Amazon Data Scientist Interview Prep Guide
Everything Amazon actually asks Data Scientist candidates — concept walkthroughs, worked examples, and the real interview questions, drawn from candidate reports. Free to read.
Last updated

Technical Screen
Data Manipulation (SQL/Python)
-
SQL Analytical Querying And Data Modeling — covered in depth under Take-home Project below.
-
Python/Pandas Data Manipulation — covered in depth under Onsite below.
Analytics & Experimentation
-
A/B Testing And Statistical Inference — covered in depth under Onsite below.
-
Product Metrics, Root-Cause Analysis And Visualization — covered in depth under Onsite below.
Statistics & Math
- Propensity Score Matching — covered in depth under Onsite below.
Machine Learning
-
Supervised ML Fundamentals, Evaluation And Feature Engineering — covered in depth under Onsite below.
-
ML System Design, Recommenders, Forecasting And Allocation — covered in depth under Onsite below.
What's being tested
Interviewers are probing whether you can reason about retrieval-augmented generation as an applied ML system: when it is preferable to fine-tuning, how to evaluate answer quality, and how to control hallucination, latency, and cost. For a Data Scientist, the emphasis is not on building the serving stack, but on defining success metrics, designing offline and online evaluations, diagnosing failure modes, and making evidence-based tradeoffs. Amazon cares because many internal and customer-facing products depend on accurate answers over changing catalogs, policies, reviews, support docs, and seller content. A strong answer connects model behavior to business risk: wrong answers, unsupported claims, poor coverage, high inference cost, and degraded customer trust.
Core knowledge
-
RAG pipeline anatomy: a typical system has document selection, chunking, embedding, vector retrieval, optional lexical retrieval, reranking, prompt construction, generation, and post-generation validation. As a DS, focus on which stage explains failures: missing document, bad chunk, weak ranking, poor prompt grounding, or model hallucination.
-
RAG vs. fine-tuning: use RAG when knowledge changes frequently, answers require citations, or the source corpus is large and dynamic. Use fine-tuning when you need style, task format, domain-specific reasoning patterns, or classification behavior. Fine-tuning usually does not reliably “store” thousands of facts and can still hallucinate.
-
Retrieval metrics: evaluate retrieval before generation using
Recall@k,Precision@k,MRR, andnDCG@k. If the correct supporting passage appears in the top , retrieval recall is high; if it appears near rank 1,MRRandnDCGimprove. Poor retrieval caps final answer quality no matter how strong the LLM is. -
Answer-quality metrics: evaluate final responses on faithfulness, answer correctness, citation accuracy, coverage, refusal quality, and helpfulness. For factual systems, split “is the answer true?” from “is the answer supported by retrieved context?” because a true answer can still be ungrounded.
-
Human evaluation design: create a labeled test set stratified by query type: lookup, comparison, multi-hop, ambiguous, out-of-scope, freshness-sensitive, and adversarial. Use blinded raters, rubric-based labels, inter-rater agreement such as Cohen’s kappa, and adjudication for ambiguous cases.
-
Offline-to-online gap: offline metrics like
Recall@5and judge-rated correctness are necessary but not sufficient. Online metrics may includeCTR, task completion, deflection rate, escalation rate, answer acceptance, repeat-contact rate, refund/contact outcomes, and guardrail metrics like harmful-answer rate. -
Cost metrics: total expected cost per query is roughly where is retrieved candidates and is token count. DS tradeoffs include reducing
top_k, compressing context, using cheaper rerankers, caching frequent answers, or routing simple queries to smaller models. -
Chunking tradeoffs: small chunks improve precise retrieval but can lose context; large chunks preserve context but add noise and token cost. Common starting points are 200–800 tokens with overlap, then tune using retrieval recall and downstream answer accuracy rather than arbitrary chunk size.
-
Embedding tradeoffs: higher-dimensional embeddings can improve semantic resolution but increase storage, retrieval cost, and risk of overfitting to benchmark-like queries. Compare embedding models with a fixed evaluation set, including domain-specific synonyms, abbreviations, multilingual queries, and entity-heavy queries.
-
Hybrid retrieval: dense retrieval captures semantic similarity, while BM25 or lexical retrieval is better for exact product IDs, policy names, error codes, and rare entities. A hybrid system with reranking often beats either alone, especially for Amazon-like catalogs and support documents with many near-duplicate entities.
-
Reranking role: a cross-encoder reranker scores query-document pairs more accurately than vector similarity but is slower and costlier. Use it on a candidate pool, e.g. retrieve top 50–200, rerank to top 5–10, then pass only the most relevant passages to the LLM.
-
Grounding and refusal: good systems explicitly handle “answer not in context.” Measure false-answer rate on unanswerable queries, not just accuracy on answerable ones. The prompt should instruct the model to cite evidence and refuse unsupported claims, but prompt instructions are not a substitute for evaluation.
Worked example
For “Design and evaluate a RAG system,” start by framing the use case: “What corpus are we answering from, how fresh is it, what is the cost of a wrong answer, and do we need citations or just conversational help?” Then declare assumptions, such as a customer-support assistant over policy and troubleshooting documents where correctness and groundedness matter more than creativity. Organize the answer into four pillars: data and query taxonomy, retrieval quality, generation quality, and online experiment design.
For retrieval, say you would build an offline benchmark of real and synthetic queries with gold supporting documents, then track Recall@k, MRR, and coverage by segment. For generation, evaluate answer correctness, faithfulness to retrieved context, citation precision, refusal behavior, and latency/cost per resolved query. A concrete tradeoff to flag is top_k: increasing it may improve recall but can add irrelevant context, raise token cost, and sometimes reduce answer faithfulness. For launch, propose an A/B test against the current experience with primary metrics like successful resolution or accepted answer rate, guardrails like escalation rate and complaint rate, and segmented analysis for long-tail topics. Close by saying that, with more time, you would add error taxonomy reviews: no relevant doc retrieved, relevant doc retrieved but ignored, conflicting docs, stale source, and ambiguous user intent.
A second angle
For “Choose Between Fine-Tuning and RAG for Client Chatbot,” the same concepts apply, but the decision is framed as model adaptation rather than system evaluation. A strong answer says RAG is the default if the chatbot must answer from changing client documents, provide citations, or support auditability. Fine-tuning is more appropriate if the main gap is tone, output schema, intent classification, or domain-specific phrasing. The best answer often combines them: RAG for factual grounding and a lightly fine-tuned or instruction-tuned model for consistent behavior. The evaluation should compare variants on the same labeled query set and include cost per successful resolution, not just model accuracy.
Common pitfalls
Pitfall: Treating RAG as “just add a vector database.”
That answer is too shallow for a Data Scientist interview because it skips measurement. A better answer decomposes performance into retrieval recall, ranking quality, grounding, and end-user outcome metrics, then explains how each would be evaluated and improved.
Pitfall: Optimizing only average answer accuracy.
Average accuracy can hide severe failures on high-risk or low-frequency segments such as policy exceptions, medical/legal disclaimers, seller disputes, or fresh catalog changes. Segment by query type, document domain, language, customer cohort, and answerability; also track worst-case or tail metrics like unsupported-answer rate.
Pitfall: Claiming fine-tuning “teaches the model the knowledge base.”
Fine-tuning can improve format and behavior, but it is unreliable for frequently changing facts and hard to audit. For factual enterprise chatbots, say that RAG provides freshness and traceability, while fine-tuning may complement it for style, routing, or specialized reasoning patterns.
Connections
Interviewers may pivot from here to ranking evaluation, LLM hallucination measurement, A/B testing, semantic search, or transformer attention. They may also ask about RNNs vs. Transformers to check whether you understand why modern retrieval and generation systems rely on attention-based models for long-context language tasks.
Further reading
-
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — the original RAG paper connecting parametric generation with non-parametric retrieval.
-
Dense Passage Retrieval for Open-Domain Question Answering — foundational paper on dense retrieval and passage ranking.
-
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena — useful for understanding strengths and limits of model-based evaluation.
Practice questions

Coding & Algorithms
- Coding Algorithms And Data Structures — covered in depth under Take-home Project below.
Behavioral & Leadership
- Amazon Leadership Principles And STAR Stories — covered in depth under Onsite below.
Onsite
Data Manipulation (SQL/Python)
- SQL Analytical Querying And Data Modeling — covered in depth under Take-home Project below.

