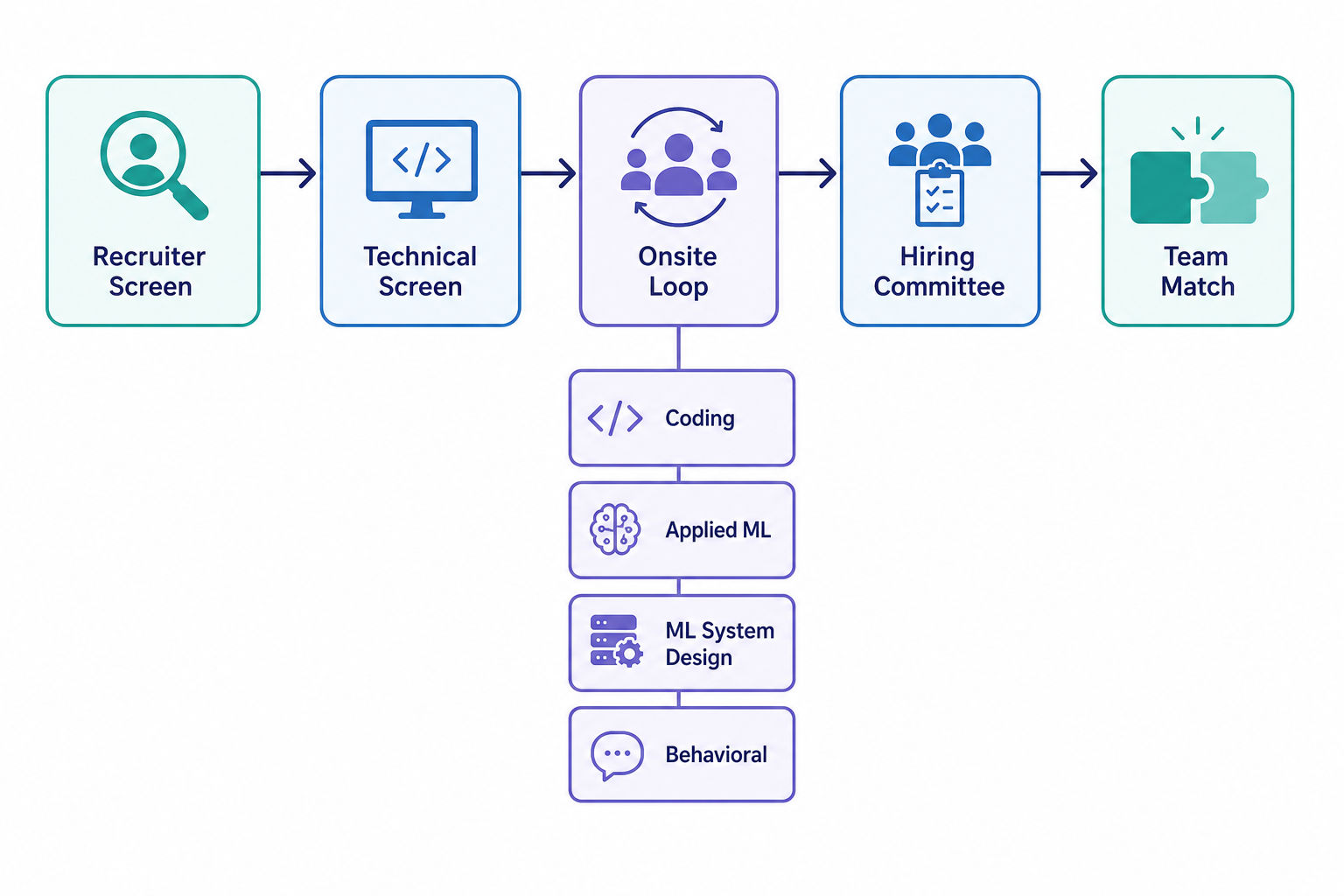
The interview process at a glance
The typical flow is a recruiter screen, a coding-heavy technical screen, a virtual onsite of three to five interviews, then hiring committee review and team matching. A point worth planning around: team matching can take longer than the loop itself, so a strong interview does not always translate into a fast offer. The interview packet you build is reused across very different teams, which is why your stories need to generalize.
| Stage | Format | Length (typical) | Primary signal |
|---|---|---|---|
| Recruiter screen | Phone / video | 20-30 min | Fit, motivation, track placement |
| Technical screen | Live coding | ~45 min | DSA fluency, communication |
| Coding rounds (1-2) | Live coding | 45-60 min each | Algorithms, trade-offs, testing |
| Applied ML round | Discussion | 45-60 min | Modeling judgment, metrics, debugging |
| ML system design | Collaborative diagram | 45-60 min | End-to-end production thinking |
| Behavioral / Googliness | Conversation | ~45 min | Collaboration, ambiguity, influence |
| Hiring committee | Internal review | n/a | Consistency across rounds, leveling |
| Team matching | Manager conversations | Days to weeks | Domain alignment |
You can warm up on the exact problem types in the Google company page and the broader question bank. For role-specific framing, see Machine Learning Engineer roles.
