SQL Analytical Querying And Data Modeling
Asked of: Data Scientist
Last updated
What's being tested
You’re being tested on analytical SQL for product and causal analysis: converting raw event, login, session, and panel tables into trustworthy user-level or time-level metrics. Interviewers look for clean use of joins, deduplication, window functions, temporal logic, and aggregation that supports Data Scientist decisions, not data-pipeline design.
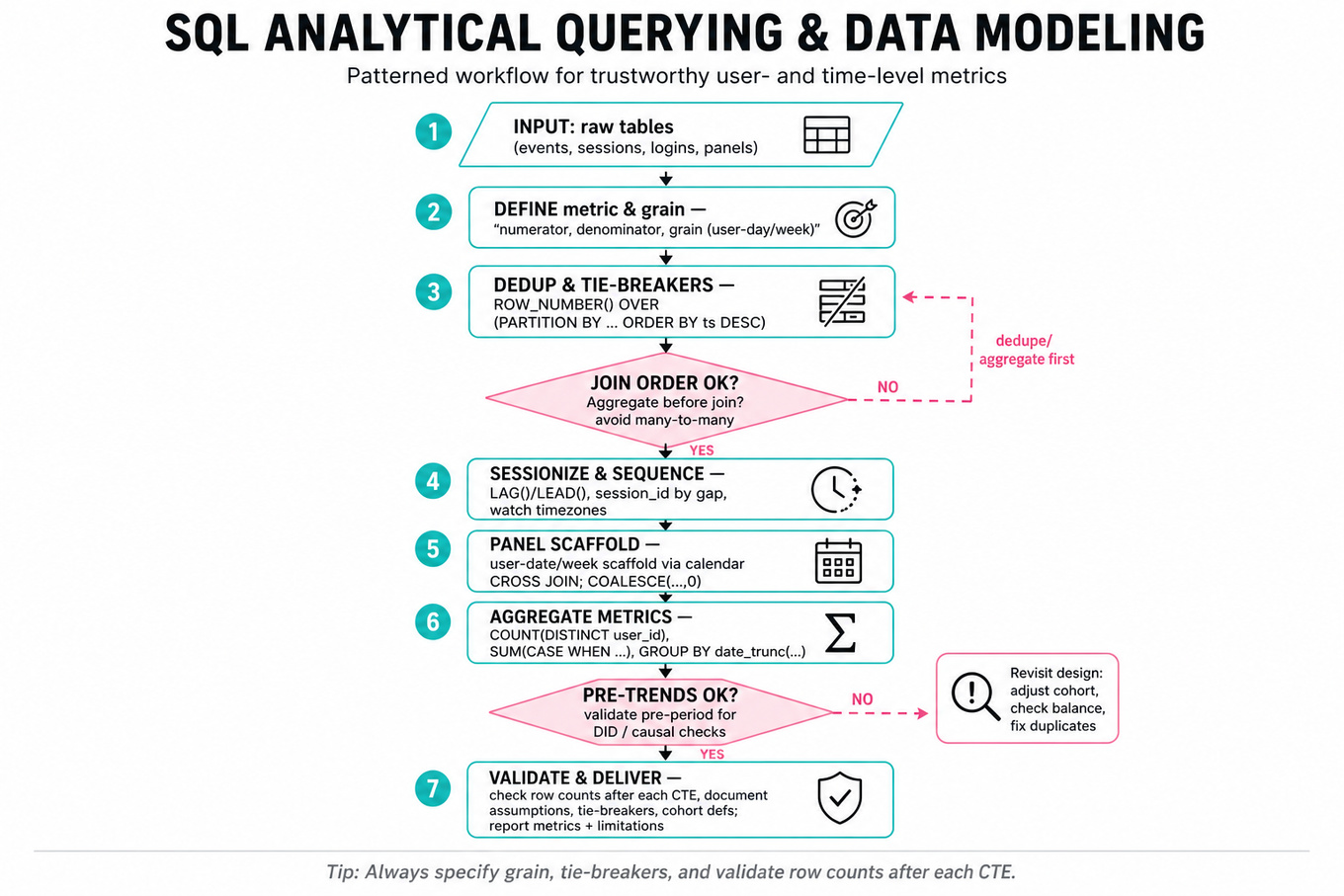
Patterns & templates
-
User/event aggregation with
COUNT(DISTINCT user_id),SUM(CASE WHEN...), andGROUP BY date_trunc(...); define numerator, denominator, and grain first. -
Window functions like
ROW_NUMBER(),LAG(),LEAD(), andRANK() OVER (PARTITION BY ... ORDER BY ...); always specify tie-breakers. -
Session and event sequencing by timestamp using
LAG(event_ts)orLEAD(event_ts); watch time zones, missing events, and duplicate logs. -
Panel construction via user-date or user-week scaffolds using
CROSS JOINcalendar tables; fill missing periods withCOALESCE(..., 0). -
Causal-analysis prep for DID: create
treated,post, and interaction terms; estimate effect as after validating pre-trends. -
Cross-channel attribution using conditional distinct counts and set logic; decide whether users can belong to multiple channels or require mutually exclusive assignment.
-
Efficient large-table SQL: filter early with
WHERE, aggregate before joining, avoid accidental many-to-many joins, and inspect row counts after each CTE.
Common pitfalls
Pitfall: Counting events instead of users. If the metric is user proportion, use
COUNT(DISTINCT user_id), not raw login rows.
Pitfall: Joining before deduplicating. A many-to-many join can silently inflate engagement, hours, or treatment effects.
Pitfall: Treating SQL output as final analysis. For DS work, explain assumptions, metric grain, cohort definitions, and validation checks.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Featured in interview prep guides
Practice questions
- Find recommended friend pairs by shared songsAmazon · Data Scientist · Technical Screen · medium
- Write SQL window functions for D7 retentionAmazon · Data Scientist · Technical Screen · medium
- Find daily first-order merchants with SQLAmazon · Data Scientist · Technical Screen · medium
- Design student–course data models and SQLAmazon · Data Scientist · Onsite · medium
- Compute join counts and window ranksAmazon · Data Scientist · Onsite · medium
- Diagnose MySQL joins and GROUP BY/HAVING errorsAmazon · Data Scientist · Take-home Project · medium
- Find top-spend categories per customer with rankingAmazon · Data Scientist · Onsite · medium
- Compute daily work hours from in/out eventsAmazon · Data Scientist · Onsite · medium
- Calculate cross-channel login user proportionsAmazon · Data Scientist · Onsite · medium
- Design SQL/Pandas aggregations on retail schemaAmazon · Data Scientist · Technical Screen · medium
- Build DID panel and compute effects in SQLAmazon · Data Scientist · HR Screen · medium
- Analyze User Engagement with SQL QueriesAmazon · Data Scientist · Onsite · medium
Related concepts
- SQL Analytical QueryingData Manipulation (SQL/Python)
- SQL AnalyticsData Manipulation (SQL/Python)
- SQL And Python Data ManipulationData Manipulation (SQL/Python)
- SQL Analytics Joins, Aggregations, And Windows
- SQL Analytics And Event Data ManipulationData Manipulation (SQL/Python)
- SQL Window Functions And AnalyticsData Manipulation (SQL/Python)