What's being tested
This tests analysis-grade data manipulation in pandas and SQL: cleaning messy inputs, joining heterogeneous tables, aggregating by time/customer/product segments, and ranking or deduplicating records correctly. Interviewers are probing whether you can produce trustworthy metric tables under realistic ambiguity: duplicate events, currency normalization, date granularity, missing values, and tie-breaking.
Patterns & templates
-
Groupby aggregation in
pandas:df.groupby(keys).agg(...)for revenue, counts, kWh, or sales totals; validate row grain before aggregating. -
Time bucketing with
pd.to_datetime,.dt.date,.dt.to_period("M"), or SQLDATE_TRUNC; avoid mixing timestamps and dates accidentally. -
Deduplication by business key using
drop_duplicates(subset=..., keep=...)orROW_NUMBER() OVER (...); declare deterministic tie-breakers. -
Join then normalize pattern: merge facts to lookup tables like exchange rates using
merge; check many-to-one assumptions before computing converted metrics. -
Ranking within groups via
rank,sort_values,cumcount, or SQLDENSE_RANK; specify whether ties should share rank. -
Conditional segmentation using
np.where,pd.cut,CASE WHEN, and boolean masks for Prime/non-Prime, price buckets, or customer cohorts. -
Streaming/counting basics for text-like inputs: use
collections.Counteror plaindict; Unicode normalization withunicodedata.normalizeand regex tokenization.
Common pitfalls
Pitfall: Aggregating before fixing grain. If order lines are duplicated or salaries repeat by country/date, totals and ranks become silently wrong.
Pitfall: Treating date joins as exact timestamp joins. Exchange rates, sales days, and meter readings often require explicit date extraction or as-of logic.
Pitfall: Returning code without explaining assumptions. Say how you handle nulls, duplicates, ties, currencies, and timezone/date boundaries.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions
Analytics & Experimentation

What's being tested
Interviewers are probing whether you can design, analyze, and explain online controlled experiments as a Data Scientist, not just run a canned significance test. You need to connect business/product goals to measurable outcomes, choose the right statistical test, check experiment validity, and make a launch recommendation under uncertainty. Amazon cares because small product changes at scale can move conversion_rate, CTR, revenue_per_visitor, delivery promises, or customer trust metrics, and a misleading experiment can cause expensive false launches or missed opportunities. Expect the interviewer to test both mechanics—sample size, confidence intervals, p-values—and judgment: metric selection, guardrails, heterogeneous effects, multiple comparisons, and whether the result is practically meaningful.
Core knowledge
-
Randomized controlled trials estimate causal impact by assigning users, sessions, products, or requests to treatment and control before exposure. For most product experiments, user-level randomization is preferred because it avoids cross-session contamination and supports customer-level metrics like
7_day_conversion_rate. -
Metric design starts with a primary success metric, secondary diagnostic metrics, and guardrail metrics. Example: for a dashboard engagement test, primary could be
weekly_active_users, secondary could bedashboard_sessions_per_user, and guardrails could includelatency_ms,error_rate, unsubscribes, or downstreampurchase_rate. -
Two-proportion z-tests are common for binary outcomes. For control conversion and treatment conversion , the difference is . Under the null, use pooled rate and standard error Then .
-
Confidence intervals communicate estimation uncertainty better than p-values alone. For a binary metric difference, a common large-sample CI is For small counts or rare events, mention Wilson, Agresti-Coull, Fisher’s exact test, or bootstrap as more robust alternatives.
-
Power and sample size depend on baseline rate, minimum detectable effect, significance level, and desired power. For equal-sized two-arm binary tests, approximate per-arm sample size is where is the absolute effect size. Smaller detectable effects require quadratically larger samples.
-
Practical significance is different from statistical significance. At Amazon scale, a 0.03 percentage-point lift may be statistically significant but not worth shipping if it adds operational complexity, harms latency, or degrades a long-term trust metric. Always translate effect size into business/customer impact.
-
Sample ratio mismatch is a validity check before interpreting treatment effects. If a planned 50/50 split produces 41/59 users, run a chi-square check against expected assignment counts. SRM often indicates assignment bugs, logging gaps, bot filtering asymmetry, eligibility mistakes, or exposure leakage.
-
Unit of analysis must match the randomization unit. If randomization is by user but analysis treats page views as independent, p-values will be too small because within-user observations are correlated. Aggregate to user-level metrics or use cluster-robust standard errors when outcomes are repeated or clustered.
-
Multiple testing inflates false positives when checking many metrics, segments, or variants. Bonferroni controls family-wise error with but can be conservative; Benjamini-Hochberg controls false discovery rate. For interviews, say which comparisons were pre-registered versus exploratory.
-
Variance reduction improves sensitivity without increasing traffic. CUPED uses pre-experiment behavior as a covariate: , where is a pre-period metric correlated with the outcome. It is especially useful for noisy continuous metrics like spend, sessions, or engagement time.
-
Heterogeneous treatment effects should be handled carefully. Segment analysis by device, geography, new vs returning users, Prime vs non-Prime, or traffic source can reveal important effects, but these cuts are usually underpowered and subject to multiple comparison risk. Treat them as diagnostics unless pre-specified.
-
Experiment duration should cover business cycles and avoid peeking-driven decisions. A 7-day test captures weekday/weekend behavior, but seasonality, promotions, novelty effects, and delayed conversions may require longer windows. If monitoring continuously, use sequential testing or alpha-spending rather than repeatedly checking naive p-values.
Worked example
For “Analyze an A/B test over last 7 days”, a strong candidate should start by clarifying the randomization unit, intended traffic split, eligibility criteria, primary metric, and whether the 7-day window is complete for delayed outcomes. Then state assumptions: users were randomized before exposure, assignment was stable, and each user is counted once for the primary binary conversion metric. The answer can be organized into four pillars: first, validate the experiment with sample sizes, exposure counts, and sample-ratio mismatch; second, compute treatment and control conversion rates plus absolute and relative lift; third, run statistical inference using a two-proportion z-test and confidence interval; fourth, inspect guardrails and important segments.
A good candidate would explicitly say they would not jump straight to “p < 0.05, ship it” before checking data validity and practical impact. For example, if treatment improves conversion_rate but worsens refund_rate, latency_ms, or customer complaints, the launch recommendation may change. One tradeoff to flag is whether to use all events or user-level aggregation: event-level analysis gives more rows but violates independence if the user is the randomized unit. The candidate should close with a decision framework: launch if the primary metric lift is statistically and practically meaningful, guardrails are neutral, SRM is clean, and effects are directionally consistent across major cohorts. If given more time, they should mention checking novelty effects, delayed conversions, pre-period balance, and whether the result holds under variance-reduced or cluster-robust analysis.
A second angle
For “Calculate A/B sample size, CI, decision rules”, the same ideas appear before the experiment rather than after it. The interviewer is testing whether you can design a test with enough power to detect a business-relevant effect, not reverse-engineer significance once the data arrives. You should ask for baseline conversion rate, minimum detectable effect, desired power, alpha, number of variants, and whether the metric is binary, continuous, ratio-based, or clustered. The framing shifts from “what happened?” to “what evidence will we require to make a decision?” A strong answer includes an explicit decision rule, such as: launch only if the 95% CI excludes zero, the lower bound exceeds the practical threshold, and guardrails remain within acceptable limits.
Common pitfalls
Pitfall: Treating p-value as the probability the null hypothesis is true.
A p-value is the probability of observing data at least as extreme as this result assuming the null is true. It is not , and it does not measure effect size. A stronger answer pairs the p-value with a confidence interval, absolute lift, relative lift, and business impact.
Pitfall: Ignoring experiment validity checks and going straight to inference.
A tempting but weak answer is: “Control converted at 10%, treatment at 11%, p < 0.05, so ship.” Better: first check assignment ratio, exposure logging, duplicate users, bot/internal traffic, pre-period balance, metric denominator consistency, and whether the analysis unit matches randomization. Invalid randomization can make a beautiful confidence interval meaningless.
Pitfall: Overfitting the narrative to segments.
Candidates often slice by country, browser, customer tenure, and device until they find one impressive subgroup. That is exploratory analysis and should be labeled as such. The stronger version is to pre-specify key segments, correct or caveat multiple testing, and recommend follow-up experiments for surprising heterogeneous effects.
Connections
Interviewers may pivot from here to causal inference for non-randomized launches, including difference-in-differences, matching, regression adjustment, or instrumental variables. They may also connect to metric design, ranking/recommender evaluation, sequential testing, CUPED, or anomaly diagnosis when an experiment result conflicts with dashboard trends.
