Microsoft Software Engineer Interview Prep Guide
Everything Microsoft actually asks Software Engineer candidates — concept walkthroughs, worked examples, and the real interview questions, drawn from candidate reports. Free to read.
Last updated

Technical Screen
Coding & Algorithms
-
Array And String Algorithms — covered in depth under Take-home Project below.
-
Tree And Linked Structure Algorithms — covered in depth under Onsite below.
-
Shortest Path And Graph Traversal — covered in depth under Take-home Project below.
-
Dynamic Programming And Combinatorial Counting — covered in depth under Take-home Project below.
-
Top-K Selection, Heaps, And Ranking — covered in depth under Onsite below.
-
Stateful Data Structures And OOP API Design — covered in depth under Onsite below.
Software Engineering Fundamentals
- Concurrency, Deadlocks, And Synchronization — covered in depth under Onsite below.
System Design
- Scalable Service And Distributed System Design — covered in depth under Onsite below.
Behavioral & Leadership
- Behavioral Leadership And Communication — covered in depth under Onsite below.
Onsite
Coding & Algorithms
- Array And String Algorithms — covered in depth under Take-home Project below.

What's being tested
Microsoft interviewers are probing tree/graph traversal fluency, mutable node-structure design, and the ability to pick the right representation for read/write tradeoffs. You should be able to code clean recursive and iterative traversals, reason about parent pointers and cycles, and explain complexity under dynamic updates.
Patterns & templates
-
DFS traversal templates —
preorder,inorder,postorder; recursive is concise, iterative uses explicitstack; timeO(n), spaceO(h)orO(n). -
BFS / level order — use
queue, process bylevel_size; reverse printing can prepend levels or collect then reverse; timeO(n). -
Lowest common ancestor — BST uses value ordering in
O(h); general binary tree uses postorder recursion returning “found p/q” inO(n). -
Mutable tree API design —
addChild,removeChild,parent,children; guard against duplicate parents, detached subtrees, and accidental cycles. -
Subtree aggregate counts — maintain
subtree_sizeor subordinate counts on ancestor path updates; readO(1), move/updateO(h)unless indexed. -
Serialization/deserialization — encode null markers for binary trees or child counts for generic trees; validate malformed input and preserve traversal order.
-
Dynamic programming for LPS —
dp[i][j]over substring bounds; recurrence depends ons[i] == s[j]; timeO(n^2), spaceO(n^2)or optimized.
Common pitfalls
Pitfall: Treating every tree as a BST. LCA, traversal order, and search complexity change completely without ordering guarantees.
Pitfall: Forgetting cycles in “generic tree” APIs. A mutable node structure can become a graph unless
addChildvalidates ancestry.
Pitfall: Giving only recursive solutions. Interviewers often ask for iterative DFS/BFS to test stack-safety and production readiness.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions
- Shortest Path And Graph Traversal — covered in depth under Take-home Project below.

What's being tested
Top-K selection tests whether you can rank, filter, aggregate, and retain only the best candidates without unnecessary full sorting. Interviewers are probing heap usage, tie-breaking correctness, frequency aggregation, and whether your solution adapts from small arrays to streaming or high-volume workloads.
Patterns & templates
-
Min-heap of size
k— keep current bestkitems inO(n log k)time; compare with full sortO(n log n). -
Custom comparator tuples — encode ranking as
(score, -distance, id)or similar; make tie-breaking explicit and deterministic. -
Hash map plus heap — count with
dict/HashMap, then extract topk; total complexity isO(n + m log k). -
Stable selection — when duplicates or leftmost ties matter, preserve original index in the comparator, e.g.
(value, -index)or(rank, index). -
Weighted aggregation — normalize keys first, accumulate
total_weight[city] += weight, then rank by total and declared tie-break rules. -
SQL ranking template — use
GROUP BY,SUM(weight), filtering inWHERE, thenORDER BY score DESC, distance ASC LIMIT k. -
Streaming workload choice — exact top-K uses counters plus heap; heavy-hitter approximations like Count-Min Sketch trade accuracy for memory.
Common pitfalls
Pitfall: Sorting everything when
kis small misses the expectedO(n log k)optimization and may not scale.
Pitfall: Leaving tie-breaking implicit can fail hidden tests; always state and implement score, distance, index, or lexicographic order rules.