Interview rounds in detail
Recruiter screen
A 20 to 30 minute conversation about your background, domain fit, and logistics. Be ready to explain why you want an ML engineering role at Google, what kinds of ML systems you have actually built, and which areas interest you - ranking, recommendation, LLMs, or applied infrastructure. Recruiters use this step to place you on a track: software-heavy ML, applied ML, or something closer to research. Pick your framing deliberately, because it shapes which interviewers you draw.
Initial technical screen
Usually a single 45 minute live coding interview in a shared editor. It emphasizes data structures and algorithms: arrays, strings, hash maps, trees, graphs, BFS and DFS, dynamic programming, and optimization follow-ups. Even for ML roles, Google leans hard on coding fluency, correctness, complexity analysis, and how clearly you narrate while solving. Treat this exactly like an SWE screen - the ML content comes later.
Coding / algorithms rounds
In the onsite you will usually face one to two coding rounds of 45 to 60 minutes each. These test core engineering ability through Google-style algorithm problems, typically with follow-ups about optimization, trade-offs, and edge cases rather than a single one-shot answer. Interviewers reward structured decomposition, clean code, thoughtful test cases, and your ability to improve a solution when given a hint. A correct brute force that you then optimize out loud usually scores better than a half-finished "optimal" attempt.
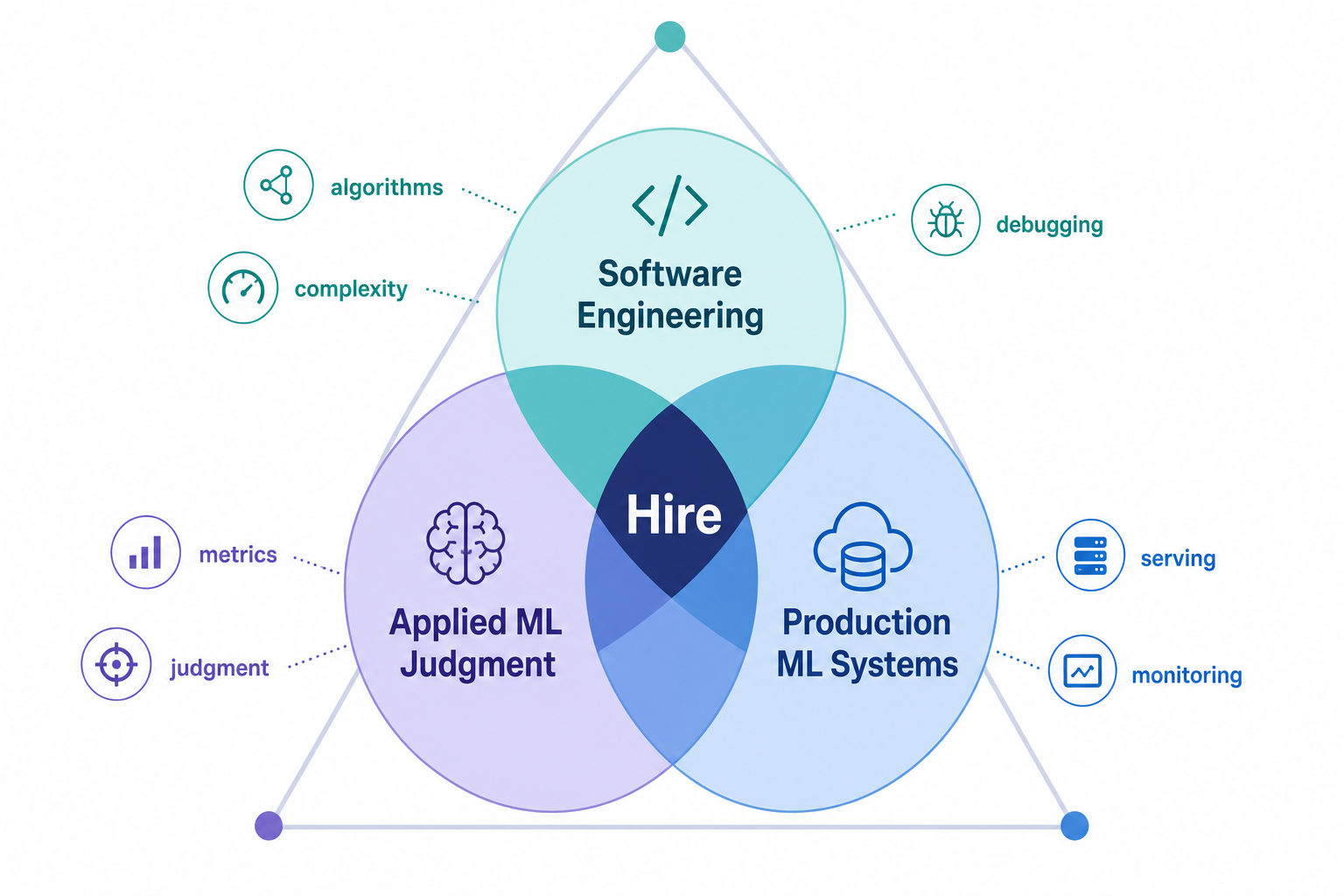
Applied ML round
A 45 to 60 minute discussion, mostly not coding. Expect model evaluation, the bias-variance trade-off, regularization, data leakage, feature engineering, class imbalance, error analysis, offline versus online metrics, and experimentation basics. For stronger or more senior candidates this often becomes a deep dive into a past project: what you decided when performance changed or constraints shifted. The interviewer is probing whether your choices were driven by the product goal or by reflex.
ML system design round