Further reading
-
Trustworthy Online Controlled Experiments by Kohavi, Tang, and Xu — Practical treatment of experiment design, validity threats, metrics, and decision-making in large-scale online platforms.
-
Controlled experiments on the web: survey and practical guide, Kohavi et al. — Seminal paper on online A/B testing pitfalls, ramping, metrics, and organizational practice.
-
Improving the Sensitivity of Online Controlled Experiments by Deng, Xu, Kohavi, and Walker — Introduces CUPED-style variance reduction for online experiments.
Practice questions

What's being tested
Interviewers are probing whether you can turn ambiguous business movement into trustworthy metrics, diagnostic cuts, and clear visual evidence without over-claiming causality. For Amazon Data Scientists, this matters because decisions often depend on operational dashboards, funnel metrics, marketplace balance, recommender quality, or customer experience signals where a small metric shift can represent millions of dollars or degraded customer trust. You are expected to know how visualization tools like `Tableau` affect metric interpretation, but from an analysis layer: joins, filters, level of detail, aggregation grain, and dashboard usability. The strongest answers combine product intuition, statistical discipline, and practical dashboard design: define the metric, validate it, segment it, visualize it, and state what evidence would change your conclusion.
Core knowledge
-
Metric definition comes before visualization. For any decline or dashboard, define numerator, denominator, entity grain, time window, inclusion/exclusion rules, and refresh cadence. For example,
`conversion_rate`= orders / sessions differs materially from`buyer_conversion`= buyers / visitors. -
Metric decomposition is the core root-cause tool. Break aggregate movement into components:
More explicitly:`Revenue`= Visitors × Visit-to-Cart × Cart-to-Checkout × Checkout-to-Order × AOV. -
Segmentation should test plausible mechanisms, not create random slices. Common Amazon-relevant cuts include marketplace, device, acquisition channel, Prime status, new vs returning customers, category, fulfillment speed, seller type, inventory availability, and recommendation surface.
-
Cohort analysis separates mix shifts from behavior changes. Compare users acquired in the same period or exposed to the same experience, then track retention, repeat purchase, defect rate, or revenue over age. This prevents confusing “more new users” with “worse engagement.”
-
Statistical noise matters in root-cause diagnosis. Always ask whether a change is outside historical variance using confidence intervals, control charts, seasonality baselines, or year-over-year comparisons. A 2% drop in a low-volume segment may be noise; a 0.2% drop in checkout can be material.
-
Join grain can create silent metric inflation. In
`Tableau`, a physical JOIN between order-level and item-level data can duplicate rows and inflateSUM(revenue)unless the measure is pre-aggregated or calculated at the correct level. Always identify each table’s primary key before combining data. -
Relationships in
`Tableau`preserve logical tables and defer joins until query time, often reducing duplication risk when tables have different grains. They are usually safer for exploratory dashboards with facts at multiple levels, such as sessions, orders, and shipments. -
Data blending in
`Tableau`is useful when data sources cannot be physically joined, such as a`Snowflake`sales table blended with a`Google Sheets`targets file. But blends aggregate the secondary source before combining, limit row-level calculations, and can behave unexpectedly with filters. -
Filter order of operations affects what users see. In
`Tableau`, extract filters and data source filters happen early, context filters affect dependent filters and level-of-detail calculations, dimension filters happen before measure filters, and table calculations happen late. This is critical for percent-of-total and top-N views. -
Level-of-detail expressions let you control aggregation grain.
`FIXED [customer_id]: SUM([revenue])`computes customer-level revenue independent of most dimension filters unless those filters are in context. Use this when the analysis unit differs from the visualization grain. -
Chart choice should match the analytical task. Use line charts for time trends, histograms for distributions, box plots for spread and outliers, scatterplots for relationships, stacked bars sparingly for composition, heatmaps for two-dimensional intensity, and funnel charts only when stages are ordered and mutually meaningful.
-
Dashboard design should prioritize actionability. A strong operations dashboard has a top-level health metric, supporting drivers, leading indicators, freshness timestamp, alert thresholds, drill-downs by segment, and annotations for launches, outages, holidays, or policy changes.
Worked example
For “Diagnose Business Decline Using Key Data Metrics,” a strong candidate would start by clarifying the metric and context: “What declined: revenue, orders, active users, conversion, or margin? Over what time window, compared with what baseline, and is this localized to a marketplace, platform, or category?” Then they would declare assumptions, such as treating the decline as a weekly revenue drop in an e-commerce marketplace and using both year-over-year and trailing historical baselines to control for seasonality.
The answer skeleton should have four pillars: first, validate the metric pipeline and definition at the analysis level; second, decompose the aggregate metric into traffic, conversion, order value, cancellation/return, and fulfillment components; third, segment by customer, product, channel, geography, and supply-side dimensions; fourth, generate hypotheses and prioritize follow-up analyses by size of impact and reversibility. A concrete decomposition might be `Revenue` = Sessions × Conversion Rate × Average Order Value, followed by stage-level funnel checks such as product detail page views, add-to-cart, checkout start, payment success, and order confirmation.
A key tradeoff to flag is speed versus rigor: an executive diagnostic may need a same-day directional answer, but you should label findings as correlational unless backed by experiment, quasi-experiment, or a clean exogenous event. You might say, “If mobile conversion fell only after a checkout UI launch and desktop stayed flat, that is a high-priority hypothesis, but I would still check traffic mix, inventory availability, and payment error rates before assigning cause.” Close by stating what you would do with more time: build a counterfactual baseline, quantify contribution by segment, review experiment logs or launch calendars, and recommend either rollback, targeted investigation, or an A/B test.
A second angle
For “Choose Between JOIN, BLEND, and RELATIONSHIP in Tableau,” the same discipline appears through metric integrity rather than business diagnosis. The framing changes from “why did the metric move?” to “will this dashboard compute the metric at the right grain?” A strong candidate would ask what each table represents, such as one row per session, order, item, or customer, and whether measures should aggregate before or after combination. If session-level traffic is joined directly to item-level revenue, the chart may show a convincing but wrong conversion rate due to row multiplication. The transferable principle is that visualization is not cosmetic: data modeling choices determine whether the metric is analytically valid.
Common pitfalls
Pitfall: Jumping straight to anecdotes like “maybe competitors lowered prices” without decomposing the metric.
A better answer starts with the metric tree and lets evidence narrow the hypothesis space. External causes can be considered, but only after checking whether the decline is concentrated in traffic, conversion, average order value, supply availability, or post-order defects.
Pitfall: Treating
`Tableau`as a presentation tool only.
In these interviews, `Tableau` questions often test whether you understand aggregation grain, filter order, and dashboard semantics. Saying “I would use a join because it is simpler” is weak; saying “I would use a relationship because orders and shipments have different grains, and I want `Tableau` to aggregate each appropriately before combining” is much stronger.
Pitfall: Overloading dashboards with every possible metric.
An operations dashboard should not be a data dump. A stronger design distinguishes north-star metrics, driver metrics, guardrails, and diagnostic drill-downs, then uses visual hierarchy so the user can detect, localize, and act on anomalies quickly.
Connections
Interviewers can pivot from here into A/B testing, especially whether a diagnosed metric movement should be validated experimentally. They may also move into causal inference, funnel analysis, cohort retention, ranking/recommender evaluation, or anomaly detection using control charts and seasonality-adjusted baselines.
Further reading
-
Storytelling with Data by Cole Nussbaumer Knaflic — Practical guidance on choosing visual encodings and communicating analytical findings clearly.
-
The Visual Display of Quantitative Information by Edward Tufte — Classic reference on graphical integrity, data-ink, and avoiding misleading visuals.
-
Tableau Order of Operations — Essential for understanding how filters, LOD calculations, and table calculations interact.
Practice questions
Statistics & Math

What's being tested
Interviewers are probing whether you can estimate a causal treatment effect when Amazon cannot or did not run a clean randomized experiment. The shared skill is translating a product or policy rollout—reminders, concessions, gift cards, seller programs, customer messaging—into a credible panel-data causal design with explicit identification assumptions. You need to explain not only the estimator, but also why it would or would not recover the effect Amazon cares about: incremental purchases, repeat engagement, defect reduction, concession cost, NPS, or downstream retention. A strong Data Scientist answer shows judgment around treatment definition, comparison group construction, pre-trend diagnostics, heterogeneous effects, and uncertainty.
Core knowledge
-
Difference-in-differences compares outcome changes for treated units versus control units:
The target is usually an average treatment effect on the treated, not necessarily a population-wide launch effect. -
Parallel trends is the central identifying assumption: absent treatment, treated and control units would have experienced the same average outcome trend. It is not testable directly, but you can assess credibility using multiple pre-periods, placebo interventions, business context, and covariate balance.