Pitfall: Aggregating before cleaning keys gives wrong winners, especially with inconsistent casing, whitespace, missing fields, or malformed locations.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions
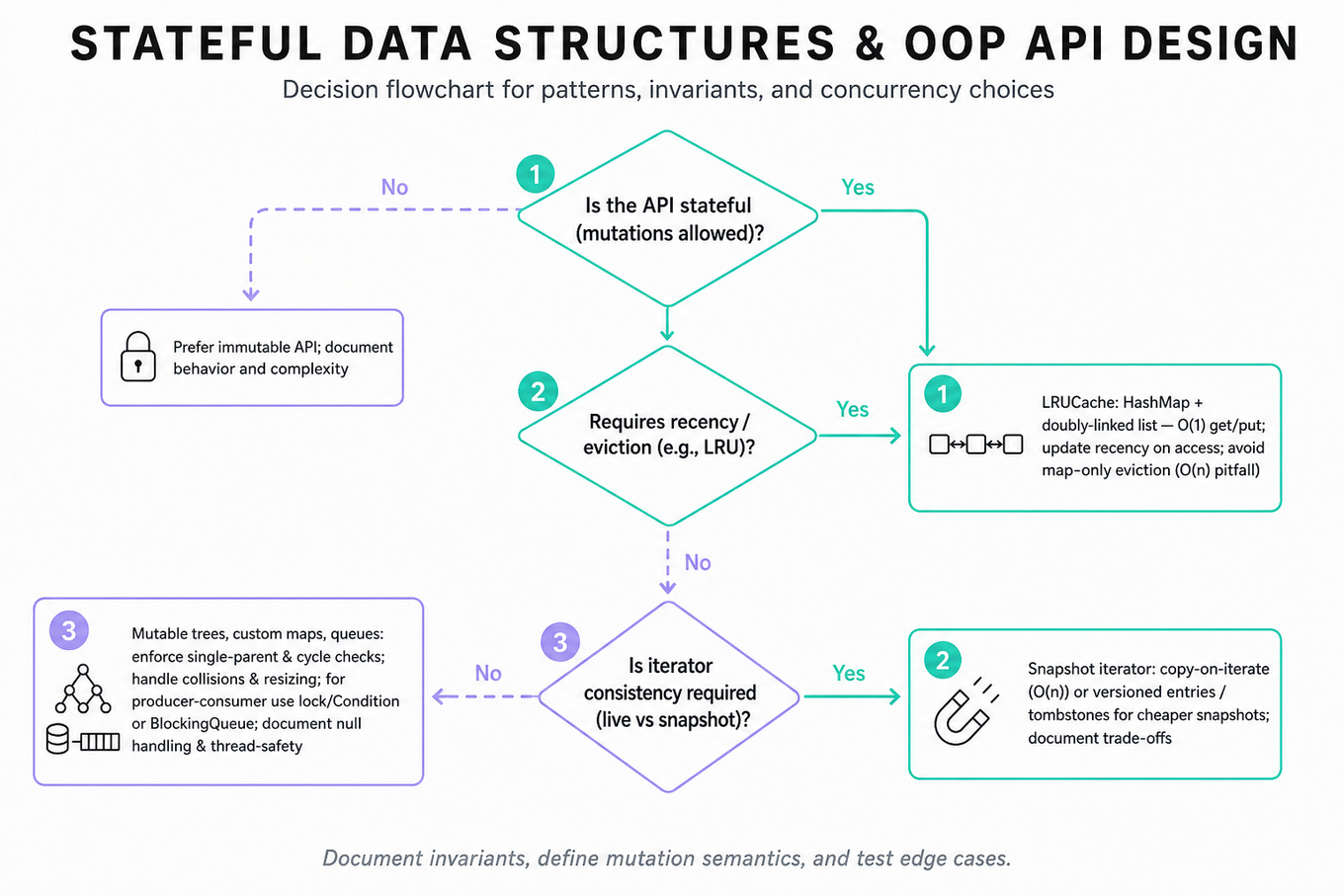
What's being tested
You’re being tested on stateful data structure design: maintaining invariants across mutating operations while exposing a clean, predictable API. Microsoft interviewers are probing whether you can combine OOP modeling, iterator semantics, cache eviction, tree ownership rules, and concurrency-safe queues without losing track of edge cases.
Patterns & templates
-
Hash map + doubly linked list for
LRUCache:get/putinO(1)average time; always update recency after successful access. -
Snapshot iterator via copy-on-iterate or versioned entries: trade
O(n)snapshot cost for simple consistency, or use tombstones for lower upfront cost. -
Mutable tree API with
parent,children,addChild,removeChild: enforce single-parent ownership and reject cycles before mutation. -
Iterator traversal templates: DFS uses a
stack, BFS uses aqueue; define whether traversal reflects live mutations or a fixed snapshot. -
Custom hash map with buckets and resizing: handle collisions, load factor,
hashCode/equals, negative hashes, duplicate keys, and rehashing cost. -
Producer-consumer queue requires clear synchronization: use
lock/Condition,BlockingQueue, or atomic primitives; avoid busy-waiting and missed wakeups. -
API design discipline: separate storage invariants from public methods; document complexity, mutation behavior, null handling, and thread-safety guarantees.
Common pitfalls
Pitfall: Implementing
LRUCachewith only a hash map makes eviction require scanning, turningputintoO(n).
Pitfall: Returning a live iterator over a mutable collection without defining behavior causes skipped elements, duplicates, or concurrent modification bugs.
Pitfall: Tree APIs often forget cycle checks, allowing
node.addChild(ancestor)and corrupting traversal, serialization, and parent pointers.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions
Software Engineering Fundamentals

What's being tested
Interviewers are probing whether you can reason about shared mutable state under real execution interleavings, not just define locks. Microsoft cares because backend services, client runtimes, storage systems, and developer tools all depend on correct behavior under concurrency, where bugs are often rare, nondeterministic, and high-impact. Expect to explain deadlock conditions, choose synchronization primitives, debug producer-consumer code, and design data structures whose invariants survive concurrent reads and writes. Strong answers balance correctness, performance, and maintainability: “this is safe because…” matters more than “I used a mutex.”
Core knowledge
-
Race conditions happen when correctness depends on timing between threads accessing shared state, with at least one write. The fix is not always “add a lock”; it may be immutability, ownership transfer, message passing, atomic operations, or reducing shared state entirely.