Typically 45 to 60 minutes, often with collaborative diagramming in a shared tool. You might be asked to design a recommendation system, ranking pipeline, spam or fraud detector, search relevance stack, personalization system, or an LLM-powered feature with latency and serving constraints. Google expects end-to-end thinking: data collection, labeling, feature pipelines, training, serving, monitoring, drift detection, retraining, reliability, and fallback behavior. See the dedicated checklist below.
Behavioral / Googliness / leadership round
Around 45 minutes, conversational, and genuinely scored - not a formality. Google evaluates how you collaborate, handle ambiguity, influence without authority, respond to failure, and disagree constructively without ego. Strong answers are specific and technical, with clear trade-offs, stakeholder context, and what you changed after learning something did not work. Vague "we shipped it and it went well" answers are a common way to underperform here.
Hiring committee review
An internal review, not a live interview. The committee looks for consistent evidence across rounds, makes the leveling decision, and determines whether the packet supports a hire. Because this step is real and independent, even a strong loop can sit in review for a while. The practical takeaway: make sure every round leaves clear written evidence of your signal, because the committee reads notes, not vibes.
Team matching
After clearing the loop you may have one or more conversations with hiring managers over days or weeks, focused on domain alignment and product needs. The same packet can fit very different ML problem spaces, so come with a clear sense of what you want to work on. Curiosity about the team's actual problems goes a long way here.
What "strong" looks like - a quick rubric
Use this as a self-check before each round. The goal is to recognize the difference between an answer that passes and an answer that earns a strong signal.
| Dimension | Weak answer | Strong answer |
|---|---|---|
| Coding | Jumps to code, silent, no tests | States approach + complexity first, narrates, adds edge-case tests |
| Complexity | "It's fast enough" | Names time/space, identifies the bottleneck, proposes a trade-off |