-
Unit of analysis must match the intervention and decision. A reminder feature may be at
customer_id-week, a seller policy atseller_id-month, and a concession gift-card policy atmarketplace-week ororder_idcohort. Wrong granularity can create spillovers, double counting, or invalid standard errors. -
Panel construction usually means one row per unit-time, including treated and untreated units, treatment timing, outcomes, and pre-treatment covariates. In
SQL, this often involves aggregating events to user-week metrics, joining rollout dates, and filling zero-activity periods so attrition does not masquerade as impact. -
Two-way fixed effects estimates
where absorbs stable unit differences and absorbs common shocks. It is intuitive, but can be biased under staggered adoption with heterogeneous treatment effects. -
Staggered rollout needs extra care because already-treated units can become implicit controls for newly treated units. Prefer event-study estimators or modern group-time approaches such as Callaway-Sant’Anna, Sun-Abraham, or stacked DiD when adoption timing varies and effects evolve over time.
-
Event-study diagnostics estimate leads and lags around treatment:
Pre-treatment lead coefficients should be near zero; post-treatment lags reveal ramp-up, decay, or delayed behavior. -
Matching or weighting can make DiD more credible when treated and control units differ substantially. Propensity score matching, inverse probability weighting, or exact matching on geography, baseline activity, Prime status, seller segment, or pre-period outcome trends can reduce extrapolation, but they do not fix unobserved time-varying confounding.
-
Clustering standard errors matters because observations for the same customer, seller, product, or marketplace over time are correlated. Cluster at the treatment-assignment level when possible; for few clusters, use wild cluster bootstrap or aggregate to the cluster-time level before inference.
-
Spillovers and interference can break DiD. For example, treating some sellers with faster concessions may affect buyer expectations or competing sellers’ demand. If interference is plausible, define larger clusters, exclude exposed controls, or estimate market-level effects rather than individual-level effects.
-
Outcome choice should distinguish short-term behavioral movement from business value. For a reminder intervention, track
open_rate, conversion, incremental orders, revenue, unsubscribes, and long-term retention; for concessions, track defect resolution, gift-card redemption, repeat purchase, concession cost, and customer trust metrics. -
Robustness checks should be planned, not improvised: placebo treatment dates, placebo outcomes that should not move, alternative control groups, alternative time windows, covariate-adjusted specifications, excluding launch week, winsorizing outliers, and checking sensitivity by segment.
Worked example
For “Evaluate concession gift-card policy with DID”, a strong candidate would first clarify the treatment: “Is the policy rolled out by marketplace, customer segment, issue type, or time? What outcome is primary—concession cost, repeat purchase, customer satisfaction, or contact reduction?” They would also ask whether rollout timing was random, capacity-driven, or targeted toward high-defect areas, because targeting creates selection risk.
The answer skeleton should have four pillars. First, define the panel, such as marketplace-week or customer_issue_type-week, with treatment start date, outcomes, and pre-period covariates. Second, propose a DiD or event-study model with unit and calendar-time fixed effects, clustered standard errors, and explicit exclusion of contaminated units if the policy leaked. Third, diagnose assumptions using pre-trends, placebo dates, and balance on baseline concession rate, contact rate, order volume, and defect mix. Fourth, interpret both customer and cost metrics, because a policy may improve retention while increasing concession expense.
A concrete tradeoff to flag: a customer-level panel gives more statistical power and supports segment analysis, but if treatment assignment happened at marketplace or policy-rule level, customer-level clustering without respecting assignment may overstate precision. The close should sound practical: “If I had more time, I would compare a modern staggered-adoption estimator against standard two-way fixed effects and run sensitivity by issue category, because gift-card effects may be large for delivery defects but small for product-quality complaints.”
A second angle
For “Design causal study for reminder impact”, the same framework applies, but treatment exposure is usually more behaviorally ambiguous. A reminder may be assigned, delivered, opened, clicked, or acted upon; the cleanest estimand might be the effect of being eligible for reminders, not the effect among openers, because openers are self-selected. The candidate should define pre-period engagement, seasonality, channel saturation, and opt-out behavior before choosing controls. If reminder rollout was staggered across cohorts, an event study can show whether treated users were already trending upward before the reminder. If the interviewer pushes on compliance, distinguish intent-to-treat from treatment-on-the-treated and explain why the latter needs stronger assumptions or an instrument.
Common pitfalls
Pitfall: Treating “parallel pre-trends look similar” as proof.
Similar-looking pre-trends increase credibility but do not prove identification. A better answer says: “I would use pre-trends, placebo outcomes, and rollout rationale to argue plausibility, while acknowledging that unobserved time-varying shocks—like a local promotion or policy change—could still bias the estimate.”
Pitfall: Jumping straight to the regression without defining the estimand.
A weak answer starts with $Y = \alpha + \beta D + ...$ before saying what means. A stronger answer first states whether the goal is effect on treated customers, effect of rollout eligibility, effect of actual usage, or expected launch impact across all Amazon customers.
Pitfall: Using standard two-way fixed effects mechanically for staggered adoption.
Classic fixed effects can produce misleading weighted averages when treatment effects vary by cohort or time since treatment. Mentioning event-study leads/lags is good; naming the treatment-heterogeneity issue and proposing group-time or stacked estimators shows deeper applied econometrics judgment.
Connections
Interviewers may pivot from DiD into propensity score matching, synthetic control, instrumental variables, double machine learning, or randomized A/B testing as alternative causal strategies. They may also ask how you would operationalize the analysis in SQL or Python, but for a Data Scientist the focus remains on cohort construction, metric validity, assumptions, and interpretation rather than pipeline architecture.
Further reading
-
Mostly Harmless Econometrics — Angrist and Pischke’s applied treatment of DiD, IV, fixed effects, and credible empirical design.
-
Causal Inference: The Mixtape — Practical chapters on DiD, event studies, matching, synthetic control, and modern causal workflows.
-
Difference-in-Differences with Multiple Time Periods — Callaway and Sant’Anna paper explaining why staggered adoption needs group-time treatment effect estimators.
Practice questions

What's being tested
Interviewers are testing whether you can use propensity score matching as part of a credible observational causal study, not just describe it mechanically. For an Amazon Data Scientist, this matters because many decisions involve non-random exposure: customers receive reminders, recommendations, coupons, ads, or seller interventions based on prior behavior, which creates selection bias. The interviewer is probing whether you can define treatment and outcome cleanly, identify confounders, estimate treatment effects under explicit assumptions, diagnose balance, and explain when matching is weaker than alternatives like difference-in-differences or randomized experiments. A strong answer sounds like a causal analysis plan, not a generic ML workflow.
Core knowledge
-
Propensity score is the probability of receiving treatment conditional on observed covariates: . Matching on compresses many covariates into one score, making treated and control units more comparable under the right assumptions.
-
Treatment effect estimands must be named before modeling. ATT estimates impact on treated users, ; ATE estimates impact over the full population. Reminder, coupon, or recommendation analyses often care about ATT because the business asks, “What was the effect on customers who actually received it?”
-
Unconfoundedness means potential outcomes are independent of treatment after conditioning on observed covariates: . This is untestable and is the central weakness of matching; missing drivers like purchase intent, seasonality, or prior reminder eligibility can invalidate the estimate.
-
Common support or overlap requires comparable treated and control units at similar propensity scores: . If high-propensity treated users have no comparable controls, trim them or report that the effect is only identified for the overlap population.
-
Covariate selection should include pre-treatment variables that affect both treatment and outcome, such as prior purchases, browse frequency, tenure, Prime status, device type, geography, prior notification engagement, and baseline spend. Do not control for post-treatment mediators like clicks caused by the reminder.
-
Matching methods include nearest-neighbor matching, caliper matching, exact matching on key strata, Mahalanobis distance within propensity calipers, and matching with or without replacement. A common rule is a caliper of standard deviations of the logit propensity score, though sensitivity checks matter more than blindly applying the rule.
-
Balance diagnostics are more important than predictive accuracy. Use standardized mean difference: and aim for absolute SMD below roughly
0.1after matching. Also inspect propensity score overlap plots and variance ratios. -
Propensity model quality is not judged by
AUCalone. A very highAUCcan indicate treated and control groups are hard to compare, worsening overlap. Logistic regression is interpretable;XGBoostor random forests can capture nonlinear assignment, but still require balance checks. -
Effect estimation after matching usually compares matched outcomes: . Use robust or bootstrap standard errors because matching induces dependence between observations.