-
Critical sections protect invariants, not individual lines of code. For an
`LRUCache`, the map and doubly linked list must be updated under the same synchronization boundary; locking onlyget()map lookup but not list movement can corrupt recency order. -
Mutexes provide mutual exclusion and usually acquire/release memory ordering. Keep lock scope small but complete: acquire before reading shared invariant, update all related fields, release after the invariant is restored. Avoid calling external callbacks or blocking I/O while holding a mutex.
-
Deadlock requires four Coffman conditions: mutual exclusion, hold-and-wait, no preemption, and circular wait. Prevention usually breaks one condition: enforce global lock ordering, acquire all-or-none with timeout, make resources preemptible, or reduce lock granularity.
-
Lock ordering is the most common practical deadlock prevention technique. Assign every lock a rank, e.g.,
`Account.lock`ordered byaccountId, and always acquire lower rank first. This works well until dynamic resource sets require sorting or try-lock rollback. -
Condition variables such as
`std::condition_variable`or Java’sConditionare for waiting until a predicate becomes true. Always wait in a loop:while queue.empty(): wait(). Spurious wakeups and missed notifications are real interview traps. -
Producer-consumer queues require coordinating capacity, emptiness, and shutdown state. A correct bounded queue typically has one mutex,
not_empty,not_full, and aclosedflag so consumers do not block forever after producers exit. -
Atomic operations are appropriate for simple independent state like counters, flags, or reference counts. They are not a magic substitute for locks when multiple variables must change together;
sizeandheadin a queue still need one coherent invariant. -
Reader-writer locks help read-heavy workloads only when read sections are long enough and writes are infrequent. In
`std::shared_mutex`, excessive readers can starve writers depending on implementation policy; for hot paths, consider copy-on-write or snapshotting. -
Consistency models matter in read-heavy designs. For subordinate counts in an org chart, you can provide strong consistency by updating ancestor counts transactionally, or eventual consistency using async recomputation; the right answer depends on read latency, update rate, and correctness requirements.
-
Idempotency is a concurrency-adjacent correctness tool for retries and duplicate requests. A token manager or update API can use an idempotency key and state machine so repeated
renew(token)ordelete(token)calls do not double-apply side effects. -
Performance tradeoffs include contention, lock convoying, cache-line bouncing, and false sharing. A single global lock is often acceptable for small
Nor low`QPS`; for high contention, shard by key, use striped locks, or move to lock-free structures only with strong justification.
Worked example
For “Explain deadlock cases and how to prevent them,” a strong candidate first frames the problem by asking whether the scenario involves threads, processes, database transactions, or distributed services, because prevention mechanisms differ. They would state assumptions: “I’ll discuss in-process locks first, then mention how the same idea maps to transactions and RPCs.” The answer should be organized around three pillars: the four necessary deadlock conditions, a concrete example such as thread A holding `Lock1` while waiting for `Lock2` and thread B doing the reverse, and prevention/detection strategies.
A good skeleton is: define deadlock precisely, identify the resource graph cycle, explain why each Coffman condition holds, then show how to break the cycle. The candidate should call out global lock ordering as the most practical fix for codebases: if every path acquires `UserLock` before `OrgLock`, circular wait is impossible. They should also mention alternatives like try_lock with backoff, timeouts, reducing shared state, or using a single coarser lock if simplicity beats throughput.
One explicit tradeoff: a single coarse-grained lock may eliminate deadlocks and simplify reasoning, but can increase contention and hurt `p99` latency under parallel load. A strong close would be: “If I had more time, I’d add runtime diagnostics: lock-order assertions in debug builds, thread dumps when waits exceed a threshold, and stress tests with randomized scheduling.”
A second angle
For “Implement concurrent structures and debug queue code,” the same principles become code-level invariants rather than verbal definitions. A producer-consumer queue is not correct just because it uses a mutex; the candidate must show the relationship among queue, capacity, not_empty, not_full, and shutdown behavior. The framing is more operational: identify the shared state, decide which lock protects it, and prove each method restores the invariant before releasing the lock. The interviewer may pull on edge cases such as two consumers waking for one item, a producer blocking forever after shutdown, or notifying before updating state. Compared with the deadlock explanation, this tests whether you can translate concurrency theory into safe implementation patterns.
Common pitfalls
Pitfall: Treating
volatileas a synchronization primitive.
In languages like Java, volatile gives visibility and ordering for a variable, but it does not make compound operations atomic, such as count++ or “check then insert.” In C/C++, volatile is generally for memory-mapped I/O and does not provide thread synchronization; use `std::atomic`, mutexes, or language-level concurrency primitives.
Pitfall: Explaining deadlock prevention only as “use fewer locks.”
That answer is directionally reasonable but too shallow. Interviewers want a precise mechanism: global ordering, timeout and rollback, lock hierarchy assertions, or redesigning ownership so only one thread mutates a resource.
Pitfall: Forgetting to communicate invariants.
For concurrent data structures, naming operations is not enough. Say, “The invariant is that every key in `map` has exactly one node in `list`, and both are modified under mu,” then discuss how get, put, eviction, and destruction preserve it.
Connections
Interviewers may pivot from synchronization into memory models, thread-safe data structure design, distributed locking, database isolation levels, or idempotent API design. They may also connect concurrency bugs to debugging skills: reproducing flaky failures, using logs with thread IDs, examining dumps, and stress-testing with randomized interleavings.