| ML metrics | "I used accuracy" | Picks metrics from the product goal, explains why accuracy misleads under imbalance |
| Debugging a regression | "Retrain the model" | Isolates data vs. model vs. serving, checks for leakage and distribution shift |
| System design | Boxes labeled "model" and "DB" | Data, labeling, features, serving, monitoring, drift, retraining, fallback |
| Behavioral | "The team did X" | "I did X, here was the trade-off, here is what I changed after it failed" |
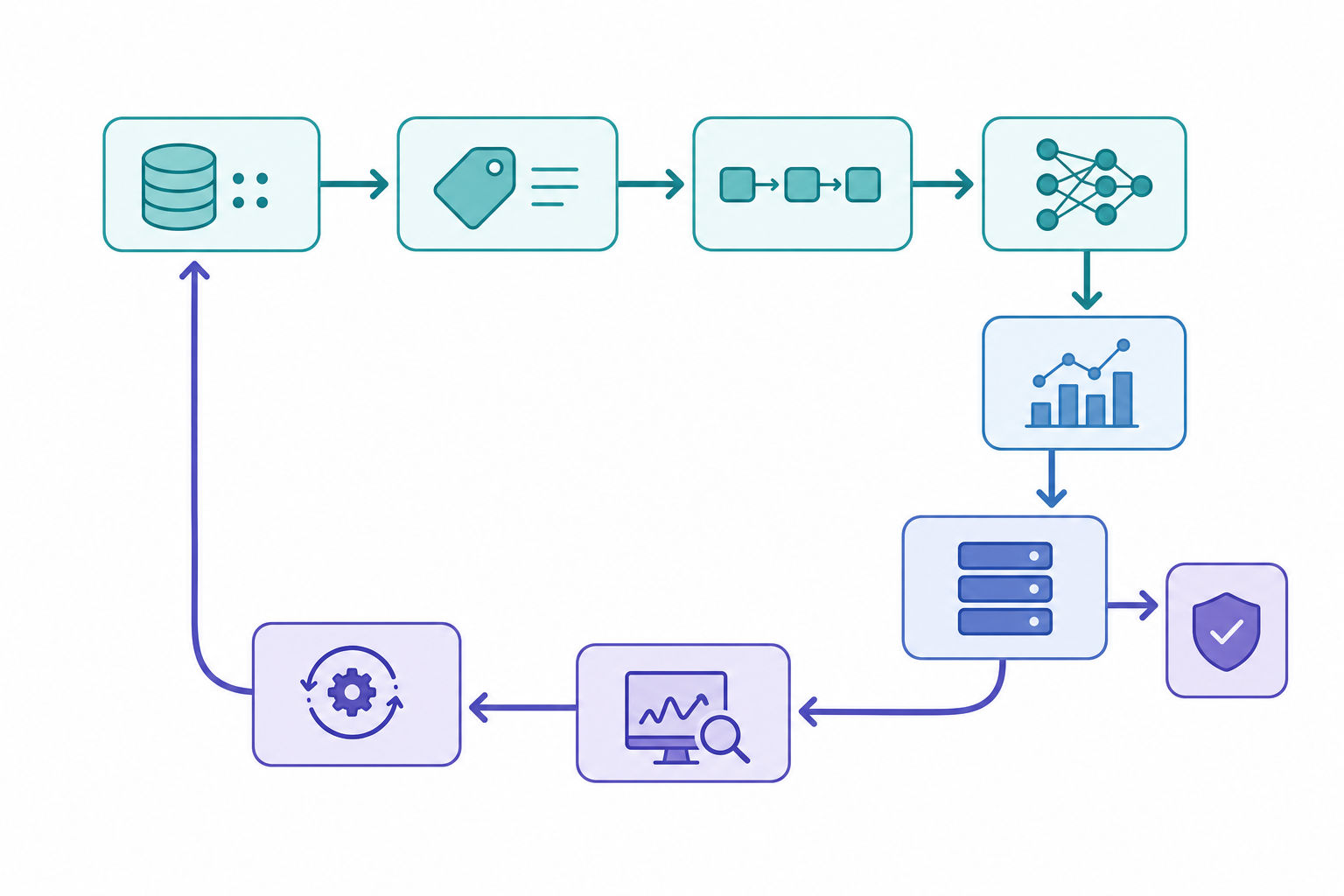
ML system design: a checklist that scales
Most candidates lose points by drawing a model and a database and stopping. Walk the full lifecycle out loud and check off these stages explicitly. For instance, if asked to design a recommendation feed, narrate each stage rather than jumping to the model.
- Problem framing. Restate the goal as an ML objective. What is the prediction target? What is the business metric it should move, and what is the proxy you can actually train on?
- Data and labels. Where does training data come from? How are labels generated - explicit feedback, implicit signals, human raters? What is the labeling latency and noise?
- Features. Batch vs. streaming features, a feature store for train/serve consistency, and how you prevent training/serving skew.
- Modeling. Start simple (a strong baseline), then justify added complexity. State the loss function and why it matches the objective.
- Evaluation. Offline metrics that correlate with the online goal, plus an online experiment plan (A/B test, guardrail metrics).
- Serving. Online vs. batch inference, latency budget, throughput, caching, and cost per query.
- Monitoring and drift. What you watch in production: input distribution shift, prediction drift, calibration, and the business metric itself.
- Retraining and rollback. Retraining cadence and triggers, plus a safe fallback (a simpler model or heuristic) when the primary system degrades.
A useful habit: after you sketch the happy path, ask yourself "what happens when this component fails?" and design the fallback. Interviewers consistently reward candidates who design for failure, not just for the demo.