-
Weights versus matches are related but not identical. Inverse probability weighting uses weights like for ATE, while matching forms comparable pairs or sets. Weighting can be efficient but unstable when scores are near
0or1. -
Time alignment is critical for DS causal work. Define covariates using only data before treatment exposure, define a clean treatment timestamp, and measure outcomes over a fixed post-period such as
7-day conversion,14-day revenue, orweekly active users. -
Scale considerations matter in implementation but not as data engineering design. For millions of users, estimate scores in
Pythonwithsklearnorstatsmodels, then use approximate nearest-neighbor libraries or stratified matching; for tens of millions, coarsened strata or weighting may be more practical than full pairwise matching.
Worked example
For Design causal study for reminder impact, a strong candidate would start by clarifying: “What reminder are we studying, who was eligible, when was it sent, and what primary outcome matters: purchase_conversion, GMV, repeat_visit, or retention?” They would declare that randomization is preferred, but if the reminder was already deployed non-randomly, they would frame this as an observational causal inference problem.
The answer skeleton should have four pillars. First, define treatment as receiving the reminder during a specific window and define the outcome over a fixed post-treatment horizon. Second, construct pre-treatment covariates capturing baseline customer behavior: prior sessions, purchases, category interest, reminder history, Prime status, tenure, and seasonality indicators. Third, estimate propensity scores and perform matching or weighting while checking common support and covariate balance. Fourth, estimate ATT and run robustness checks such as placebo outcomes, alternative calipers, trimming, and segment-level heterogeneity.
One tradeoff to flag is whether to use propensity score matching alone or combine it with difference-in-differences. If treated users were already trending differently before the reminder, simple matching on static covariates may not remove bias; matching users on baseline features and then applying DiD on pre/post outcomes can be stronger if parallel trends look plausible.
A good close would be: “If I had more time, I would compare this observational estimate against any historical holdout or staggered rollout, because a randomized or quasi-random design would be more credible than relying entirely on selection-on-observables.”
A second angle
For Explain Propensity Score Matching and Assess Covariate Balance, the emphasis shifts from study design to technical diagnostics. You should define the score, explain why matching reduces observed covariate imbalance, and immediately state the assumptions: unconfoundedness, overlap, and correct time ordering. The interviewer may push on how you know matching worked; the right answer is not “the propensity model has high accuracy,” but “post-match SMDs are small, score distributions overlap, and key business covariates are balanced.” You can also mention that if balance remains poor, you would revise covariates, use exact matching on critical dimensions like marketplace or customer segment, change calipers, trim non-overlap, or move to a different design.
Common pitfalls
Pitfall: Treating PSM like a magic bias-removal tool.
The tempting answer is “we match treated and untreated users, then compare outcomes, so we have causality.” That misses the key limitation: matching only adjusts for observed pre-treatment confounders. A better answer explicitly says what unobserved factors could remain, such as customer intent, concurrent promotions, or recommendation ranking changes.
Pitfall: Optimizing the propensity model for prediction instead of balance.
A candidate may emphasize AUC, feature importance, or complex models because that sounds rigorous. For causal matching, predictive performance is secondary; the interviewer wants to hear balance diagnostics, common support, SMD thresholds, and sensitivity checks.
Pitfall: Communicating only formulas without business framing.
It is not enough to write and list assumptions. Tie the method to a real decision: whether reminders incrementally increase purchases, whether the estimate applies only to reachable users, and whether the expected lift justifies expanding the program.
Connections
Interviewers often pivot from propensity score matching to difference-in-differences, synthetic control, instrumental variables, uplift modeling, or double machine learning. They may also ask how your observational estimate compares with an A/B test, especially around selection bias, interference, novelty effects, and metric guardrails.
Further reading
-
Rosenbaum and Rubin, “The Central Role of the Propensity Score in Observational Studies for Causal Effects” — the foundational paper defining propensity scores and their balancing property.
-
Imbens and Rubin, Causal Inference for Statistics, Social, and Biomedical Sciences — rigorous treatment of potential outcomes, matching, weighting, and identification assumptions.
-
Austin, “An Introduction to Propensity Score Methods for Reducing the Effects of Confounding in Observational Studies” — practical guidance on matching choices, balance diagnostics, and applied pitfalls.
Practice questions
Machine Learning

What's being tested
Interviewers are probing whether you can choose, evaluate, and explain supervised learning methods under realistic business constraints: noisy labels, skewed classes, sparse features, correlated predictors, seasonality, and metric tradeoffs. For an Amazon Data Scientist, this matters because many use cases—fraud detection, abuse prevention, conversion modeling, inventory forecasting, search relevance, and customer targeting—require defensible model choices, not just high offline scores. You are expected to reason from the data-generating process, select appropriate algorithms and metrics, identify preprocessing needs, and communicate tradeoffs clearly to product and science partners. The strongest answers connect modeling decisions to customer or business impact, such as false-positive cost, missed-demand cost, latency of decisions, or interpretability needs.
Core knowledge
-
Linear regression estimates coefficients by minimizing squared error: Its classic assumptions include linearity, independent errors, homoscedasticity, no perfect multicollinearity, and exogeneity . Violations do not always make predictions useless, but they affect inference, confidence intervals, and coefficient interpretation.
-
Logistic regression models class probability as and minimizes log loss, not squared error. It is often a strong baseline for tabular classification, especially when interpretability, calibration, and sparse high-dimensional features matter.
-
Regularization controls variance and overfitting by penalizing model complexity. L2 adds and shrinks correlated coefficients smoothly; L1 adds and can produce sparse feature selection; Elastic Net combines both and is useful with correlated feature groups.
-
L0 regularization counts nonzero coefficients, , and directly targets feature subset selection, but exact optimization is generally combinatorial. L∞ regularization constrains the maximum absolute coefficient and is less common in applied DS interviews, but tests whether you understand norm geometry and constraint effects.
-
Feature scaling is essential for distance-based models, gradient-based linear models, and regularized regression because coefficients are penalized relative to feature scale. Tree models such as Random Forests, Gradient Boosted Trees,
`XGBoost`, and`LightGBM`are mostly invariant to monotonic scaling, though transformations can still help with outliers or distribution shape. -
Random Forests reduce variance by bagging many decorrelated trees trained on bootstrap samples and random feature subsets. They are robust, parallelizable, and less sensitive to hyperparameters, but may underperform boosted trees on structured tabular prediction and can struggle with extrapolation beyond observed feature ranges.
-
Gradient Boosting sequentially fits trees to residuals or gradients, reducing bias and often winning on tabular data. Key controls are learning rate, number of trees, max depth, subsampling, column sampling, and early stopping. It can overfit label noise if trees are deep or boosting rounds are excessive.
-
Class imbalance should be handled through metrics, sampling, thresholds, and cost framing. Accuracy is misleading when positives are rare; prefer
precision,recall,F1,PR-AUC, lift, recall at fixed precision, or expected cost. For a 0.1% positive class,ROC-AUCcan look strong while precision is unusable. -
Threshold selection is a business decision layered on top of predicted probabilities. A fraud model might optimize expected value: where is the decision threshold. Always separate model ranking quality from action policy.
-
Calibration matters when probabilities feed downstream decisions, capacity planning, or expected-value calculations. Logistic regression is often reasonably calibrated; boosted trees may need Platt scaling or isotonic regression. Evaluate with calibration curves, Brier score, and observed-vs-predicted rates by score bucket.
-
Time-series forecasting requires respecting temporal order. Use train/validation splits such as rolling-origin evaluation, not random cross-validation. Baselines should include seasonal naive, moving average, and simple exponential smoothing before complex models like
`ARIMA`,`Prophet`,`XGBoost`, or sequence models. -
Feature engineering should encode signal without leakage. For tabular Amazon-style data, common features include lagged demand, rolling means, customer tenure, frequency counts, recency, price bands, categorical target encodings, missingness indicators, and log-transformed monetary values. Compute features using only information available at prediction time.
Tip: In interviews, first state the decision context: “Am I optimizing probability accuracy, ranking quality, forecast accuracy, or a business action threshold?” This prevents generic model comparisons.
Worked example
For Compare Random Forests vs Gradient Boosting rigorously, a strong candidate would start by clarifying the prediction target, data size, feature types, class balance, label noise, interpretability needs, and whether the model is used for ranking, probability estimation, or hard classification. They might say: “I would compare these as two tree-ensemble families: Random Forests primarily reduce variance through bagging, while Gradient Boosted Trees reduce bias through sequential additive learning.” The answer should be organized around four pillars: predictive performance, robustness to noisy or missing data, tuning complexity, and evaluation metrics aligned with the business cost.