Further reading
-
Java Concurrency in Practice — practical coverage of locks, safe publication, thread confinement, and concurrent collections.
-
The Art of Multiprocessor Programming — deeper treatment of lock-free algorithms, consensus, and correctness under concurrency.
-
C++ reference:
`std::condition_variable`— concise reference for correct wait-loop usage and notification semantics.
Practice questions
System Design

What's being tested
These prompts test whether you can turn an ambiguous product capability into a scalable distributed service with clear APIs, data models, storage choices, consistency guarantees, and failure handling. Microsoft interviewers are probing for practical engineering judgment: when to use precomputation, caching, queues, sharding, replication, idempotency, and eventual consistency instead of overbuilding a perfect but unrealistic system. They also want to see whether you can reason from requirements to bottlenecks: read/write ratio, `p99` latency, durability, fanout, freshness, multi-tenant isolation, and operational debuggability. A strong answer is not “use microservices and `Kafka`”; it is a structured tradeoff discussion that makes the system reliable under load and understandable during incidents.
Core knowledge
-
Clarify scale and SLOs first: expected
`QPS`, read/write ratio, data size, freshness,`p50/p95/p99`latency, availability target, and geographic scope. A design for 10K users can use`Postgres`; a design for 100M users needs partitioning, asynchronous processing, and degraded modes. -
Use back-of-the-envelope math to expose bottlenecks. For example, storage/day . A logging service ingesting 1M events/sec at 1KB/event writes about 86TB/day before replication and indexes.
-
Separate write path and read path with CQRS-style thinking when workloads differ. Logging, typeahead, and org-chart counts often need fast ingestion or updates, plus separately optimized query indexes. The write model may be normalized; the read model may be denormalized or pre-aggregated.
-
Choose consistency deliberately. Strong consistency is appropriate for permissions, money, and authoritative org relationships; eventual consistency is usually acceptable for typeahead rankings, notification eligibility, crawler indexes, and log search freshness. State staleness budgets explicitly, e.g. “subordinate counts may lag by 5 seconds.”
-
Precompute expensive aggregates when reads dominate. For org-chart subordinate counts, options include materialized counts on each manager, closure tables, nested sets, or path-prefix encodings. Reads become
`O(1)`or`O(log n)`, while moves and reorgs become more expensive and require transactional care. -
Use queues for smoothing and isolation.
`Kafka`,`Azure Event Hubs`, or`RabbitMQ`decouple producers from consumers, absorb bursts, and enable retries. They do not magically guarantee correctness; consumers still need idempotency keys, checkpointing, dead-letter queues, and replay-safe processing. -
Partition by the access pattern. Typeahead may shard by prefix or term hash; logs often shard by tenant and time; crawlers shard by host/domain to enforce politeness; notifications shard by user ID or scheduled delivery time. Bad partition keys create hot shards and uneven
`p99`. -
Cache only after defining invalidation. Use
`Redis`, CDN edge caches, or in-process caches for hot prefixes, org counts, notification templates, or crawler robots rules. Specify TTLs, write-through versus cache-aside, stampede protection, and what happens when cached data is stale. -
Design for failure as a first-class requirement. Include retries with exponential backoff and jitter, circuit breakers, timeouts, bulkheads, and graceful degradation. For example, typeahead can fall back to popular global suggestions; logging can buffer locally; notifications can retry but must avoid duplicate sends.
-
Indexing drives query feasibility. Prefix search can use tries, finite-state transducers,
`Elasticsearch`completion suggesters, or sorted arrays with range scans. Log search needs inverted indexes plus time partitioning. Org hierarchy queries need ancestor/descendant indexes, not recursive scans over millions of rows. -
Concurrency control matters for mutable state. Org reparenting, notification scheduling, and crawler frontier updates can race. Use optimistic concurrency with version numbers, compare-and-swap, database transactions, or distributed locks sparingly; prefer single-writer partition ownership where possible.
-
Observability is part of the design. Define service metrics such as ingest lag, queue depth, dropped events, duplicate delivery rate, cache hit rate, index freshness, crawl politeness violations, and
`p99`latency. A system that cannot be debugged in production is incomplete.
Worked example
For Design a typeahead search service, a strong candidate starts by asking: “Are suggestions for documents, people, or queries? What is the corpus size? Do we need personalization? What latency target should I optimize for, say `p99 < 100ms`? How fresh must new terms be?” Then they declare reasonable assumptions: hundreds of millions of indexed terms, read-heavy traffic, globally distributed users, and suggestions based on prefix, popularity, and optional user context.
The answer can be organized around four pillars: API design, indexing, ranking, and serving architecture. The API might expose `GET /suggest?q=mic&userId=...&limit=10`, returning suggestion text, type, score, and tracking metadata. For indexing, describe building a prefix index using a trie, sorted term dictionary, or `Elasticsearch` completion suggester, with each prefix mapping to top-K candidate IDs. For ranking, keep the SWE discussion practical: combine popularity, recency, locale, and lightweight personalization features, while leaving deep model architecture out of scope.
The serving architecture should include a low-latency suggestion service, `Redis` or memory caches for hot prefixes, replicated index shards, and an offline or streaming index builder that publishes immutable index segments. A key tradeoff to call out is freshness versus latency: rebuilding compact top-K prefix indexes every few minutes gives fast reads, while real-time updates require delta indexes or write-through updates that add complexity. Close by saying that, with more time, you would cover abuse protection, multilingual tokenization, A/B-safe ranking rollout, and observability metrics like cache hit rate, index age, empty-result rate, and `p99` latency.