Example answers
These are illustrative templates, not quotes from any real interview. Adapt them to your own experience.
Example answer (choosing a metric). "For a fraud detector, accuracy is misleading because fraud is rare - a model predicting 'never fraud' could look 99% accurate. I'd anchor on recall at a fixed precision, or PR-AUC, because the cost of a missed fraud differs from a false alarm. I'd confirm the operating threshold with the product team based on review capacity."
Example answer (debugging a regression). "When a ranking model's online metrics dropped after a clean offline win, I'd first rule out training/serving skew, then check for a feature that went stale or a distribution shift in traffic. For instance, a feature that depends on a logging pipeline can silently go null when that pipeline changes, which the offline eval wouldn't catch."
Example answer (behavioral, constructive disagreement). "I disagreed with shipping a heavier model because the latency budget was tight. Rather than block it, I proposed an experiment: ship the lighter model as the baseline and gate the heavy one behind a latency guardrail. The data settled the debate, and we kept the faster system."
How to stand out
- Treat DSA as a first-class part of prep, not a side topic. Google still expects MLEs to solve medium-to-hard problems and explain complexity clearly. Drill the patterns on the question bank.
- Prepare one end-to-end ML project story covering business goal, data, labeling, features, model choice, launch, monitoring, failure modes, and what you changed after deployment.
- In system design, give operational details instead of generic blocks: latency budgets, data freshness, offline and online metrics, retraining triggers, drift signals, fallback behavior.
- Practice solving out loud. Interviewers care how you reason, refine assumptions, and respond to hints, not only whether you land the final answer.
- Rehearse virtual whiteboarding. The design round often uses shared tools, so be comfortable sketching architectures while narrating trade-offs.
- Prepare behavioral examples that show constructive disagreement, humility, and influence without authority.
- Ask your recruiter to clarify the exact loop for your level and org. The process varies, and knowing whether you'll have separate ML design and behavioral rounds helps you target prep.
How to Use This Page as a Prep Plan
Do not treat this as passive reading. Convert the ideas in this page into a short weekly loop: learn one idea, practice it under interview conditions, then write down what changed. That is the fastest way to turn advice into visible interview behavior.
| Prep area | What you need to prove | Practice artifact |
|---|---|---|
| Coding fluency | Explain the brute force path, then optimize aloud. | Two timed problems plus a written postmortem. |
| ML fundamentals | Connect concepts to concrete model behavior. | One concept note with examples and failure cases. |
| System design | Discuss data, training, serving, monitoring, and cost. | One diagram with bottlenecks and tradeoffs. |
| Interview execution | Stay calm while clarifying, testing, and revising. | One mock interview and a short feedback log. |
For Google Machine Learning Engineer Interview Guide 2026, the strongest candidates usually do three things well: they make their assumptions explicit, they use concrete examples instead of vague claims, and they review mistakes quickly enough that the next practice rep is better than the last one.
Video Walkthrough
This verified YouTube video gives a second pass on the same preparation area. Use it after reading the guide, then come back and turn the advice into a practice artifact.
FAQ
How much coding should I expect in a Google ML engineer interview?
A lot. Plan for a coding screen plus one or two onsite coding rounds of standard Google algorithm difficulty. The ML rounds are separate. Many candidates who over-index on modeling and under-prepare DSA fail on the coding signal, so balance your prep.
Do I need to know LLMs and transformers in depth?
Be comfortable discussing transformers and embeddings at a conceptual level, and understand LLM product constraints like serving cost, latency, and evaluation. Depth expectations vary by team - a Gemini-adjacent team will probe further than a classic ranking team. Confirm the focus with your recruiter.
What is the difference between the applied ML round and the system design round?
The applied ML round is a discussion of modeling judgment: metrics, evaluation, the bias-variance trade-off, debugging a model. The system design round is about the full production pipeline - data, features, serving, monitoring, retraining, and fallback. One tests how you think about models; the other tests how you ship them.
How long does the whole process take?
It varies widely. The loop itself can be scheduled within a few weeks, but hiring committee review and team matching can add more time, sometimes the longest part. Treat the timeline as unpredictable and keep other options open until you have an offer.
What is "Googliness" and how is it scored?
It is the behavioral signal covering collaboration, handling ambiguity, influence without authority, and constructive disagreement. It is genuinely scored, not a formality. Strong answers are specific, technical, and include what you changed after something did not work - not generic "great teamwork" statements.
Where can I practice real Google interview questions?
Browse the Google company page for company-specific questions, the full question bank for DSA and ML topics, and more interview guides for other roles and companies.