For performance, the candidate would explain that boosted trees like `XGBoost` or `LightGBM` often outperform Random Forests on structured tabular data because they iteratively correct errors, but they require careful regularization, learning-rate tuning, and early stopping. For robustness, Random Forests are a safer first pass when labels are noisy or the team needs a stable benchmark with fewer hyperparameters. For feature handling, both can model nonlinearities and interactions, but high-cardinality categoricals may require target encoding, frequency encoding, hashing, or native categorical handling depending on the implementation.
A key tradeoff to flag explicitly is that Gradient Boosting may deliver better PR-AUC or lift in the top score deciles, while Random Forests may be easier to tune and less brittle under distribution shifts. The candidate should also discuss class imbalance: use class weights, balanced sampling, calibrated probabilities, and threshold optimization rather than relying on raw accuracy. A strong close would be: “If I had more time, I’d compare both against a regularized logistic regression baseline, evaluate calibration and segment-level errors, and validate that gains persist on a temporally held-out set.”
A second angle
For Choose Models for Imbalanced Data and Time-Series Forecasting, the same fundamentals apply, but the framing splits into two separate data-generating processes. For the imbalanced classification piece, the central issue is not “which model is most accurate,” but which model ranks rare positives well and supports a defensible action threshold under asymmetric costs. For the forecasting piece, the key constraint is temporal dependence: random splits leak future information and overstate performance. A good answer would compare simple seasonal baselines, `ARIMA`-style models, tree models with lag features, and possibly hierarchical forecasting if predictions aggregate across products, regions, or fulfillment nodes. The transferable skill is matching evaluation design to the operational decision: PR-AUC or recall-at-precision for rare-event detection, and WAPE, sMAPE, pinball loss, or service-level cost for demand forecasts.
Common pitfalls
Pitfall: Treating accuracy as the default classification metric.
This is the most common analytical mistake for imbalanced problems. Saying “the model has 99% accuracy” is weak if the positive class rate is 0.5%; a trivial all-negative classifier gets 99.5% accuracy. A better answer names precision, recall, PR-AUC, top-k lift, calibration, and cost-weighted thresholding.
Pitfall: Reciting model definitions without tying them to data conditions.
A communication mistake is saying “Random Forests are better because they avoid overfitting” or “Gradient Boosting is better because it is more accurate.” Interviewers want conditional reasoning: data size, noise, sparsity, missingness, high-cardinality categoricals, latency constraints, and whether the goal is ranking, calibrated probability, or interpretability.
Pitfall: Ignoring leakage and validation design.
A depth mistake is proposing target encoding, rolling averages, or time-series features without specifying that they must be computed using only past data. For Amazon-style problems with seasonality, promotions, and customer behavior shifts, a random split can make a mediocre model look excellent. Prefer temporal holdouts, grouped splits when entities repeat, and segment-level error checks.
Connections
Interviewers may pivot from here into experiment design, especially how to validate that an offline model improvement translates into an online metric such as conversion, defect rate, or customer contacts. They may also ask about causal inference, ranking metrics like NDCG or MAP, or forecast evaluation under asymmetric costs and stockout penalties.
Further reading
-
The Elements of Statistical Learning — rigorous treatment of regularization, tree ensembles, bias-variance tradeoff, and model assessment.
-
An Introduction to Statistical Learning — accessible coverage of linear models, classification, resampling, feature selection, and tree-based methods.
-
XGBoost: A Scalable Tree Boosting System — foundational paper explaining why regularized gradient-boosted trees became a dominant approach for tabular ML.
Practice questions

What's being tested
Interviewers are probing whether you can design ML decision systems from a Data Scientist’s lens: define the prediction or causal target, choose defensible features and validation, evaluate offline and online impact, and explain tradeoffs under business constraints. The common thread is not “build a model,” but “turn messy behavioral, temporal, or operational data into a reliable decision: recommend this item, forecast this demand, allocate this courier, estimate this treatment effect.” Amazon cares because small errors in ranking, forecasting, churn prediction, and fulfillment allocation compound across millions of customers, packages, and marketplace interactions. A strong answer shows statistical discipline: avoiding leakage, validating temporally, separating prediction from causal claims, and choosing metrics aligned with customer experience and cost.
Core knowledge
-
Problem framing comes first: define the unit of prediction, decision cadence, label horizon, and action. For churn, that may be “probability a subscriber cancels in the next 30 days”; for allocation, “expected service time if courier receives package at time .”
-
Temporal validation is mandatory for forecasting, churn, recommendations, and logistics. Use rolling or forward-chaining splits rather than random splits: train on weeks 1–8, validate on week 9, test on week 10. Random splits leak seasonality, user lifecycle, and future availability.
-
Forecasting panel data combines cross-sectional and time-series signals. For utility consumption, model household/account fixed effects, weather, holidays, lagged usage, rolling means, and seasonality terms such as and . Compare against naive seasonal baselines before complex models.
-
Baseline discipline is a major signal of seniority. For energy demand, include last-week-same-hour or same-month-last-year baselines; for recommendations, popularity and recently viewed items; for churn, logistic regression. If
XGBoostbeats a weak baseline only, the result is not convincing. -
Metric choice should match the decision. Regression may use
MAE,RMSE,WAPE, or pinball loss; ranking may useNDCG@K,MAP@K, recall@K, and diversity; churn usesAUC, precision-recall, calibration, and lift. Cost-sensitive settings require expected value, not just accuracy. -
Calibration matters when predictions drive thresholds or optimization. A churn model with good
AUCcan still overstate risk; use reliability plots, Brier score, or isotonic/Platt calibration. Allocation systems need predicted durations and uncertainty, not only rank order. -
Feature leakage is the most common hidden failure. Examples: using “delivery completed timestamp” to predict package allocation, post-cancellation support contacts to predict churn, or future weather actuals in an energy forecast. Every feature should be available at decision time.
-
Missing data is a signal and a risk. Distinguish MCAR, MAR, and MNAR; add missingness indicators when absence is behaviorally meaningful, impute within training folds, and avoid target-aware imputation. For subscription churn, missing billing or engagement fields may indicate disengagement.
-
Double Machine Learning estimates causal effects with flexible nuisance models while reducing regularization bias. For outcome , treatment , covariates , residualize: and , then estimate Use cross-fitting to avoid overfitting nuisance functions.
-
Text and address-derived features can be useful but risky.
TF-IDF, geohashes, learned embeddings, or parsed address components may proxy for socioeconomic status or geography. Validate representation quality, check overlap/positivity, test sensitivity to feature removal, and discuss fairness or compliance concerns. -
Recommender systems are usually staged: candidate generation, ranking, filtering, and evaluation. A DS should focus on relevance labels, negative sampling, counterfactual bias, offline metrics, segment performance, and experiment design—not low-level serving mechanics. Watch for position bias and popularity bias.
-
Allocation models often combine prediction with optimization. Predict service time, failure probability, or lateness risk, then optimize an objective such as subject to courier capacity, route feasibility, promised delivery windows, and fairness constraints. Evaluate both model error and operational outcomes.
Worked example
For Build a package-allocation model for couriers, start by clarifying the decision: “Are we assigning packages to couriers once per shift, continuously during the day, or at dispatch waves? Is the goal to minimize late deliveries, total route time, cost, or customer promise misses?” Then declare assumptions: each package has location, size, promised delivery window, and historical stop features; each courier has capacity, current route context, region familiarity, and shift constraints.
A strong answer can be organized into four pillars: prediction target, feature design, optimization layer, and evaluation. First, model per-stop service time or lateness probability using historical package-courier-route observations, with features like building type, delivery density, time of day, package size, weather, and courier experience in that area. Second, validate temporally and geographically, because performance on familiar neighborhoods may not generalize to new routes or seasonal peaks.
Third, feed predictions into a constrained assignment objective: minimize expected lateness or total cost while respecting capacity, route duration, promised windows, and workload balance. Fourth, evaluate offline with MAE for service time, calibration for lateness probabilities, and simulated operational metrics such as late-package rate, packages per courier hour, and customer-contact rate. The explicit tradeoff to flag is interpretability versus accuracy: a gradient-boosted model may forecast service time well, but simpler additive effects may be easier to debug when couriers or stations report implausible assignments. Close by saying: “If I had more time, I would add uncertainty-aware allocation, stress-test peak-season cohorts, and run an A/B test against the current dispatch heuristic with guardrails on late deliveries and courier workload.”