A second angle
For Design read-heavy org chart subordinate counts, the same scalable-service principles apply, but the dominant constraint is not low-latency prefix lookup; it is maintaining correct aggregates under hierarchy mutations. A naive recursive traversal for every manager query fails when reads are frequent and subtrees are large, so you would precompute counts or maintain an ancestor-descendant index. Unlike typeahead, freshness and correctness are more sensitive because employees and permissions may depend on reporting lines. The key tradeoff becomes whether to pay update cost during reorgs, using closure-table updates or count propagation, to make reads cheap. You should explicitly discuss concurrency: two simultaneous manager changes must not double-count or orphan employees.
Common pitfalls
Pitfall: Jumping to tools before requirements.
Saying “I’ll use `Kafka`, `Redis`, and `Cosmos DB`” without estimating traffic, latency, or consistency needs sounds shallow. A better answer starts with workload shape, then maps each requirement to a component: queue for burst absorption, cache for hot reads, durable store for source of truth, index for query latency.
Pitfall: Ignoring mutation and backfill paths.
Many candidates design the happy-path read API but forget reorgs, deletes, retries, duplicate messages, schema evolution, or index rebuilds. For logging, that means no plan for late-arriving events or retention; for notifications, duplicate sends; for org charts, corrupted counts after a move. Always describe how data changes, how work is retried, and how the system recovers.
Pitfall: Over-optimizing one dimension while hiding tradeoffs.
A fully precomputed typeahead index is fast but may be stale; strong consistency for every log write may destroy throughput; crawling as fast as possible violates politeness and gets blocked. State the tradeoff explicitly and choose based on product constraints: “I accept 1-minute index freshness to keep `p99` under 50ms.”
Connections
Interviewers can pivot from here into database design, caching strategy, message queues and stream processing, distributed locking, search indexing, or observability and incident response. They may also ask you to zoom into one component, such as designing the crawler frontier, the notification scheduler, a log query index, or a migration plan from a single-node prototype to a sharded service.
Further reading
-
Designing Data-Intensive Applications — best single source for replication, partitioning, indexes, transactions, and stream processing tradeoffs.
-
The Google File System — useful for understanding large-scale storage assumptions, failure handling, and chunk-based distributed design.
-
Dynamo: Amazon’s Highly Available Key-value Store — foundational paper on availability, partitioning, replication, and eventual consistency.
Practice questions
What's being tested
Microsoft system design interviews often probe whether a Software Engineer can build systems that are correct under untrusted clients, shared infrastructure, and fine-grained permissions. The interviewer is looking for practical judgment: how you authenticate callers, authorize actions, isolate tenants, log sensitive operations, and prevent common abuse without overengineering. For services like cloud consoles, image storage, notification systems, and AI APIs, security is not a bolt-on feature; it shapes the API contract, data model, cache keys, request flow, observability, and failure modes. A strong answer shows you can reason about least privilege, scoped access, token lifecycle, and defense in depth while still delivering a scalable service.
Core knowledge
-
Authentication answers “who is calling?” and is usually delegated to an identity provider using OAuth 2.0 and OpenID Connect. In a Microsoft-style environment, expect tokens issued by
Microsoft Entra ID, with claims likesub,tid,aud,iss,exp,scp, androles. -
Authorization answers “is this caller allowed to do this action on this resource?” Model it explicitly as
allow(subject, action, resource, context). Do not rely only on frontend hiding; every backend endpoint must enforce authorization at the service boundary. -
RBAC works well for coarse permissions such as
Owner,Reader, orContributor, but it becomes awkward for resource-specific conditions. ABAC adds attributes like tenant, region, data classification, device trust, or request source, while ACLs are useful for object-level sharing such as image ownership or per-file permissions. -
Tenant isolation must exist in both compute and data paths. At minimum, every row or object should include
tenant_id, every query should filter by it, every cache key should include it, and every async job should carry it. Stronger isolation uses separate databases, storage accounts, keys, or clusters per tenant. -
Authorization enforcement points should be close to the protected resource. A typical pattern is PEP/PDP: the API gateway or service acts as the Policy Enforcement Point, while a policy service such as
Open Policy Agentor an internal authorization service acts as the Policy Decision Point. -
JWT validation is local and fast but easy to get wrong. Validate
iss,aud,exp,nbf, signature algorithm, key IDkid, and token type; cache JWKS keys with TTL; reject unsigned tokens and algorithm confusion. Never treat decoded claims as trustworthy before signature validation. -
Token lifecycle matters for secure APIs. Short-lived access tokens, refresh tokens with rotation, revocation for high-risk events, and scoped tokens reduce blast radius. For upload/download systems, prefer short-lived pre-signed URLs over routing all bytes through the app server.
-
Least privilege should drive scope design. A notification scheduler may need
notifications.sendfor one tenant, not global database access; an image processor needs read/write to a specific object prefix; a Copilot plugin should receive a delegated token scoped to the user’s allowed resources. -
Confused deputy risks appear when Service A uses its broad privileges to access Service B on behalf of a user. Carry user and tenant context through internal calls, distinguish application permissions from delegated permissions, and require downstream services to re-check effective permissions.
-
Audit logging should record security-relevant decisions, not just requests. Include
request_id,actor_id,tenant_id,resource_id,action, decisionallow/deny, policy version, source IP, user agent, and timestamp. Logs must be tamper-resistant and avoid storing secrets or full access tokens. -
Rate limiting and abuse controls should be multi-dimensional: key by
tenant_id,user_id, IP, API key, and endpoint. Token bucket capacity is roughlyburst_size, refill rate isrrequests/sec, and allowed traffic over timetis bounded byburst_size + r t. -
Secure defaults reduce operational mistakes. Deny by default, fail closed for authorization errors, encrypt data at rest and in transit, use envelope encryption with per-tenant keys where appropriate, separate public and private object namespaces, and ensure background jobs cannot bypass policy checks.
Worked example
For Design a Secure Copilot API, a strong candidate would start by clarifying: “Who calls this API — first-party apps, third-party apps, or both? Does the Copilot act on the user’s data, tenant data, or public data? Are responses allowed to contain sensitive enterprise content?” Then they would state assumptions: multi-tenant enterprise customers, Microsoft Entra ID authentication, delegated user access, and strict tenant data isolation.
The answer can be organized around four pillars: request flow, authorization model, data isolation, and abuse mitigation. In the request flow, the client obtains an access token from the identity provider, sends it to the API gateway, the gateway validates token shape and rate limits, and the Copilot service performs resource-level authorization before retrieval or action execution. In the authorization model, distinguish user-delegated actions like “summarize my documents” from app-only actions like “index tenant content,” because the latter needs explicit admin consent and narrower scopes.
For data isolation, every retrieval query, vector search, cache entry, prompt context, and audit event must include tenant_id; otherwise a shared embedding index or response cache can leak data across tenants. A key design decision is whether to use one shared vector index with tenant filters or separate indexes per tenant: shared is cheaper and easier to operate, but separate indexes provide stronger isolation for large or regulated tenants. For threat mitigation, discuss replay protection through TLS, short token TTLs, nonce or request signing for high-risk calls, prompt injection defenses around tool execution, and output filtering for unauthorized content. Close by saying that, with more time, you would add policy versioning, red-team test cases, incident response hooks, and tenant-level compliance controls such as customer-managed keys.
A second angle
For Design a cloud console main page, the same security concepts apply, but the user experience makes authorization more visible. The page should not fetch “all resources then hide forbidden ones”; each backend query should return only resources the user can view, scoped by tenant, subscription, project, or resource group. The design needs fast permission checks because the console may render dozens of widgets, so you can cache effective permissions with short TTLs and invalidate on role changes. Unlike a Copilot API, the main risk is often stale or inconsistent authorization across many microservices: one card may say the user has access while another service denies the click-through. A strong answer emphasizes a consistent policy model, graceful partial rendering, audit logs for administrative actions, and clear handling of cross-tenant account switching.
Common pitfalls
Pitfall: Treating authentication as authorization.
A tempting but weak answer is “the user has a valid JWT, so they can call the API.” A better answer validates the token first, then checks whether the subject has the required action on the specific resource under the current tenant and context.
Pitfall: Ignoring tenant context in caches, queues, and background workers.
Candidates often remember tenant_id in database tables but forget it in Redis keys, CDN paths, object storage prefixes, scheduled notification jobs, or image-processing events. In multi-tenant systems, every async boundary must propagate tenant and actor context, or the system can leak data even if the synchronous API looks correct.
Pitfall: Communicating security as a checklist instead of a request flow.
Saying “use encryption, RBAC, rate limiting, logging” sounds generic. It lands better to walk one concrete request end to end: token issuance, gateway validation, service-level policy check, data access with tenant filter, response redaction, audit event, and failure behavior.
Connections
Interviewers may pivot from this area into API gateway design, distributed caching, object storage security, rate limiting, audit log pipelines, or zero-trust service-to-service communication. For AI-flavored systems, expect follow-ups on secure retrieval, prompt injection, tool permissions, and preventing cross-tenant leakage through caches or embeddings.
Further reading
-
OWASP API Security Top 10 — practical taxonomy of broken object-level authorization, excessive data exposure, token misuse, and abuse patterns.
-
NIST SP 800-63B: Digital Identity Guidelines — authoritative guidance on authentication, session management, authenticators, and token handling.
-
Google BeyondCorp: A New Approach to Enterprise Security — foundational zero-trust model useful for reasoning about internal service access and device/user context.
Practice questions
Behavioral & Leadership
What's being tested
Microsoft behavioral interviews for Software Engineers test whether you can turn messy engineering work into clear, credible stories about ownership, technical judgment, and collaboration. The interviewer is probing how you handle ambiguity, disagree on designs, communicate risk, mentor others, and connect engineering decisions to user or business impact without drifting into product strategy. Microsoft cares because SWEs often work across large codebases, partner teams, legacy systems, and staged launches where correctness is not just “write the code,” but align stakeholders, manage tradeoffs, and learn quickly. Strong answers show a repeatable decision process: clarify constraints, evaluate options, communicate transparently, deliver, and reflect.
Core knowledge
-
STAR-L is the safest behavioral structure: Situation, Task, Action, Result, and Learning. Keep Situation/Task under 25% of the answer; spend most time on your concrete engineering actions and measurable results.
-
Scope calibration matters. For SWE stories, describe your level-appropriate ownership: implemented service endpoints, led a migration plan, wrote design docs, debugged production issues, mentored teammates, or coordinated with partner teams. Avoid claiming PM-style ownership of roadmap strategy unless you made engineering tradeoffs.
-
Impact metrics should be engineering-specific and quantified where possible: reduced
`p99`latency from420msto180ms, cut deployment rollback rate from8%to2%, improved error budget burn, reduced cloud cost by30%, or shortened build time from45minto12min. -
Ambiguity handling starts with constraints. A strong answer names unknowns such as traffic volume, backward compatibility, data consistency, SLA/SLO targets, team capacity, migration deadline, and operational risk. Then it explains how you converted uncertainty into assumptions, experiments, or staged decisions.
-
Design conflict resolution should sound technical, not political. Compare options using explicit criteria: latency, availability, maintainability, migration risk, developer productivity, security, and reversibility. For example, choosing synchronous RPC over an async queue may reduce complexity but increase tail-latency coupling.
-
Staged rollout is a key SWE leadership pattern. Mention
`feature flags`, canary deployments, ring-based rollout, dark launches, kill switches, and dashboards for`p50/p95/p99`, error rate, saturation, and rollback triggers. This shows you reduce blast radius rather than “launch and hope.” -
Risk management is strongest when tied to failure modes. For a migration, discuss dual writes, read shadowing, backfills, consistency checks, versioned APIs, idempotent retries, and rollback plans. You do not need to over-architect, but you should show operational foresight.
-
Communication artifacts make leadership concrete. Name design docs, RFCs, architecture decision records, incident postmortems, pull request summaries, release notes, and weekly status updates. Interviewers trust stories more when communication left durable artifacts others could review.
-
Conflict stories should include empathy and escalation boundaries. A good pattern is: restate the other engineer’s concern, identify shared goals, run a small benchmark or prototype, decide with agreed criteria, and escalate only when blocked by ownership or risk.
-
Proudest project answers need technical depth. Include the hard part: concurrency bug, API compatibility, database hot partition, frontend rendering bottleneck, dependency migration, flaky tests, or production incident. “I coordinated everyone” is weaker than “I identified the bottleneck, proposed two designs, and drove implementation.”
-
Why Microsoft should connect your motivation to engineering scale and craft:
`Azure`, developer tools, productivity platforms, accessibility, security, distributed systems, or AI-assisted engineering. The best version links your past work to a Microsoft domain without sounding generic. -
Availability/logistics questions still test professionalism. Be concise, accurate, and flexible: start date, relocation, work authorization, competing timelines, and constraints. Do not over-explain; treat logistics as part of clear stakeholder communication.
Worked example
For “Describe handling ambiguity and resolving design conflicts,” a strong candidate would first frame the story in the first 30 seconds: “I’ll use a backend migration where the goal was clear, but the target architecture, rollout plan, and ownership boundaries were not.” They would clarify the stakes: production traffic, compatibility requirements, error budget, timeline, and who disagreed about the design. The answer skeleton should have four pillars: how they identified unknowns, how they compared design options, how they aligned stakeholders, and how they delivered safely.
For example, they might explain that one engineer wanted a full rewrite while another preferred incremental migration; the candidate proposed a design doc comparing both against `p99` latency, rollback complexity, code ownership, and migration duration. They could describe building a small prototype or load test to replace opinion with evidence. A specific tradeoff to flag: an incremental path may temporarily duplicate logic and increase maintenance cost, but it lowers launch risk and enables rollback through `feature flags`. They should also explain communication: weekly check-ins, decision log, and explicit sign-off from service owners before expanding rollout. The result should be measurable, such as zero customer-facing incidents, reduced latency, or completing migration ahead of a dependency deprecation. They should close with reflection: “If I had more time, I would have automated more validation earlier and documented the migration checklist so future teams could reuse it.”
A second angle
For “Introduce yourself and explain ‘Why us?’,” the same leadership concept appears, but the framing is compressed and motivational rather than incident-based. You still need a throughline: what engineering problems you have worked on, what strengths you bring, and why Microsoft is a credible next step. A strong answer might say, “My background is backend systems and developer productivity; I’ve repeatedly worked on reliability and migration projects, and I’m excited by Microsoft because products like `Azure` and developer platforms operate at a scale where those skills matter.” The constraint is time: do not give a chronological autobiography. Lead with your current identity as an engineer, support it with one or two proof points, then connect to Microsoft’s technical environment and growth culture.
Common pitfalls
Pitfall: Treating ambiguity as “I asked my manager what to do.”
That answer makes you sound dependent rather than resourceful. A better version is: “I clarified success criteria with my manager, then proposed options with risks, recommended a path, and validated it with a prototype or rollout plan.” Show that you seek alignment without outsourcing judgment.
Pitfall: Describing conflict as a personality issue.
Avoid “the other engineer was stubborn” or “I convinced them I was right.” Microsoft interviewers look for collaborative problem solving, especially across teams. Say what technical concern each side had, what evidence changed the discussion, and how the final decision balanced tradeoffs.
Pitfall: Giving a polished story with no engineering depth.
A vague answer like “I led a project that improved performance and worked with stakeholders” is not enough. Add the hard technical detail: what was slow, how you measured it, what alternatives you considered, what broke in testing, and how you knew the final system was safer or better.
Connections
Interviewers can pivot from behavioral leadership into system design, debugging, incident response, code quality, or project execution under constraints. Be ready to zoom from a leadership story into technical specifics: architecture diagram, failure mode, rollout plan, API contract, test strategy, or performance bottleneck.
Further reading
-
Crucial Conversations — practical framework for high-stakes disagreement without becoming defensive or vague.
-
The Staff Engineer’s Path by Tanya Reilly — useful for understanding technical leadership behaviors even below staff level.
-
Designing Data-Intensive Applications by Martin Kleppmann — strengthens the technical tradeoff vocabulary behind migration, reliability, and distributed-system stories.
Practice questions
Take-home Project
Coding & Algorithms

What's being tested
These problems test linear array/string scanning, pointer discipline, and choosing the right optimization pattern instead of brute force. Expect to recognize monotonic stacks, sliding windows, interval sorting, bounded-range extrema, and in-place partitioning, then explain correctness and O(n) or O(n log n) complexity clearly.
Patterns & templates
-
Monotonic stack for next-smaller-or-equal discounts —
O(n)time, stack of candidate indices; watch equality semantics and rightward-only constraints. -
Sliding window for shortest constrained substring — expand right, update counts, contract left while valid;
O(n)with a frequency map. -
Bounded max/min window using deque — maintain candidates in decreasing/increasing order; expire indices outside window before computing profit.
-
Interval merge template — sort by start, track current
[start,end], merge whennext.start <= current.end; costsO(n log n). -
Dutch National Flag partitioning — three pointers
low,mid,high; sort three categories in-place inO(n)time andO(1)space. -
Invariant-first coding — state what each pointer/stack/deque represents before writing loops; this prevents off-by-one and stale-index bugs.
-
Complexity tradeoff — hash maps and stacks usually give
O(n)extra space; interval sorting dominates unless input is already sorted.
Common pitfalls
Pitfall: Treating “smaller” as strictly smaller when the discount rule requires smaller-or-equal changes answers on duplicate prices.
Pitfall: Shrinking a sliding window only once per right pointer often misses the shortest valid substring; contract in a
whileloop.
Pitfall: In three-way partitioning, incrementing
midafter swapping withhighskips an unclassified element.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions

What's being tested
These problems test graph modeling, shortest-path selection, and traversal correctness under different input shapes: grids, directed trees, weighted graphs, and path-reconstruction strings. Interviewers are checking whether you choose the right traversal primitive—BFS, Dijkstra, DFS/Union-Find, or topological-style reconstruction—and can justify complexity and edge cases.
Patterns & templates
-
Multi-source BFS for nearest-distance grids — initialize
queuewith all gates, expand level by level;O(mn)time,O(mn)space. -
Dijkstra’s algorithm for non-negative weighted graphs — adjacency list plus min-heap
priority_queue;O((V+E) log V)time. -
Directed tree validation — track
parent[node], detect two-parent violations, then run cycle detection with DFS or Union-Find. -
Path reconstruction from labeled edges — build
start_tag -> fragment, identify unique source, walk links; detect missing links, branches, and cycles. -
Preprocessing for repeated queries — sort/prefix arrays for budget queries, then binary search via
bisect_left/upper_bound; avoid per-query scans. -
Graph representation choice — use adjacency lists for sparse graphs, matrices only for dense or tiny graphs; clarify directed vs undirected edges.
-
Shortest-path gotchas — BFS only works for unit weights; use Dijkstra for positive weights and Bellman-Ford only if negative edges are possible.
Common pitfalls
Pitfall: Using DFS to compute shortest distance in an unweighted grid; BFS is the correct tool because it explores by distance layers.
Pitfall: Marking nodes visited too early in Dijkstra; skip stale heap entries by checking
if dist > best[node]: continue.
Pitfall: Solving the “extra directed edge” as only cycle detection; a valid rooted tree also requires exactly one parent per non-root node.
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions

What's being tested
These problems test dynamic programming state design, combinatorial counting, and recognizing when a faster mathematical or search-based formulation replaces naive DP. Microsoft interviewers are probing whether you can derive recurrences, prove correctness, handle large constraints, and explain O(...) tradeoffs clearly.
Patterns & templates
-
1D/2D DP recurrence design — define
dp[i]ordp[i][j], base cases, transition order, and memory compression when only prior states matter. -
String segmentation DP —
dp[i] = any(dp[j] && s[j:i] in dict); optimize with Trie, rolling hash, or max-word-length pruning. -
Interval DP for palindromes — longest palindromic subsequence uses
dp[l][r]; fill by increasing substring length,O(n^2)time and space. -
Binary search on answer — for load balancing or capacity minimization, test feasibility greedily in
O(n), givingO(n log sum)instead of exponential partitioning. -
Combinatorial divisor counting — transform equations algebraically, factorize
N, then count divisors using prime exponents: if , divisors are . -
Knapsack-style feasibility — distinguish true 0/1 knapsack DP from monotonic feasibility problems where sorting, prefix sums, or binary search is enough.
-
Correctness proof template — state invariant, show base case, prove transition/greedy feasibility, then bound time and memory before coding.
Common pitfalls
Pitfall: Jumping to DP without checking monotonicity; many “minimize maximum load” problems are cleaner with binary search plus greedy feasibility.
Pitfall: Counting ordered pairs when the problem asks unordered pairs, or missing symmetry cases like
x == y.
Pitfall: Building
s[j:i]substrings inside nested loops in languages where slicing copies; this can silently turnO(n^2)intoO(n^3).
Practice these
The practice cards below cover the canonical variants — solve all of them and time yourself.
Practice questions