A second angle
For Apply Double ML with text-address features, the same discipline applies, but the target is causal rather than predictive. Instead of asking “Can text/address features predict the outcome?”, ask whether they adequately control confounding without violating overlap or encoding problematic proxies. The answer should frame treatment, outcome, covariates, and estimand—usually ATE or CATE—then explain cross-fitting, nuisance models for treatment and outcome, and residual-on-residual estimation. The key difference is evaluation: high predictive accuracy is insufficient; you need balance diagnostics, overlap checks, placebo tests, sensitivity analysis, and confidence intervals. Text embeddings may improve confounding control, but they can also make causal assumptions less transparent.
Common pitfalls
Pitfall: Treating every problem as a pure supervised-learning leaderboard.
A tempting answer is “I’d train XGBoost, tune hyperparameters, and optimize AUC or RMSE.” That misses the business decision. Allocation requires constraints and operational simulation; recommendations require ranking and online behavior; causal questions require identification assumptions, not just prediction.
Pitfall: Communicating a system design answer like an ML engineer.
For a Data Scientist, do not spend most of the answer on Kafka, feature-store plumbing, request fanout, or deployment topology. It is fine to mention that features must be available at decision time, but the stronger discussion is about labels, leakage, validation windows, objective functions, bias, calibration, and experiment design.
Pitfall: Ignoring segment-level and temporal failure modes.
Aggregate metrics can hide failures for new users, rural addresses, peak-season weeks, cold-start items, or high-value customers. A better answer says upfront that you would report metrics by cohort, geography, tenure, traffic source, item category, weather regime, or delivery station, depending on the product.
Connections
Interviewers may pivot from here into experimentation, especially A/B testing recommender or allocation changes with guardrail metrics like cancellation rate, late delivery rate, or customer contacts. They may also probe causal inference, time-series forecasting, ranking evaluation, fairness, or model monitoring from a metric and decision-quality perspective.
Further reading
-
“Double/Debiased Machine Learning for Treatment and Structural Parameters” — Chernozhukov et al., 2018 — foundational paper for residualization, orthogonalization, and cross-fitting in causal ML.
-
“Recommender Systems Handbook” — Ricci, Rokach, and Shapira — broad coverage of ranking, evaluation, cold start, and recommender tradeoffs.
-
“Forecasting: Principles and Practice” — Hyndman and Athanasopoulos — practical reference for baselines, cross-validation, seasonality, and forecast accuracy metrics.
Practice questions
Coding & Algorithms
- Coding Algorithms And Data Structures — covered in depth under Take-home Project below.
Behavioral & Leadership
What's being tested
Amazon behavioral interviews test whether you can turn ambiguous, data-heavy work into customer impact while operating through Leadership Principles, not whether you can recite them. For a Data Scientist, the interviewer is probing how you make decisions under uncertainty, quantify tradeoffs, influence stakeholders, and protect statistical rigor when timelines, incentives, or policies create pressure. Strong answers show ownership of the full analytical outcome: defining the right metric, choosing an appropriate experiment or causal method, communicating risk, and following through after launch. The bar is higher when you can connect behavior to measurable business or customer outcomes such as conversion_rate, NDCG@10, defect_rate, false_positive_rate, latency, or incremental_revenue.
Core knowledge
-
STAR is the baseline structure: Situation, Task, Action, Result. For Amazon, strengthen it with data framing: metric baseline, analytical method, decision made, and quantified impact. A good DS story sounds like “I changed the decision quality,” not just “I helped analyze data.”
-
Leadership Principles mapping matters because interviewers often score multiple principles from one story. A pricing experiment story might show Customer Obsession, Dive Deep, Are Right, A Lot, and Earn Trust if you explain customer harm, diagnosis, statistical reasoning, and stakeholder communication.
-
Customer Obsession for DS means defining the customer-visible outcome before the model or metric. For example, optimizing
CTRalone can degrade customer trust if it increases clickbait; pair it with guardrails likereturn_rate,complaint_rate,long_click_rate, or downstreamretention. -
Dive Deep should include specific analytical moves: cohort cuts, funnel decomposition, counterfactual checks, residual analysis, calibration plots, or sensitivity analysis. Avoid vague “I looked at the data”; say you segmented by marketplace, device, tenure, traffic source, or eligibility rule.
-
Are Right, A Lot is not about always being correct; it is about updating beliefs rationally. Mention uncertainty using confidence intervals, posterior intervals, minimum detectable effect, or power: for a two-arm test with target effect .
-
Ownership means you do not stop at delivering a notebook. Strong stories include follow-up: monitoring launch metrics, documenting assumptions, aligning on an action threshold, creating a repeatable analysis template, or escalating when the data contradicted the desired decision.
-
Invent and Simplify for a DS often means replacing a slow or brittle decision process with a simpler metric, model, or evaluation loop. Examples: simplifying a 40-feature manual review score into a calibrated
LightGBMrisk score, or replacing ad hoc readouts with a standardized experiment scorecard. -
Bias for Action must be balanced with statistical risk. A strong answer says when you shipped a reversible decision with guardrails versus when you delayed for evidence. Use language like “one-way door” vs “two-way door,” and tie it to harm, reversibility, and expected value.
-
Disagree and Commit requires evidence and clear escalation. In DS interviews, a good conflict story includes the competing recommendation, your analysis, the decision owner, and what you did after the decision. If overruled, explain how you monitored
guardrail_metricsand supported execution. -
Earn Trust depends on explaining uncertainty plainly. Say “the experiment was underpowered for marketplace-level effects” or “the model improved
AUCfrom 0.78 to 0.83 but worsened calibration for new users,” then translate what that means for customers or operators. -
Strict policies and ethics are especially important in data work. If asked about rules, privacy, or compliance, emphasize non-negotiables: no inappropriate use of customer data, no p-hacking, no hidden metric cherry-picking, no shipping a biased model without evaluating subgroup error rates.
-
Results should be quantified, but not inflated. Use credible ranges: “reduced manual review volume by 18% at the same precision,” “improved
recall@100by 6.4% offline andadd_to_cart_rateby 1.1% online,” or “prevented a launch that would have increased refunds by an estimated 3%.”
Worked example
For “Answer Behavioral Questions for Amazon Leadership Principles Interview,” a strong candidate first frames the response by asking, “Would you like an example focused on customer impact, technical ambiguity, or stakeholder conflict?” If the interviewer leaves it open, choose a story with a measurable DS decision: for example, an experiment where a ranking change improved engagement but risked degrading purchase quality. In the first 30 seconds, state the context, your role, the decision at stake, and the relevant Leadership Principles: “I’ll use a story that shows Customer Obsession, Dive Deep, and Disagree and Commit.”
Organize the answer around four pillars: first, the customer or business problem; second, the analytical uncertainty; third, your actions; fourth, the measured outcome. In the action section, describe concrete DS work: you redefined the primary metric from CTR to qualified_click_rate, added guardrails like refund_rate and long_click_rate, ran segment-level analysis, and presented confidence intervals rather than a single point estimate. A tradeoff to flag explicitly is speed versus rigor: launching quickly based on aggregate lift could have improved short-term engagement, but subgroup analysis showed new customers had worse downstream conversion. The stronger Amazon-style move is to recommend a staged rollout or narrower launch, not simply “do more analysis.” Close by saying what you institutionalized afterward, such as an experiment review checklist requiring primary, secondary, and guardrail metrics before launch. If you had more time, you would add longer-term retention analysis or a causal follow-up to estimate whether the observed behavior persisted beyond the experiment window.
A second angle
For “Demonstrate leadership under strict rules,” the same behavioral muscle applies, but the constraint is no longer ambiguity alone; it is ambiguity under non-negotiable boundaries. A good DS example might involve pressure to use sensitive customer attributes to improve a fraud, personalization, or eligibility model. The framing should emphasize that policy, privacy, and fairness constraints define the solution space before optimization begins. Instead of saying “I found a workaround,” say you proposed compliant alternatives: proxy-free feature sets, subgroup performance audits, aggregate reporting, or model thresholds reviewed against false_positive_rate and false_negative_rate by allowed cohorts. The close should show both delivery and principle: you achieved a usable model or analysis while protecting customer trust and documenting the decision trail.
Common pitfalls
Pitfall: Giving a generic teamwork story with no analytical stakes.
A weak answer says, “I collaborated with PMs and engineers and we launched successfully.” A stronger DS answer names the metric, the uncertainty, the method, and the decision impact: “I found the apparent 4% lift was driven by returning users, while new-user conversion fell 2%, so we changed the rollout plan.”
Pitfall: Treating Leadership Principles as labels instead of evidence.
Do not say, “This shows Ownership and Dive Deep” without proving it. Show ownership through follow-through, monitoring, and accountability; show dive deep through actual decomposition, validation, and assumptions. Interviewers score behavior, not vocabulary.
Pitfall: Over-indexing on model sophistication.
A tempting mistake is to describe XGBoost, embeddings, or causal forests in detail while ignoring the leadership question. Technical depth helps only when it supports the behavioral point: how you made the right decision, influenced others, protected customers, or simplified a process.
Connections
Interviewers may pivot from these stories into experiment design, metric design, causal inference, model evaluation, or ranking/recommender quality. Prepare at least one story each for conflict, failure, ambiguity, initiative, customer obsession, and ethical judgment, ideally with DS-specific metrics and tradeoffs.
Further reading
-
Working Backwards — explains Amazon mechanisms such as written narratives, customer-backward thinking, and decision discipline.
-
Trustworthy Online Controlled Experiments by Kohavi, Tang, and Xu — useful for DS stories involving A/B testing, guardrails, launch decisions, and statistical rigor.
Practice questions
Take-home Project
Data Manipulation (SQL/Python)
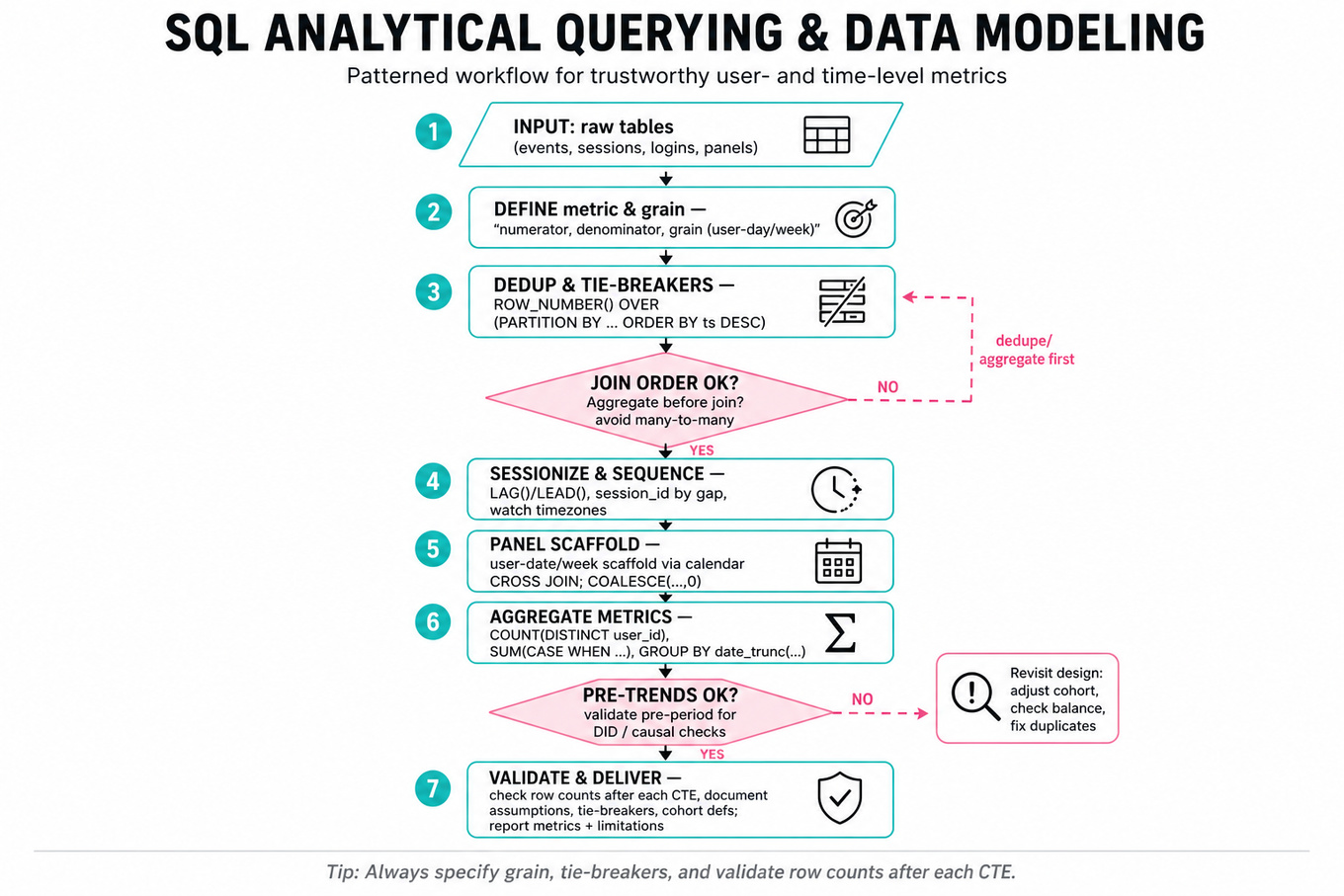
What's being tested
You’re being tested on analytical SQL for product and causal analysis: converting raw event, login, session, and panel tables into trustworthy user-level or time-level metrics. Interviewers look for clean use of joins, deduplication, window functions, temporal logic, and aggregation that supports Data Scientist decisions, not data-pipeline design.
Patterns & templates
-
User/event aggregation with
COUNT(DISTINCT user_id),SUM(CASE WHEN...), andGROUP BY date_trunc(...); define numerator, denominator, and grain first. -
Window functions like
ROW_NUMBER(),LAG(),LEAD(), andRANK() OVER (PARTITION BY ... ORDER BY ...); always specify tie-breakers. -
Session and event sequencing by timestamp using
LAG(event_ts)orLEAD(event_ts); watch time zones, missing events, and duplicate logs. -
Panel construction via user-date or user-week scaffolds using
CROSS JOINcalendar tables; fill missing periods withCOALESCE(..., 0). -
Causal-analysis prep for DID: create
treated,post, and interaction terms; estimate effect as after validating pre-trends. -
Cross-channel attribution using conditional distinct counts and set logic; decide whether users can belong to multiple channels or require mutually exclusive assignment.
-
Efficient large-table SQL: filter early with
WHERE, aggregate before joining, avoid accidental many-to-many joins, and inspect row counts after each CTE.
Common pitfalls
Pitfall: Counting events instead of users. If the metric is user proportion, use
COUNT(DISTINCT user_id), not raw login rows.
Pitfall: Joining before deduplicating. A many-to-many join can silently inflate engagement, hours, or treatment effects.
Pitfall: Treating SQL output as final analysis. For DS work, explain assumptions, metric grain, cohort definitions, and validation checks.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions
Coding & Algorithms
What's being tested
Amazon Data Scientist coding screens test practical algorithm fluency for analysis-heavy tasks: time-series aggregation, streaming summaries, string/window logic, graph dependency reasoning, and simulation in Python. Interviewers look for correct edge-case handling, clean complexity analysis, and code that could support metric debugging or model-evaluation workflows.
Patterns & templates
-
Sliding window for contiguous sequences — use left/right pointers, frequency map,
O(n)time; reset or shrink when constraints break. -
Rolling aggregation for time series — maintain running sum or use
pandas.Series.rolling; define behavior for first six days and missing dates. -
Two-heap median maintenance — max-heap for lower half, min-heap for upper half;
O(log n)insert,O(1)median, rebalance every insert. -
DAG dynamic programming — topological sort with
collections.deque, then relax edges; longest path is valid only because cycles are impossible. -
Synthetic data generation — use
numpy.random, seeded randomness, timestamp generation, and realistic categorical distributions; return tidypandas.DataFrame. -
Complexity narration — state time and space explicitly:
O(n),O(n log n), orO(V + E); explain why the chosen structure matches constraints. -
Input validation — handle empty lists, single records, duplicate timestamps, repeated characters, disconnected graph components, and non-deterministic random seeds.
Common pitfalls
-
Pitfall: Using nested loops for rolling averages or unique substrings when a running sum or sliding window gives linear time.
-
Pitfall: Computing medians by sorting after every insert; acceptable for tiny batches, but not for streaming or interview constraints.
-
Pitfall: Treating synthetic clickstream generation as pure randomness instead of encoding realistic user/session/event relationships and reproducibility via
random_state.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions